移行
したがって、データベースに格納され、それに関連付けられたデータは論理的に相互に交差しないため、データベースをアカウントのテーブル(アカウント)に従って分割します。 データベース作成スクリプトがあるので、SQL Azureフェデレーションを使用するようにスクリプトを調整してみましょう。
データベースは、Windows Azure管理ポータルまたはSQL Server Management Studioで既に作成されていると想定しています。
データベースにオブジェクトを作成するためのスクリプトを開きます。
USE xPenses
GO
IF EXISTS (SELECT name FROM sysobjects where name = N'Operation') DROP TABLE Operation
...
最初に削除するのはUSE操作の使用です。これは、SQL Azureの基本的な制限の1つであるためです。 1つのデータベース-1つの接続。 代わりに、フェデレーションを作成するリクエストを追加します。
-- A database must be selected before executing this statement
CREATE FEDERATION Accounts(AccountId BIGINT RANGE)
GO
USE FEDERATION Accounts(AccountId = 1) WITH RESET, FILTERING = OFF
GO
たとえば、SSMSを使用してSQL Azureサーバーに接続する場合、クエリを完了するにはリストからデータベースを選択する必要があることに注意してください。

したがって、新しいフェデレーションを作成し、そのデータはアカウント識別子(アカウントID)の値によって配布されます。 現時点では、データベースにテーブルが作成されていないことに注意してください。つまり、AccountIdフィールドは実際のテーブルのデータセットに関連付けられていません。 フィールドの名前は、配布が実行されるテーブルのフィールドの名前とも異なる場合があります。
ここで、SQL Azure Federationの別の論理的な制限を確認できます。 配布が実行されるフィールドは、タイプINT、BIGINT、UNIQUEIDENTIFIER、およびVARBINARYである必要があります。
連携を作成したら、データの入力を開始する最初のシャードを選択する必要があります。 つまり、最初のアカウント(AccountId = 1)のデータを保存するシャードです。
以下のスクリプトを参照してください。 Idフィールドによるこのテーブルのデータがシャードによって分散されることをSQL Azureが認識するように、アカウントのテーブルの作成を変更する必要があります。
CREATE TABLE Account (
[Id] INTEGER NOT NULL PRIMARY KEY IDENTITY(1,1),
[EntityId] INTEGER NOT NULL FOREIGN KEY REFERENCES Entity(Id),
[Currency] NVARCHAR(3)
)
したがって、テーブル作成スクリプトは次のようになります。
CREATE TABLE Account (
[Id] BIGINT NOT NULL,
[EntityId] INTEGER NOT NULL FOREIGN KEY REFERENCES Entity(Id),
[Currency] NVARCHAR(3),
CONSTRAINT [PK_Account] PRIMARY KEY CLUSTERED
(
[Id] ASC
)
) FEDERATED ON (AccountId= Id)
それで、何が変わったのでしょうか? IDフィールドタイプはBIGINTになりました。 さらに、新しいレコードを挿入するときに、このフィールドの値を自動的に生成する機能を失いました。 これは、SQL Azureフェデレーションのもう1つの制限です。 ただし、DEFAULTキーワードは引き続き使用できます。 たとえば、これはIDフィールドのタイプがUNIQUEIDENTIFIERの場合に役立ちます。 この場合、次の方法でフィールドを宣言できます。
[Id] UNIQUEIDENTIFIERNOT NULL DEFAULT NEWID()
次に、テーブルに新しいレコードを挿入するときに、作成されたレコードのIDを指定する必要はありません。 他のタイプを使用する場合、このロジックはアプリケーションレベルで実装する必要があります。
次に注意すべきことは、テーブルのメインキーの宣言です。 作成されるキーがクラスター化されることを明示的に示す必要があります。
最後に行うことは、このテーブルが統合されることをFEDERATED ONキーワードで示すことです。 その中のデータはIDフィールドで分割されます。
それで、勘定科目表の作成で、私たちは理解しました。 さらに進んでいます。 データベーススキーマからわかるように、アカウントテーブルは、「クレジットカード」テーブルと「銀行口座」テーブルに関連する親です。
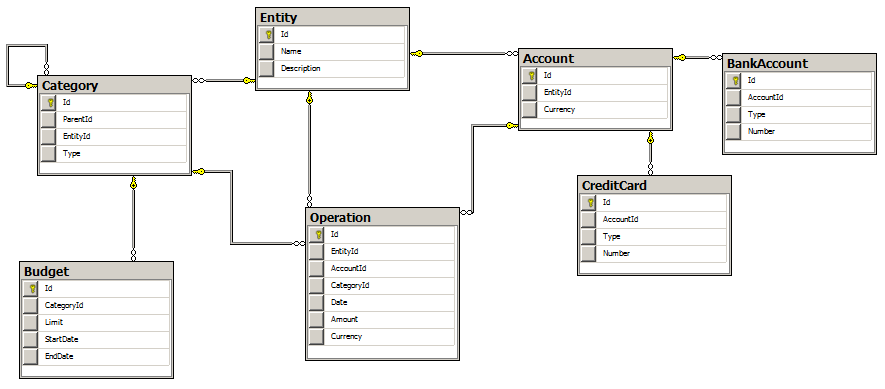
つまり、BankAccountテーブルとCreditCardテーブルには、Accountテーブルへの外部キーがあります。 アカウントテーブルはフェデレーションされているため、あるテーブルから別のテーブルへのリンクの整合性を確保することはできません。
これは、SQL Azureフェデレーションのもう1つの制限です 。 連合テーブルデータテーブルは、他のテーブルで参照できません。 つまり、アカウントのテーブル(アカウント)を参照するテーブルからすべての外部キーを削除する必要があります。
したがって、次の形式ではなく、CreditCardなどのテーブル作成スクリプト:
CREATE TABLE CreditCard (
[Id] INTEGER NOT NULL PRIMARY KEY IDENTITY(1,1),
[AccountId] INTEGER NOT NULL FOREIGN KEY REFERENCES Account(id),
[Type] NVARCHAR(MAX)
CONSTRAINT CreditCardType CHECK (
[Type] = 'Visa'
OR [Type] = 'MasterCard'
OR [Type] = 'JCB'
OR [Type] = 'AmericanExpress'),
[Number] NVARCHAR(MAX)
)
次の形式を取ります。
CREATE TABLE CreditCard (
[Id] INTEGER NOT NULL PRIMARY KEY IDENTITY(1,1),
[AccountId] BIGINT NOT NULL,
[Type] NVARCHAR(MAX)
CONSTRAINT CreditCardType CHECK (
[Type] = 'Visa'
OR [Type] = 'MasterCard'
OR [Type] = 'JCB'
OR [Type] = 'AmericanExpress'),
[Number] NVARCHAR(MAX)
)
つまり、クレジットカードテーブルからアカウントテーブルへのレコード内のリンクの整合性は、アプリケーションロジックの肩にかかっています。
この段階でデータベース作成スクリプトを実行しようとすると、すべてのテーブルが正常に作成されますが、テーブルに加えて、データベースには2つのプロシージャも含まれます。 それらの最初の-新しいカテゴリの追加は、そのロジックが1つのシャードの範囲を超えないため、変更を必要としません。
ただし、新しいアカウント(AddAccount)を追加する手順には、わずかな変更が必要です。 したがって、この手順のソースコードを検討してください。
CREATE PROCEDURE AddAccount(
@Name NVARCHAR(MAX),
@Description NVARCHAR(MAX),
@Currency NVARCHAR(3),
@Instrument NVARCHAR(MAX),
@Type NVARCHAR(MAX),
@Number NVARCHAR(MAX)
)
AS
INSERT INTO Entity VALUES (@Name, @Description)
DECLARE @EntityId INTEGER = (SELECT Id FROM Entity WHERE Name = @Name AND Description = @Description)
INSERT INTO Account VALUES (@EntityId, @Currency)
IF (@Instrument = 'BankAccount')
BEGIN
INSERT INTO BankAccount VALUES (
(SELECT Id FROM Account WHERE Account.EntityId = @EntityId),
@Type,
@Number
) END
IF (@Instrument = 'CreditCard')
BEGIN
INSERT INTO CreditCard VALUES (
(SELECT Id FROM Account WHERE Account.EntityId = @EntityId),
@Type,
@Number
) END
GO
実際、必要な変更はかなり明白です。 アカウントのIDフィールド値を自動的に生成する機能を失ったため、このロジックはアプリケーションロジックにかかっています。 つまり、プロシージャヘッダーに変更を加える必要があります。
CREATE PROCEDURE AddAccount(
@AccountId BIGINT,
@Name NVARCHAR(MAX),
@Description NVARCHAR(MAX),
@Currency NVARCHAR(3),
@Instrument NVARCHAR(MAX),
@Type NVARCHAR(MAX),
@Number NVARCHAR(MAX)
)
AS
INSERT INTO Entity VALUES (@Name, @Description)
DECLARE @EntityId INTEGER = (SELECT Id FROM Entity WHERE Name = @Name AND Description = @Description)
INSERT INTO Account VALUES (@AccountId, @EntityId, @Currency)
...
GO
したがって、コードではなく、アカウントテーブルにレコードを挿入します。
EXEC AddAccount 'Cash', 'Everyday cash account', 'USD', NULL, NULL, NULL
これで、もう1つのパラメーター(作成されるアカウントのID)を受け入れます。
EXEC AddAccount 1, 'Cash', 'Everyday cash account', 'USD', NULL, NULL, NULL
おそらく次の論理的な質問は次のようになります。目的のフェデレーション(USE FEDERATION)を使用するコマンドをプロシージャの本体に追加することは可能ですか? 作成しているアカウントのIDを受け取った場合、どのフェデレーションを使用する必要があるかがわかるため、必要なシャードの使用をすぐに進めることができます。
USE FEDERATION Accounts(AccountId = @AcccountId) WITH RESET, FILTERING = OFF
GO
残念ながら、そうすると、SSMSはエラーを出します。 問題は、AddAccountプロシージャが特定のシャードに格納されていることです。つまり、USE FEDERATIONを使用することはできません。 さらに、一般的に、手順ではUSE FEDERATIONを使用することはできません。 連携を切り替えるためのコードは、「1レベル上」に配置する必要があります。
データベース作成スクリプトで行う必要のある変更は終了しました。 エラーなしで実行できます。 その結果、1つのルートデータベース(フェデレーションルート)と1つのシャード(フェデレーションメンバー)が作成されます。
シャーディング
あとは、スケーリングデータベースを実際に作成するだけです。 つまり、あるアカウントに関連するデータを別のアカウントのデータから分離することです。
これを行うには、別のスクリプトを作成します。
-- Scaling out the federation
USE FEDERATION ROOT WITH RESET
GO
ALTER FEDERATION Accounts SPLIT AT (AccountId = 2)
GO
このスクリプトが最初に行うことは、フェデレーションルートの使用に切り替えることです。つまり、フェデレーション情報(メタデータ)が保存されているため、xPensesデータベース内で機能します。
次に、AccountIdフィールドの値が2で始まるAccountsという名前のフェデレーションを解除することを示します。つまり、最初のアカウントのデータは既に作成されたシャードに残り、他のアカウントのデータは次のシャードに転送されます。 また、データが勘定科目表に分類されることをどこにも示していないことにも注意してください。 xPensesデータベースメタデータのみを使用します!
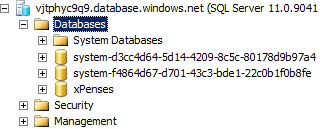
そのため、このコマンドを実行すると...オブジェクトエクスプローラーウィンドウを更新すると、次のように表示される可能性が高くなります。

1つの新しいシャードの代わりに、... 3枚もあります! 実際、これには珍しいことは何もありません。 問題は、最初のシャード内に保存されたデータがAccountIdの値に従ってコピーされることです。 つまり、IDが1のアカウントの場合、IDが2のシャードにデータをコピーする必要があります。 当然、これには時間がかかります。 SQL Azureがデータをシャードに再配布すると、フェデレーションメタデータと2つのシャードを持つデータベースが実際にあることがわかります。
データを3つのシャードに分割する必要がある場合、たとえば、IDが3のアカウントデータを別のシャードに転送する必要がある場合は、次のコマンドを実行するだけで十分です。
ALTER FEDERATION Accounts SPLIT AT (AccountId = 3)
GO
おわりに
SQL Azureフェデレーションを使用する場合のデータベース作成スクリプトの移行プロセスを調べました。 ご覧のとおり、ほとんどの鋭角コーナーは非常にシンプルです。 ただし、データベースロジックのかなりの部分を「より高く」運ぶ必要があります。 データベースレベルで停止しました。 実際のプロジェクトでは、SQL Azureフェデレーションへの移行を開始する前に、ドメインとデータベースアーキテクチャを慎重に分析することを強くお勧めします。