oneいテーブルを他のプロパティを持つ美しいテーブルに置き換えたり、写真や柔らかい色を追加したりすることではなく、すべてが素晴らしいことですが、私はアーティストではなく、テーブルのスタイルに大きな違いはありません。読み取りを妨げるまで。
アイデアは、スケジュールへのアクセスを簡素化することでした。 NSUのWebサイトで入手可能な元の時刻表は、 ここで表示できます 。 自分のスケジュールを見つけるには、サイトのメインページから「古いサイト」、「情報システム」、「クラススケジュール」の順に進み、建物、学部、グループ、合計-6クリックを選択する必要がありました。 これらの移行のほとんどは、軍団の選択を除いて非常に意味のあるように見えました。学部がまだ異なっていて、その総数が2ページに分かれるほど大きくない(合計で約10)のはなぜでしょう。 しかし、教師や友人のスケジュールを見つける必要がある場合、状況はもう少し複雑になりました。 教師にとっては、最悪の場合は両方のケースをチェックする必要があり、友人にとっては、最初にグループリストで彼を見つけ、グループ番号を見つけてから、他のすべてを見つけなければなりませんでした。 手順はかなり実行可能ですが、常にそれらを実行する必要はありません。この情報を収集し、誰もが既に使用している検索エンジンのように、スケジュールを検索する人の名前を行に入力するだけでそのようなサンプルを実行できるようにすることを妨げるものはありません。
解析リスト
学生のリストから始めましょう。幸いなことに、それはxmlとして利用でき、各グループに対して次のようになります。
<group name="0502, - , ()"> <student name=" " status=""/> <student name=" " status=""/> <student name=" " status=""/> ... </group>
このようなデータをエクスポートするには、次のコードが使用されます。
public function exportGroup($groupFile, $groupName, $department, $course) { $grouplist=file_get_contents($groupFile); $dom2 = new domDocument; $dom2->loadXML($grouplist); $s2 = simplexml_import_dom($dom2); for ($k=0;$k<count($s2->student);$k++) { $attrs=$s2->student[$k]->attributes(); $student=new Student(); $student->name=$attrs["name"]; $student->group=$groupName; $student->department=$department; $student->course=$course; $student->save(); } }
さらに、学部ごとにグループのリストを選択する必要がありますが、これは同様のxmlファイルから同じ方法で行われます。
有効な修正
クラススケジュール自体はxmlでは使用できません。さらに、NSUスケジューリングシステムによって生成されたhtmlは無効であることが判明しました。これにより、有効に変換するか、正規表現で解析するかを選択できました。 どういうわけか私は本当に正規表現に頼りたくなかったと言わなければなりません。 htmlファイルを見ると、ドキュメントを有効にするために、つまり<tr>タグを1つ追加して(欠落している)エンコードを指定するために、それほど多くの作業を行う必要がないことに気付きました。 次のことが判明しました。
$text=file_get_contents($url); $text = iconv ( "CP1251" , "UTF-8" , $text ); $doc = new DOMDocument(); $doc->loadHTML(str_replace("</HEAD>", '<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> </HEAD>', str_replace("<TH Width=10%>", "<TR><TH Width=10%>", $text))); $s = simplexml_import_dom($doc);
これらの操作の後、スケジュールは非常に理解されました。 utfにトランスコードしないことは可能でしたが、他のすべてのプロジェクトデータはutfであり、これらのファイルのエンコーディングは指定されていなかったため、このステップで変換することをお勧めします。
検索する
したがって、私はグループと教師のスケジュールだけでなく、学生のリストを得ました。
結果の構造内の時間割はグループまたは教師を参照しますが、生徒を参照しません。 学生、教師、グループ、および学部を検索するには、データベースサーバーに対する複雑なクエリまたは複数のクエリが必要でした。 そのような要求を行うことは問題ではありませんが、その実行速度を恐れました。 検索用の別のテーブルを「検索可能」にすることを決定しました。このテーブルには、検索に使用されるエイリアスと、ドキュメントのアドレスが含まれる列があります。 まず、アクセス時間を最適化するため。 また、「数学者Vasily 1コース」などのクエリを処理できるようになりましたが、同時にドキュメントのアドレス(url)がいくつかの異なるテーブルに含まれているため、データベースの状態に一貫性を持たせることができました。 後者はまったくプラスではありませんが、この場合、プラスはこのマイナスよりもはるかに重要であるように思われました。
REST API
他の人がこのルーチン全体を完了する必要がないように、2つのサードパーティプロジェクトで既に使用されていると思われるオープンREST APIを公開しました。 APIリクエストには、検索文字列と、リクエストされたスケジュールのタイプ(1日、1週間、および最も近いペア)が含まれます。 回答には、JSON形式のスケジュール、または特定の行に複数のスケジュールが対応する場合に対応するスケジュールの名前とアドレスが含まれます。
略語の説明
公開後、かなりの数の人々が、スケジュールでは解釈が難しい理解しにくい略語を使用していると述べました(たとえば、「O.ob.chemistry」は「Fundamentals of General and Inorganic Chemistry」、「TFCI」は「複雑な変数の機能の理論」です)。 この問題を解決する2つの方法を見ました。1。学生にフルネームを示す機会を提供すること。2.何らかの方法でそれらを解読しようとすること。 最初のオプションはシンプルで面白いように見えましたが、モデレートシステムとデコードなしで視聴する機能を導入する必要があったため、私自身は名前がどのように提供されたかを判断できず、各学部の専門家を見つけることは実際にはこれらの略語を解読するように複数の人に依頼することを意味したため、物議をかもしました。 自動復号化の可能性を見つけようとし、学科と教科のリストを見つけました。 これらのリストは完全ではありませんでしたが、学生のリストの絶対的な正確性に違いはなかったと言わざるを得ません。 さらに、学科のリストにある教師の名前は、名前と愛称の解読で示され、スケジュールではイニシャルで示されますが、これはそれほど大きな問題ではありません。 最初のアイデアは、1つの科目のみをリードし、それらからすべての名前を決定するような教師を見つけることでした(NSUの過半数は教育を他の仕事と組み合わせ、多くの人が1つの分野をリードしています)結果。 おそらく、1つの科目を持つ教師は、私が取得できた大聖堂のリストにはあまり参加していなかったのかもしれません。 次に、一致する文字の数で比較してみましたが、かなり奇妙な結果も得られました。 最良の方法は、この教師がこの手紙で始まる唯一の主題を持っている場合にのみ、短縮名と完全な名前の間の対応を確立する方法でした。 したがって、ほとんどのアイテムを解読することができました。
聴衆による
さらに、私の手は非常にかゆくて教室/教師の作業負荷の統計的研究を行い、現在のスケジュールの情報を表示できるというアイデアを得ました:現在、誰が、どの教室にいるか、何人、何人の男子学生、そして何人-女性。 もちろん、最後の特徴は、プロジェクトをより楽しくするためだけに考案されたもので、すべての名前を表示することも可能ですが、問題は、スケジュール内のグループ番号が学生リスト内の番号と必ずしもうまく対応していないことでした。 たとえば、スケジュールにはグループ123.1、123.2、123.3があり、リストには123しかありません。したがって、各グループに何人いるかはおおよそわかりますが、どのグループの誰を正確に言うことはできません。 学生の名前を使用して性別を判断しました。 定義は男性の名前と女性の名前を正確に区別できるのと同じくらい正確だったと言わなければなりません。それは常に可能ではありませんでしたが、ほとんどの場合はうまくいきます。 この情報に基づいて、10分ごとに自動的に更新されるオーディエンスマップが作成され、学生、女子学生、場所の数(スケジュールに表示される最大数)、および現在このオーディエンスにいるグループの数が表示されます。 空の聴衆を探しているか、何かを失い、それを見ることができるすべての人にインタビューしたい場合、それは非常に役立ちます。
オーディエンスがスケジュールから選択され、コーパスを指定する接尾辞が並べ替えられ、次の形式のリストが表示されるようにページに表示されました。

各観客/軍団について、入力された日の混雑のグラフが表示されます
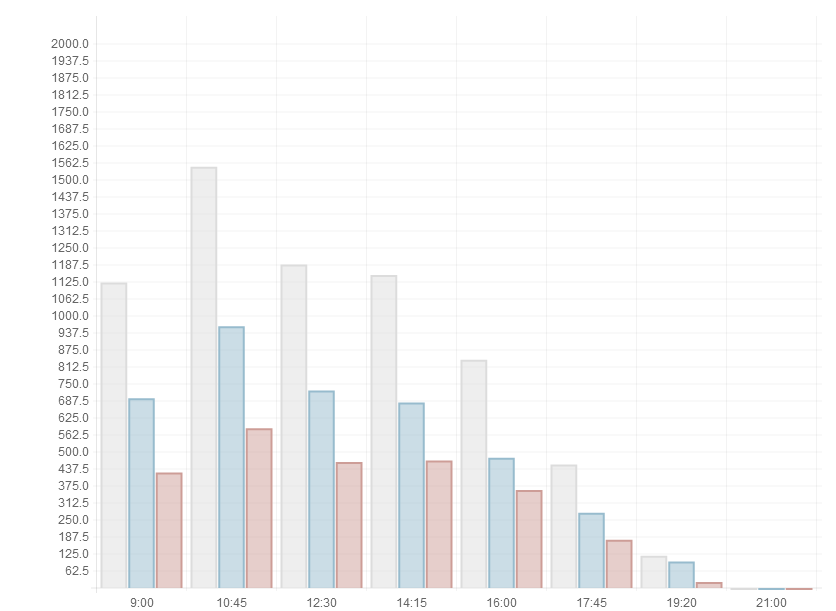
これは金曜日のNSUの本館のスケジュールです。 このサービスを使用すると、どの学校の日に聴衆や軍団のためにそのようなものを見ることができます(教育以外のスケジュールは空ではありません)。 ここで、Yは人数、時間はペアの始まりです。 赤いバーは学生用、青いバーは学生用、灰色は合計用です。 Yの小数スケールは驚くべきもので、事実は、整数だけを表示するグラフライブラリを設定することができなかったということですが、私にはそれほど重要ではないようです。 はい、小数の人はいませんが、列は非整数の数字に基づいていません。
記事を書く前に、私はすべてがMSUでどのように機能するかを見て、空の教室の地図でさえスケジュールを見つけましたが、情報を得るには忍耐が必要であることがわかりました。 また、クリック数も豊富ではありませんが、これも豊富ですが、応答が非常に遅くなります。 定期的に表示されるSQLエラーから、DBMSの使用に関する結論を導き出すことができますが、どうやらすべてがあまりにも最適に配置されていないようです。
統計
利用可能なデータは、さらにいくつかのグローバルな数値を提供しました。
最大収容人数を考慮した教室の平均負荷は28%です(勉強している生徒数を教室の収容人数で割ったもの、日と時間で平均)
少なくとも1人の学生が関与している場合、NSUでの平均視聴者負荷、完全に負荷がかかっているとみなす場合-60%
最も女性の視聴者-500、431、608-少女の約89%
最も男性の視聴者は312人で、女性の10%のみです
最も女性的な時間-14:15、女の子の53%
最も男性的な時間は19:20で、女子の46.8%
ほとんどの女性の日は火曜日、女子の52.3%
最も男性的な日は月曜日です49.2%の女の子
このことから、ほぼ女子だけが関わっている視聴者がいると結論付けることができますが、大学の女子の数が真剣に勝つ時間や日はありません。
統計は娯楽目的でのみ取得されたものです。この記事が、インターネットユーザーの1人にオープンデータの整理分野での実験を促したり、単に大学で同様のスケジュールを作成したりしてくれたら嬉しいです。
参照:
元のスケジュール
www.nsu.ru/education/schedule
分解されたプロトタイプ
nsu-schedule.ru
オンラインのオーディエンスマップ
nsu-schedule.ru/now
MSU時刻表
cacs.law.msu.ru