HBaseを使用した経験、つまりバルクロードについてお話ししたいと思います。 これは別のデータ読み込み方法です。 通常のアプローチ(クライアントを介してテーブルに書き込む)とは根本的に異なります。 バルクロードの助けを借りて、大量のデータを非常に迅速にロードできるという意見があります。 これが私が理解しようと決めたものです。
そして、まず最初に。 バルクロードによるロードは、3段階で行われます。
- データファイルをHDFSに配置します
- MapReduceタスクを開始します。これは、ソースデータをHFile形式のファイルに直接変換するため、HBaseはそのデータをそのようなファイルに保存します。
- HBaseテーブルの受信ファイルを埋める(バインドする)バルクロード機能を開始します。
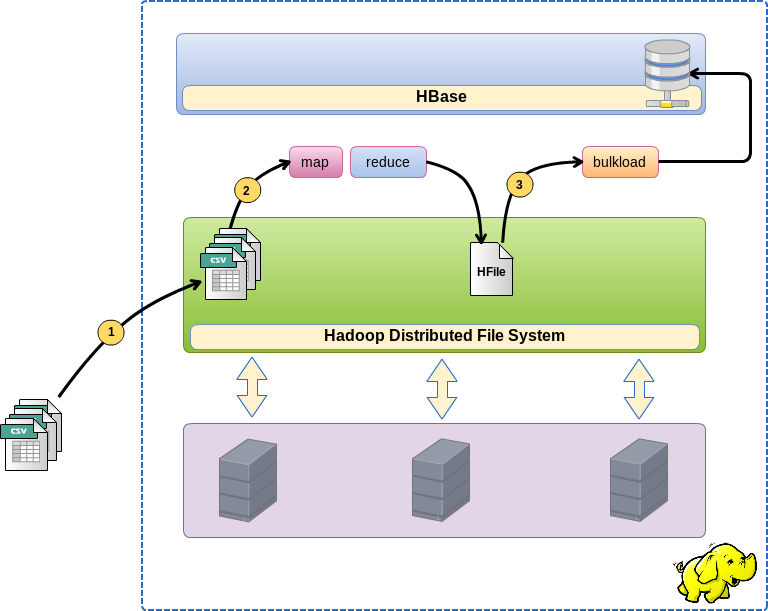
この場合、私はこの技術を感じ、数字でそれを理解する必要がありました。速度はどれくらいで、ファイルの数とサイズにどのように依存しますか。 これらの数値は外部条件に依存しすぎていますが、通常のロードとバルクロードの順序を理解するのに役立ちます。
ソースデータ:
Cloudera CDH4、HBase 0.94.6-cdh4.3.0によって管理されるクラスター。
CentOS / 4CPU / RAM 8GB / HDD 50GB構成の3つの仮想ホスト(ハイパーバイザー上)
テストデータは、合計サイズが2GB、3.5GB、7.1GB、14.2GBのさまざまなサイズのCSVファイルに保存されました
最初に結果について:
バルクロード
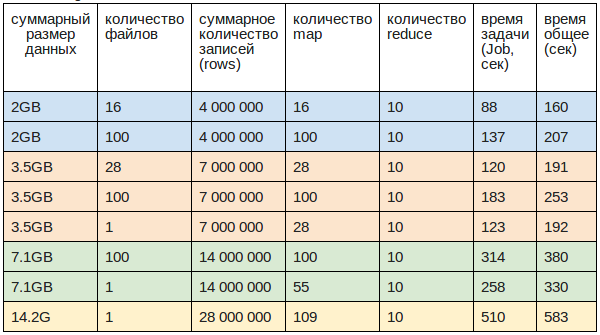
速度:
- 最大29.2 Mb /秒または58K rec /秒(28ファイルで3.5GB)
- 平均27 Mb /秒または54K rec /秒(現実に近い作業速度)
- 最小14.5 Mb /秒または29K rec /秒(100ファイルで2 GB)
- 1ファイルのアップロードが100より20%高速
1レコード(行)のサイズ:0.5Kb
MapReduceジョブの初期化時間:70秒
ローカルファイルシステムからHDFSのファイルのダウンロード時間:
- 3.5GB / 1ファイル-65秒
- 7.5GB / 100-150秒
- 14.2G / 1ファイル-285秒
クライアントからダウンロード:
ダウンロードは、それぞれ8つのスレッドを持つ2つのホストから実行されました。
クライアントは同時にクラウンで起動し、CPU負荷は40%を超えませんでした
前のケースと同様に、1つのレコード(行)のサイズは0.5Kbでした。
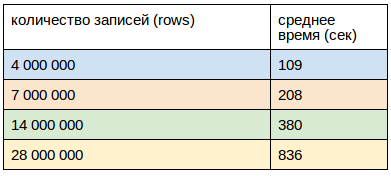
結果は何ですか?
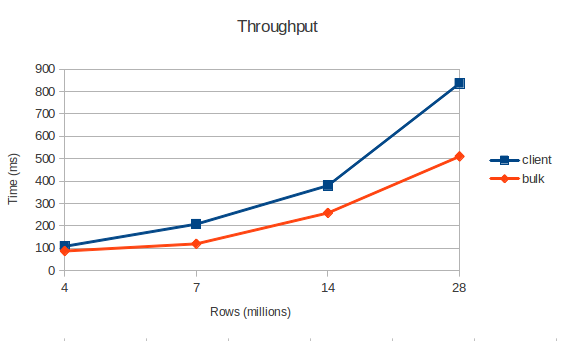
超高速のデータ読み込みの方法として、バルク読み込みについての話をきっかけにこのテストを実装することにしました。 公式ドキュメントでは、ネットワークとCPUの負荷を軽減することについてのみ言及していると言っておく価値があります。 それがそうであっても、私は速度の向上を見ていません。 テストによると、バルクロードは1.5倍しか高速ではありませんが、m / rジョブの初期化を考慮に入れないことを忘れないでください。 また、データはHDFSに配信する必要があり、時間がかかります。
データをロードするもう1つの方法としてバルクロードを扱うだけの価値があると思いますが、アーキテクチャが異なります(場合によっては非常に便利です)。
そして今、実装のために
理論的には、すべてが非常に単純ですが、実際にはいくつかの技術的なニュアンスがあります。
// Job job = new Job(configuration, JOB_NAME); job.setJarByClass(BulkLoadJob.class); job.setMapOutputKeyClass(ImmutableBytesWritable.class); job.setMapOutputValueClass(Put.class); job.setMapperClass(DataMapper.class); job.setNumReduceTasks(0); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(HFileOutputFormat.class); FileInputFormat.setInputPaths(job, inputPath); HFileOutputFormat.setOutputPath(job, new Path(outputPath)); HTable dataTable = new HTable(jobConfiguration, TABLE_NAME); HFileOutputFormat.configureIncrementalLoad(job, dataTable); // ControlledJob controlledJob = new ControlledJob( job, null ); JobControl jobController = new JobControl(JOB_NAME); jobController.addJob(controlledJob); Thread thread = new Thread(jobController); thread.start(); . . . // output setFullPermissions(JOB_OUTPUT_PATH); // bulk-load LoadIncrementalHFiles loader = new LoadIncrementalHFiles(jobConfiguration); loader.doBulkLoad( new Path(JOB_OUTPUT_PATH), dataTable );
- MapReduce Jobは、起動されたユーザーに代わって出力ファイルを作成します。
- バルクロードは常にhbaseユーザーの代わりに開始されるため、準備されたファイルを読み取ることができず、次の例外でクラッシュします: org.apache.hadoop.security.AccessControlException:Permission denied:user = hbase
したがって、hbaseユーザーの代わりにJobを実行するか、出力ファイルに権限を与える必要があります(これはまさに私がやったことです)。
- HBaseテーブルを正しく作成する必要があります。 デフォルトでは、1つのリージョンで作成されます。 これにより、1つのレデューサーのみが作成され、記録は1つのノードのみに送られ、100%ロードされ、他のノードは喫煙します。
したがって、新しいテーブルを作成するときは、事前に分割する必要があります。 私の場合、テーブルはクラスター全体に均一に散在する10のリージョンに分割されました。
// - HTableDescriptor descriptor = new HTableDescriptor( Bytes.toBytes(tableName) ); descriptor.addFamily( new HColumnDescriptor(Constants.COLUMN_FAMILY_NAME) ); HBaseAdmin admin = new HBaseAdmin(config); byte[] startKey = new byte[16]; Arrays.fill(startKey, (byte) 0); byte[] endKey = new byte[16]; Arrays.fill(endKey, (byte)255); admin.createTable(descriptor, startKey, endKey, REGIONS_COUNT); admin.close();
- MapReduce Jobは出力ディレクトリに書き込みますが、これを彼に伝えますが、同時に列ファミリと同じ名前のサブディレクトリを作成します。 そこにファイルが作成されます。
一般に、それですべてです。 これはやや粗雑なテストであり、トリッキーな最適化は行われないと言いたいので、何か追加することがあれば、喜んで聞きます。
すべてのプロジェクトコードはGitHubで入手できます: github.com/2anikulin/hbase-bulk-load