インターネットから情報を取得するのに何とか時間がかかりました。 適切なサイトを見つけて、デバイスページを調べました。 wgetをダウンロードするすべての人の目には多くのことが隠されていることがわかりました。 HTTrackの標準アセンブリも役に立ちませんでした。 Scrapy用のスパイダーを作成したかったのですが、信頼性と拡張性の感覚は得られませんでした。 私は考え始め、自転車を発明するか、ウェブクローラーを書くようになりました。
インターネット上でサイトをダウンロードするためのツールの開発に関するさまざまな記事を見つけましたが、実際のタスクではなく、例にのみ許可される制限のために、私はそれらが好きではありませんでした。 主なものは2つだけです。 まず、すべての種類のページの分析を事前に予測する必要があります。 第二に、情報はほとんどの場合一度にアンロードされ、エラーの場合は再び開始されます。
以前の工芸品をしばらく忘れ、脇に置き、すべての注意を建築に集中しました。この記事は恥ずかしくなく、Habréに投稿されます。
ストーリーを簡素化するために、「InCr」という名前が選ばれました。これは、Intellectual Crawlerの略であり、Incredible(信じられない)という言葉の始まりでもあります。
InKrは、タスクの管理、ドキュメントのダウンロードと保存のための基本的な機能を実装するプラットフォームでなければなりません。 開発者側からは、特定のサイト用のパーサーを作成する必要があります。 分析中に、次の基本要件が策定されました。
1.ダウンロードを柔軟に構成する機能:スレッド数の制限、認証のための処理の一時停止、キャプチャの認識など。
2.ページの読み込みとその解析の独立性、以前にダウンロードしたページの再解析の可能性。
3.パーサー開発プロセスのサポート:完全に解析できなかったすべてのドキュメントは個別にマークされます。
4.複数のページの情報に基づいて取得したデータを補足する機能。
5.停止後のページの読み込みプロセスの継続。
6.変更の正しい処理。
7.複数のサイトと一連のルールを同時に処理します。
タスクとして、フォーラムから情報をダウンロードして解析することを検討してください。 明確にするために、これをphpBBフォーラムwww.phpbb.com/communityとします。 ユーザー、フォーラム、トピック、投稿に興味がある。 新しいメッセージやトピックのダウンロード、および非表示のセクションを表示するための承認のために提供する必要があります。 分析自体に問題はありませんが、新しいサイトのロードを実装する場合、これは開発者の努力に限定されるべきです。
たぶん今、あなたは私が無意味なことをしていると思うでしょう、なぜならそのような決定と記事はすでに存在しているからです。 コメントや個人的なメッセージでそれらについて教えていただければ幸いです。
さらに記事では、提案されているInKraアーキテクチャと実装パスについて説明します。 既成のソリューションがない場合は、次の記事でコメントを考慮して実装自体を説明します。
InKreでは、次のメインモジュール(機能ブロック)を区別します。
1.準備(初期化、I):認証、Cookieの受信、キャプチャの認識、DNSレコードのキャッシュなどを担当します。
2.ダウンロード(ダウンロード、D):特定のページをダウンロードします。
3.チェック(チェック、C):ページサイズ、タイムアウト、404エラーなどの正しい読み込みをチェックします。
4.解析(Parse、P):ルールに従ってページを解析します。
5.抽出(E):場合によっては追加のディレクトリとデータを使用して、解析されたページからデータを取得します。
6.更新(U、U):データベースのデータを更新します。
7.モニタリング(モニタリング、M):他のモジュールのデータ処理、ロギング、現在のステータスに関する情報の提供。
この図は、モジュールが相互作用する主な方法をまとめたものです。
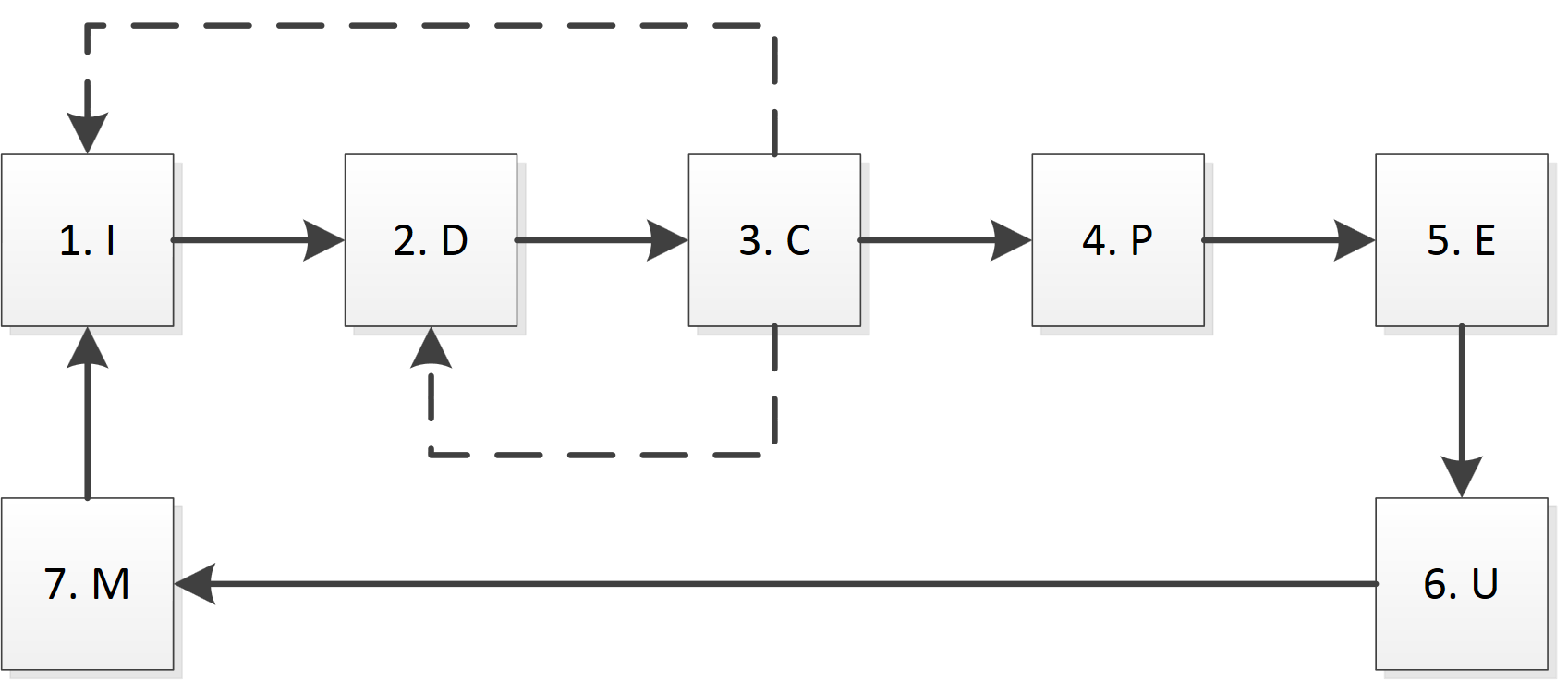
最初と3番目のブロックの重要性を強調したいと思います。 準備ユニット(I)では、特定のサーバーでの作業を開始するために必要なすべての操作と、「非標準」ページの処理が実行されます。 データを含むページを受信する前に、ポートノッキングを実行し、特定のページ(または画像)をロードしてCookieを受信し、そのページにアクセスしたことを証明する必要があります(キャプチャ、セキュリティの質問)。 また、特定のサーバーのスレッドとキューを定義および作成します。 実際、このモジュールは、ダウンロードの一時停止と、エラーの原因を取り除いた後の再開について決定を下すことができます。 システム内では、たとえば、再認証によりセッションがリセットされる可能性があるため、このブロックはサイトごとに1つである必要があります。
検証モジュールは、特定のページが正しく読み込まれていることを迅速に評価するために必要です。 やがてダウンロードブロック(D)の直後に動作しますが、多くの場合、各サイトに個別の実装があります。 正しいページは、サイトが承認エラー、認証の必要性、しばらくしてから再試行する、適切なページが見つからないなどを報告する可能性があるため、必要なものがあることを意味しません。 認識基準として、短縮構文解析モジュール(P)を使用できますが、エラーメッセージの処理方法を学ぶ必要もあります。
解析ユニット(P)と抽出ユニット(E)も互いに分離されています。 この理由は、解析の目的はページを分析してデータのフラグメントを抽出することであり、抽出では既にデータが特定のオブジェクトにバインドされているためです。 解析はHTMLレベルで機能し、特定のページに制限されています。また、抽出ユニットはすでにデータを処理しており、以前にロードされたページの情報を使用できます。
更新ブロック(U)では、データを結合する必要があるためタスクが複雑になり、異なる数のフィールドを含めることができ、特定の時点でのみ正しくなる可能性があります。
制御モジュール(M)の目的は、現在のステータスと操作を実行するプロセスに関する情報を取得するだけでなく、障害を特定し、任意の段階から再起動することもできます。 たとえば、パーサーの最初のバージョンを作成し、その助けを借りてphpBBフォーラムを正常にダウンロードしました。 その後、ポーリングトピックがあることが判明したため、パーサーを変更して、既にダウンロードされているすべてのページの解析を再開するだけで十分です。
InKrの最初のバージョンについては、機能が上記のものに匹敵する既製のソリューションがあることが判明しない場合、次の記事で説明します。
あなたのコメントを歓迎します。
アーキテクチャの欠陥とは何ですか? 何を調整する必要がありますか? 潜在的な問題の出現をどこで感じますか?