はじめに
Numenta NuPICは、新皮質で発生する個人による情報の保存プロセスをモデル化するアルゴリズムのオープンな実装です。 githubのNuPICソースコード
一言で言えば、NuPICの目的は、「データの空間的および時間的パターンをくずし、明らかにし、記憶し、予測する」と言えます。 これは、人間の脳がほとんどの場合に行うことです-記憶し、要約し、予測します。 これらのプロセスの非常に良い説明は、Jeff Hawkinsの本「In Intelligence」にあります(「About Intelligence」という本のロシア語訳があります)。
Numentaの Webサイトには、アルゴリズムと操作の原理を詳述した詳細なドキュメントと、いくつかのビデオがあります。
組み立てと設置
リポジトリのreadmeファイルに記述されているため、詳細は説明しません。 nupicを使用するには、ヘッダーファイルとともにpython2.7(または2.6)が必要です。
モデルのパラメーターと構造
nupicの重要な概念は新皮質モデル(または単に-モデル)です。これは、入力データを処理および保存するセルのセットです。 入力データを処理する過程で、セルはイベントの発生の可能性を予測し、将来の予測を自動的に形成します。 これがどのように行われるかについては、次の記事で説明しますが、ここでは最も必要なことの一般的な説明のみを示します。
モデルはいくつかのプロセスで構成され、それぞれの動作は一連のパラメーターによって決定されます。
エンコーダー
入力データはエンコーダーを通過し、モデルの明確なビューに変換されます。 各セルはバイナリデータのみを認識し、作業のために、値が近いデータは同様のバイナリ表現を持つ必要があります。
たとえば、モデル入力で、1〜100の間隔(現在の相対湿度など)から数値を入力します。 数値のバイナリ表現を使用する場合、値7と8は近くにありますが、バイナリ表現は大きく異なります(0b0111と0b1000)。 これを回避するために、エンコーダは数値を単位ビットのセットに変換し、値に比例してシフトします。 たとえば、1〜10の値の範囲と3単位ビットの場合、次の表現が得られます。
- 1-> 111000000000
- 2-> 011100000000
- 3-> 001110000000
- 7-> 000000111000
- 10-> 000000000111
入力に複数の値がある場合、それらのバイナリ表現は単純に結合されます。
同様に、浮動小数点値と値の離散セット(true / false、およびその他の列挙型)が表されます。
空間プーラー
SPの主なタスクは、同様のデータセットに近いセルセットを確実にアクティブ化し、このアクティブ化にランダム性の要素を追加することです。 これがどのように行われるかの詳細な議論は、記事の範囲を超えています;興味のある人は、継続を待つか、元のソースを参照できます(ホワイトペーパー)。
テンポラルプーラー
入力データの同様のパターンを識別することに加えて、NuPICは時間の経過に伴うフローを分析することにより、このデータのコンテキストを区別できます。 これは、セルの多層セット(いわゆるセル列)によって実現され、詳細な説明も意図したフレームワークを超えています。 ここでは、これがないと、システムはシーケンスABCABCの文字BをCBACBAの同じ文字と区別しません。
練習:サイン
十分な理論で、問題の実際的な側面に移りましょう。 開始するには、単純な正弦関数を取得し、それをモデルの入力に入力して、モデルがどの程度理解して予測できるかを確認します。
完全なサンプルコード 、キーポイントを分析します。
一連のパラメーターを使用してモデルを作成するには、ModelFactoryクラスを使用します。
from nupic.frameworks.opf.modelfactory import ModelFactory model = ModelFactory.create(model_params.MODEL_PARAMS) model.enableInference({'predictedField': 'y'})
MODEL_PARAMSは、モデルパラメータの完全なセットを備えたかなり緩やかな辞書です。 現在、すべてのパラメーターに関心があるわけではありませんが、いくつか停止する価値があります。
'sensorParams': { 'encoders': { 'y': { 'fieldname': u'y', 'n': 100, 'name': u'y', 'type': 'ScalarEncoder', 'minval': -1.0, 'maxval': 1.0, 'w': 21 }, },
ここで、エンコーダ値を設定できます。これにより、サイン値(-1〜1の範囲)がビット表現に変換されます。 値minvalとmaxvalが範囲を決定し、値nが結果のビットの総数を決定し、w-単位ビットの数を決定します(何らかの理由で奇数でなければなりません)。 したがって、範囲全体は0.025のステップで79の間隔に分割されます。 確認するだけで十分です。
残りのパラメータはまだ変更する必要はありません-それらの多くがありますが、デフォルト値は非常にうまく機能します。 ワイプペーパーを読んで、数か月間コードを掘り出した後でも、いくつかのオプションの正確な目的は謎のままです。
モデルのenableInferenceメソッドの呼び出しは、どの入力パラメーターを予測するかを示します(1つだけにすることができます)。
準備が完了したら、モデルにデータを入力できます。 これは次のように行われます。
res = model.run({'y': y})
引数はdictであり、すべての入力値をリストします。 出力では、モデルは入力データのコピー(元の表現とエンコードされた表現の両方)と次のステップの予測を含むオブジェクトを返します。 私たちが最も興味を持っているのは、推論フィールドの予測です。
{'encodings': [array([ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], dtype=float32)], 'multiStepBestPredictions': {1: 0.2638645383168643}, 'multiStepPredictions': {1: {0.17879642297981466: 0.0083312500347378464, 0.20791169081775931: 0.0083320832430621525, 0.224951054343865: 0.020831041503470333, 0.24192189559966773: 0.054163124704840825, 0.2638645383168643: 0.90834250051388887}},
複数のステップを一度に予測できるため、multiStepPredictionsディクショナリでは、キーは予測ステップの数であり、値はキーの予測と値の確率を持つ別の辞書です。 上記の例では、モデルは90.83%の確率で0.26386の値、5.4%の確率で0.2419の値などを予測します。
最も可能性の高い予測は、multiStepBestPredictionsフィールドです。
こうした知識をすべて備えて、単純なサインを予測しようとしています。 プログラム実行のグラフを開始パラメーターとともに以下に示します。 上のグラフの青い線は元のサイン、緑はモデルを1ステップ左にシフトした予測です。 下のグラフでは、360個の値の標準誤差が戻っています(全期間)。
最初は、エラーは非常に大きく、予測値は元の値と著しく異なります(sin-predictor.py -s 100):
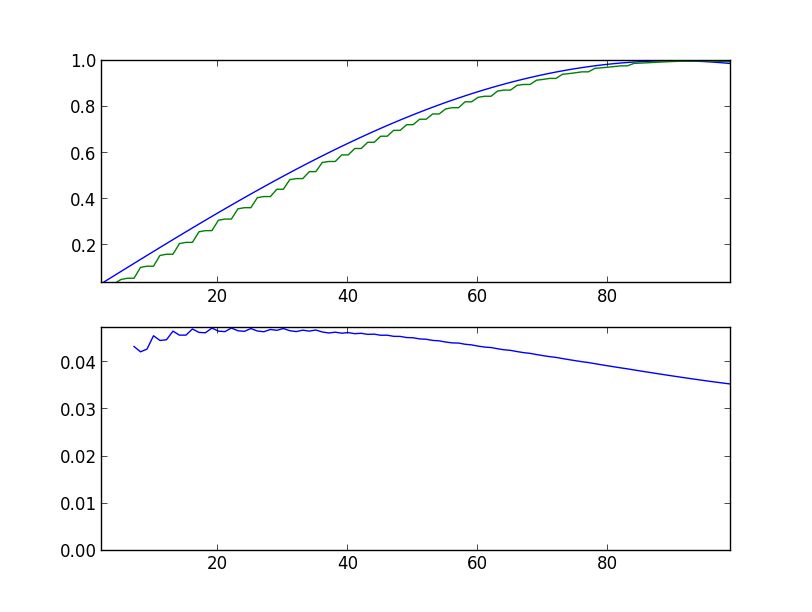
1000ステップ後:
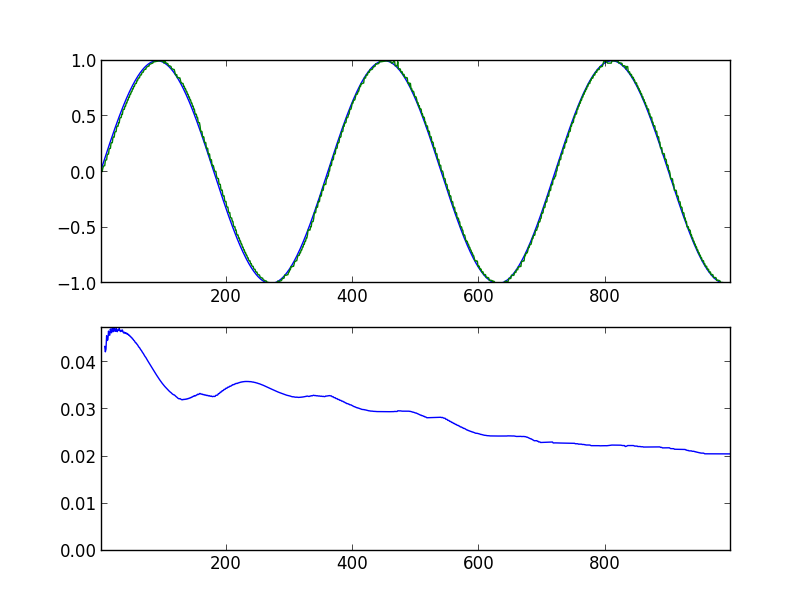
進歩は明らかです。 10,000ステップ後:
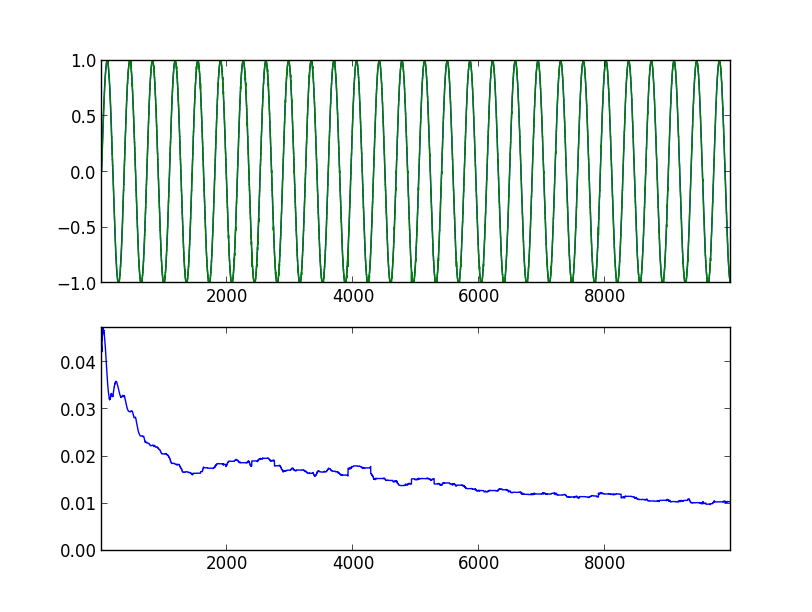
10,000ステップ後、最後の360個の値:
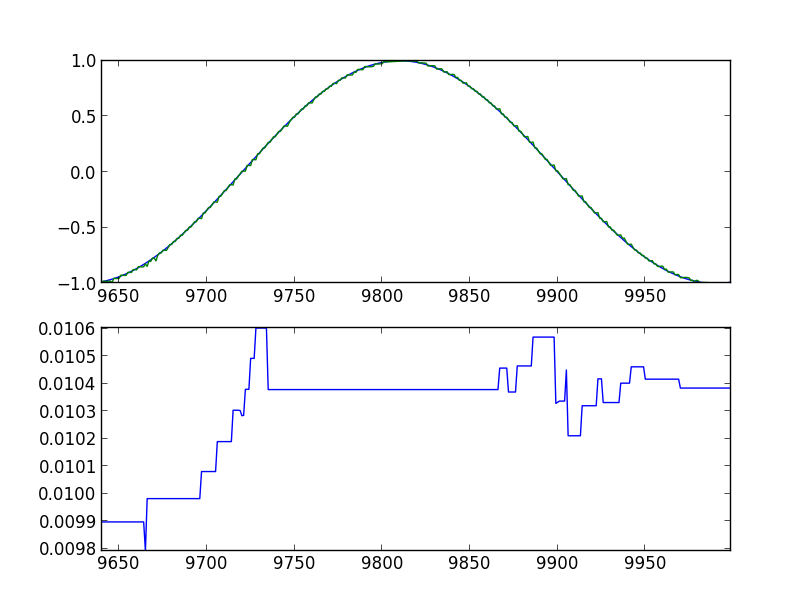
モデルは、彼らがそれから何を望んでいるかについて、確かにいくつかのアイデアを得たことがわかります。
おわりに
この記事では、実装の詳細のジャングルに入らずにNuPICを使用する方法の最も一般的なアイデアを提供しようとしました。 ネットワークの構造、視覚化システム、脳、群れなど、多くのことが舞台裏に残っています。 トピックに時間と関心があれば、記事を続けることができます。