
Intel Parallel Studio XEパッケージは、HabréのIntelブログでの出版物を含め、開発者に長い間知られています。 最近、アップデートが発表されました-Intel Parallel Studio XE 2013 Service Pack 1(SP1)には、多くの興味深い革新があります。 OpenMP 4.0標準(部分)のサポートのおかげで、コプロセッサーと統合グラフィックスのプログラミングが容易になっています。 エラーの検索がより柔軟になり、プロセスの完了前にメモリリークが検出されるようになりました。 長期にわたるサービスや「落下」アプリケーションで探すことができます。 新しいコールツリービュー、オーバーヘッドの見積もり、および並列設計に関する詳細情報により、パフォーマンスのボトルネックを簡単に見つけることができます。
Intel Composer XEは、C / C ++およびFortranコンパイラ、マルチスレッド、数学、その他のライブラリを組み合わせています。 Intel Composer XE 2013 SP1には多くの改善点があります。ここでは、OpenMP * 4.0標準に登場したベクトル化機能とコプロセッサーとアクセラレーターの使用に焦点を当てます。
OpenMP * SIMDデザイン
SIMD(単一命令複数データ)命令またはベクトル化を使用すると、データの並列処理が可能になります。 これは、ソフトウェアのパフォーマンスを最適化する最も効果的な方法の1つです。 インテル®コンパイラーは、コードを自動的にベクトル化するために可能なすべてのことを行いますが、たとえば依存関係の可能性が疑われる場合、これは常に可能とは限りません。 OpenMP 4.0標準では、依存関係がなく、「#pragma omp simd」コンストラクトを使用してベクトル化できることをコンパイラーに明示的に伝えることができます(Fortranにも類似しています)。 ループの前に「omp simd」がある場合、コンパイラは複数の反復を同時に処理できるベクトル命令を生成する必要があります。 たとえば、「削減」のために追加の構造を使用できます。
double pi() { double pi = 0.0; double t; #pragma omp simd private(t) reduction(+:pi) for (i=0; i<count; i++) { t = (double)((i+0.5)/count); pi += 4.0/(1.0+t*t); } pi /= count return pi; }
開発者が個々のデータ要素に対して実行される操作を記述する「要素ごとの」SIMD関数を定義できます。 同時に、コンパイラーは、関数がSIMDサイクルで安全に使用できることを知っています。 SIMD関数を定義するには、omp declareコンストラクトが使用されます。
#pragma omp declare simd notinbranch float min(float a, float b) { return a < b ? a : b; } #pragma omp declare simd notinbrach float distsq(float x, float y) { return (x - y) * (x - y); }
このようなことにより、単一のコア内でデータ並列処理(SIMD)を組み合わせたり、複数のコアで実行されるスレッド並列処理やタスクを実行したりできます。 次のループは最初にベクトル化され、その後、異なるスレッドで残りの反復回数を実行できます。
#pragma omp parallel for simd for (i=0; i<N; i++) d[i] = min(distsq(a[i], b[i]), c[i]);
コプロセッサーを使用する
Intel Xeon Phiなどのアクセラレータとコプロセッサが人気を集めています。 OpenMP 4.0では、「omp target」を使用して、コプロセッサーに計算を送信できます(これは十分に並列です)。 この設計は、それに続くアクセラレータコードブロックを起動します。 サポートされていない場合、またはサポートされていない場合、コードはCPUで通常モードで動作します。 「マップ」設計により、コプロセッサーに送信されるデータを整理できます。
#pragma omp target map(to(b:count)) map(to(c,d)) map(from(a:count)) { #pragma omp parallel for for (i=0; i<count; i++) a[i] = b[i] * c + d; }
Intel Advisor XEは、パラレルシリアルコードの実行をシミュレートします。 並列アルゴリズムのプロトタイプを作成するために使用され、アーキテクトは、実装にかなりのリソースが費やされる前に、さまざまな設計オプションをすばやく試す機会を与えます。 その結果、プログラムの実行とスケーラビリティの加速が予測され、並列バージョンで表示される可能性のある競合データが示されます。
高度な加速およびスケーラビリティ分析
以前は、スケーラビリティの評価は2〜32コアで行われていました。 これは通常CPUには十分でしたが、240を超えるハードウェアスレッドを備えたIntel Xeon Phiコプロセッサーには十分ではありませんでした。 Advisor XEの新しいバージョンでは、無制限の数のコアに対するアルゴリズムのスケーラビリティを評価します。 次の図は、512コアの例を示しています。 これで、スレッドの数の観点から、アルゴリズムがインテルXeon Phiに移植する準備ができている量を評価できます(Advisor XEがまだ実行していないコードの「ベクトル化可能性」、メモリ制限なども評価する必要があります)。
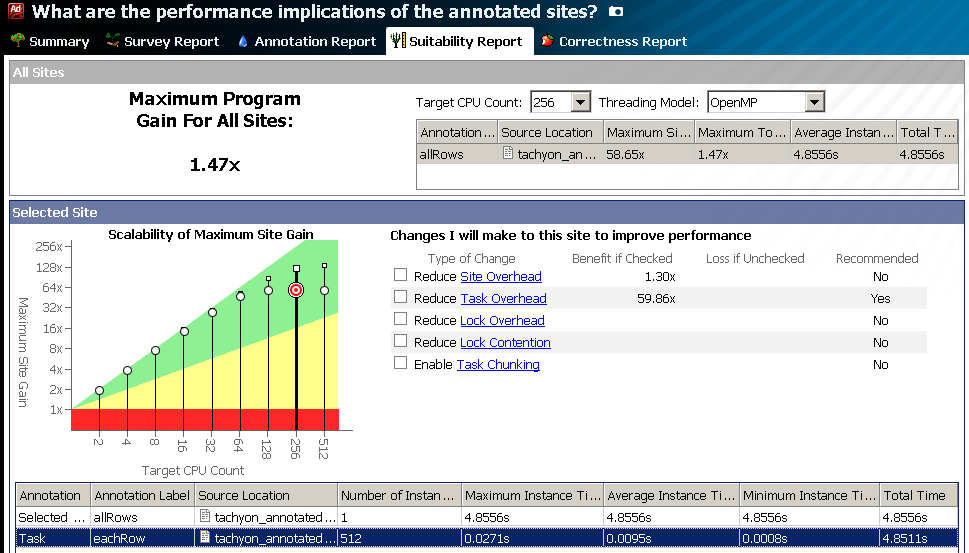
実験のコピー(実験スナップショット)
Inspector XEおよびVTune Amplifier XEのユーザーは、多くのテストを行ってすべての結果を保存し、パフォーマンスの変化と問題のステータスを追跡することができます。 最近まで、Advisor XEはそのような機会を奪われていました-プロファイルの構造の複雑さと現在のバージョンのコードとの密接な関係のため、最後の実験の結果のみが保存されていました。
Parallel Studio XE 2013 SP1に同梱されているIntel Advisor XE 2013アップデート4には、実験のコピー(スナップショット)を作成する機能があります。 このコピーは読み取り専用ですが、以前のバージョンのコードのパフォーマンス評価を確認し、現在のバージョンと比較できます。


コードの個々のセクションの分析
アドバイザXE分析は、かなりのオーバーヘッドを追加できます。 「リアルタイム」での並列実行の複雑なモデリングが実行されます。 時間を節約するために、分析が必要なコードの個々のセクションをマークできるようになりました。 さらに、このような「ナローイング」は、プログラムの他の部分の影響を排除することにより、分析の精度を高めることができます。 これはすべて、新しいタイプの「注釈」:ANNOTATE_DISABLE_COLLECTION_PUSHおよびANNOTATE_DISABLE_COLLECTION_POP(手動制御用のボタンがあります)によって実装されます。
int main(int argc, char* argv[]) { ANNOTATE_DISABLE_COLLECTION_PUSH // Do initialization work here ANNOTATE_DISABLE_COLLECTION_POP // Do interesting work here ANNOTATE_DISABLE_COLLECTION_PUSH // Do finalization work here ANNOTATE_DISABLE_COLLECTION_POP return 0; }
Intel Inspector XEは、アプリケーション実行中に動的分析を実行し、標準デバッガーと統合できるメモリおよびスレッドデバッガーです。 リーク、メモリへの不正アクセスなどのメモリ操作のエラー、およびストリームの操作エラー(デッドロック、データ競合など)を見つけることができます。 このような問題は、定期的な機能テストまたは静的コード分析によって見落とされる場合があります。
Valgrind *およびRational Purify *抑制ルールのインポート
Inspector XEには、開発者にとって関心のない個々の問題または問題のグループを抑制する機能があります。 たとえば、他の人のモジュールの問題や誤検知。 他のツールにも同様の機能があります。 大規模プロジェクトの抑制ルールは、コード、モジュール、問題の種類、およびその他の情報の場所を決定する個別のファイルに保存されます。
Inspector XEの新バージョン-アップデート7には、他のツール(ValgrindおよびRational Purify)によって生成された抑制ルールを含むファイルをインポートする機能があります。 これらのファイルは、Inspector XE形式に変換されます。 これにより、他のツールからInspector XEへの移行が簡単になり、抑制ルールベースの形成にかかる時間と過去の投資を節約できます。
さらに、Inspector XE抑制ルールがテキスト形式で保存されるようになり、手動で編集できるようになりました。
アプリケーションの終了前にメモリリークを検索する
メモリリーク検出は、Inspector XEで最も一般的なメモリ問題分析機能の1つです。 以前のバージョンでは、リークを検出するために、Inspector XEがメモリのすべての割り当てと解放を追跡できるように、プログラムを最初から最後まで実行する必要がありました。 これは、たとえば、アプリケーションが長時間実行される場合、または一般的にデーモンやサービスのように「永久に」実行される場合、必ずしも便利ではありません。 さらに、プログラムが正しく完了しないとクラッシュし、この方法でリークを追跡することもできません。
Inspector XEの新しいバージョンでは、プログラマはメモリリークを探すコードの領域をマークできます。 このような領域をソースコード内の特別なAPIに制限できます。 グラフィカルインターフェイスのボタンとコマンドラインのコマンドを使用して、現時点で検出されたリークに関するレポートを呼び出すことができます。
つまり プロセスの完了を待たずに、コードの1つのセクションでリークを検索し、それらについて知ることができます。
Intel VTune Amplifier XE-パフォーマンスプロファイラー。 CPUリソースの観点から、スレッド、モジュール、関数、命令などにより、アプリケーションの最も高価なセクションが表示されます。 このツールは、これらの期待の原因となるスレッド、待ち時間、および同期オブジェクト間の負荷分散に関する情報を提供します。 VTune Amplifier XEは、キャッシュミス、偽共有など、マイクロアーキテクチャのパフォーマンスの問題を検出します。
詳細なオーバーヘッドレポート
マルチスレッドプログラムでは、CPUの時間の一部は、スレッドの同期、スレッド間の作業の分散などに必然的に費やされます。 この時間は、基本的な計算に費やされず、オーバーヘッドまたは「オーバーヘッド」と呼ばれます。 パフォーマンスを改善するには、これらのオーバーヘッドを最小限に抑える必要があります。 VTune Amplifier XEは、オーバーヘッドとアクティブ待機(スピン待機)に関する詳細情報を提供できるようになりました。 特定の関数、モジュール、または命令でオーバーヘッドに費やされるCPU時間を見積もることができます。 このツールは、OpenMP、Intel Threading Building Blocks、またはIntel Cilk Plusからのオーバーヘッドを表示できます。 テーブル内の時間値とタイムライン上のグラフィック表示の両方を使用できます。
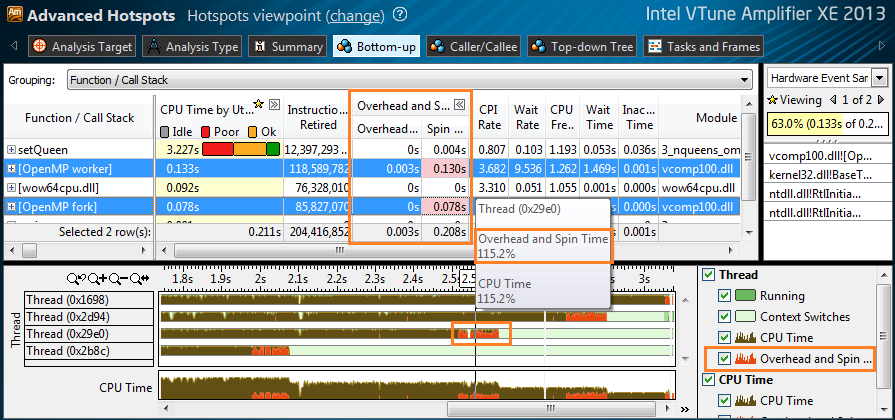
OpenMP *アプリケーション分析の改善
新しいVTune Amplifier XEには、OpenMP領域分析機能が強化されています。 ボトムアップパネルの「フレームドメイン」でグループ化すると、OpenMPリージョンがフレームとして表示されます-下の図を参照してください。 フィルターを使用すると、パフォーマンスプロファイルを別の並列領域に絞り込んだり、そこで費やした時間を見積もったり、負荷バランスをどのようにしたかなどを推定したりできます。 「[フレームドメインなし-任意のフレームの外]」という行はプログラムの連続部分を表しているため、コードの「並列性」の程度を評価できます( アムダールの法則を思い出してください)。

OpenMPに関連するオーバーヘッドとレイテンシは、Intel OpenMPだけでなく、GCC *およびMicrosoft OpenMP *についても決定されます。 上の図(高度なホットスポット分析)では、「[OpenMP worker]」と「[OpenMP for]」はMicrosoft OpenMP *ライブラリ-モジュールvcomp100.dllを指します。
コマンドラインからソースコードとアセンブラを表示する
場合によっては、グラフィカルインターフェイスよりもコマンドラインを使用する方が便利です。 たとえば、SSH経由でリモートLinuxサーバーで作業している場合。 これで、コマンドラインから直接VTune Amplifier XEプロファイルのソースを見ることができます。 そのため、リモートマシンからプロファイリング結果をコピーしたり、VNCを構成したりする必要がない場合があります。データの収集を開始した同じシェルからプロファイルをすばやく確認できます。
# amplxe-cl -report hotspots -source-object function=grid_intersect -r r000hs/ Source Line Source CPU Time:Self ----------- ------------------------------------------------------------ ------------- 460 return 1; 461 } 462 463 464 /* the real thing */ 465 static void grid_intersect(grid * g, ray * ry) 0.036 466 { 467 468 469 flt tnear, tfar, offset; 470 vector curpos, tmax, tdelta, pdeltaX, pdeltaY, pdeltaZ, nXp, nYp, nZp; 471 gridindex curvox, step, out; 472 int voxindex; 473 objectlist * cur; 474 475 if (ry->flags & RT_RAY_FINISHED) 476 return; 477 478 if (!grid_bounds_intersect(g, ry, &tnear, &tfar)) 479 return; 480 481 if (ry->maxdist < tnear) 0.020
発信者/着信者のコールツリー分析
新しい発信者/着信者タブは、ボトムアップとトップダウンの最高の組み合わせです。 呼び出された関数を考慮して、各関数の実行時間と合計時間を表示します。 強調表示された関数の場合、その親(呼び出し元)が右上のウィンドウに表示され、呼び出された関数(呼び出し先)が右下に表示されます。 [呼び出し元/呼び出し先]ウィンドウで、呼び出しシーケンスと各レベルのCPU消費への寄与を調べることができます。 任意の関数のフルタイムでフィルタリングし、任意のレベルでこの関数を持つすべてのツリーを取得できます。 したがって、最も重要なコールのブランチを見つけることができます。
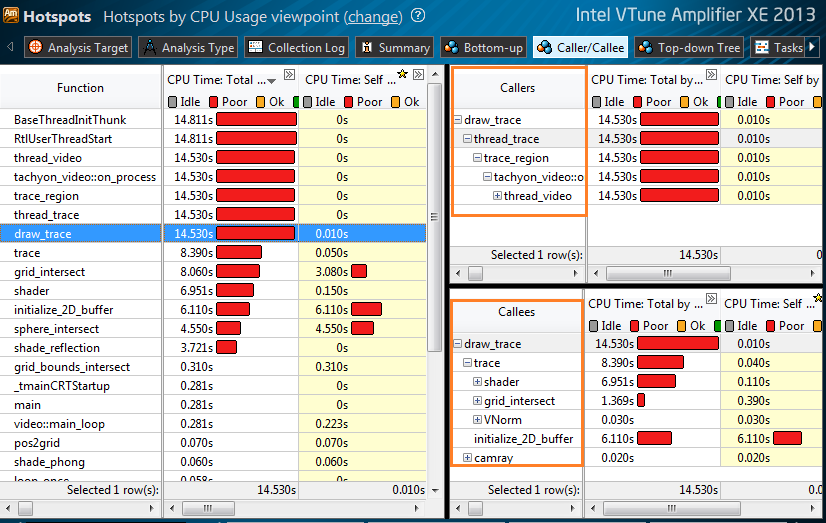
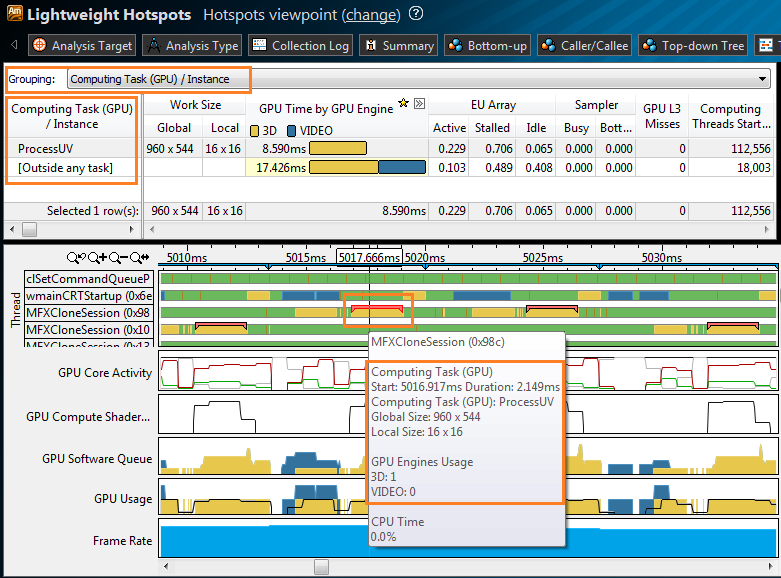
GPUプロファイリング
VTune Amplifier XEは、Intelプロセッサーグラフィックスで実行されるコードをプロファイルできるようになりました。 GPUの全体的なアクティビティを追跡できます。ビデオのデコードに使用されていますか? どのCPUスレッドがGPUコンピューティングをトリガーしますか? すべてのGPUリソースが使用されていますか? この機能は、OpenCLを介してGPUで実行されるタスクを計算する場合に特に興味深いものです*。 VTune Amplifier XEはOpenCLカーネル(またはコンピューティングタスク)を認識し、作業のサイズとL3キャッシュミスなどのマイクロアーキテクチャの問題を確認できます。 OpenCLタイムラインでは、カーネルはそれらを開始したCPUスレッドでマークされます。 GPU実行ユニット(GPU)の状態(アクティブ、アイドル、ストール)を経時的に観察できます。 GPUのロードに関するデータがあるため、プログラムのパフォーマンスが制限されているかどうかを評価できます。CPUまたはGPU。OpenCLカーネルがより多くのリソースを消費します。GPUをさらにロードし、それに応じてCPUをアンロードする機会があります。
第4世代Intel Coreプロセッサーのトップダウンパフォーマンス分析
マイクロアーキテクチャの問題の研究は重要な作業です。 CPUのマイクロアーキテクチャの理解と、プロセッサで何が起こっているかを記録するハードウェアイベントの知識が必要です。 この分析をより構造化されたわかりやすいものにするために、一般探査分析のハードウェアカウンターからのデータは、より理解しやすいメトリックにコンパイルされ、上から下へ、または一般から特定に編成されました。 ツール自体が、データが収集されたプラットフォームのメトリックを計算し、パフォーマンスを制限する可能性のある問題を強調表示します。 データの階層表現により、詳細レベルを制御でき、ナビゲーションがより便利になります。

まとめ
インテル®Parallel Studio XE 2013 SP1は、コプロセッサー向けに効果的にプログラムする新たな機会を提供し、OpenMPなどの並列モデルからより多くのものを取得し、新しいマイクロアーキテクチャーで複雑なパフォーマンス問題を見つけて修正し、優れたソフトウェア製品を作成します 新しいバージョンをダウンロードして、新しい機能が現在のプロジェクトをどのように改善できるかをご覧ください。