誰かがランダムに問題を残し、誰かがFive Hundredにバナーを掛け、失敗からお金を稼ごうとします。 誰かがデータベースまたはネットワークデバイスのベンダーの標準ソリューションを使用しています。 そして、誰かが今流行の「雲」に入ります。

1つはっきりしていることは、ビジネスが成長するにつれて、障害に対する回復力(障害後の回復手順でさえも)を確保することがますます深刻な問題になることです。 会社の評判は、年間の事故件数に依存し始め、長いダウンタイムにより、サービスの利用などが不便になります。 多くの理由があります。
この記事では、フォールトトレランスを確保する方法の1つを検討します。 安定性とは、このシステムのできるだけ多くのノードで障害が発生した場合にシステムの操作性を維持することを意味します。
通常、Webアプリケーションアーキテクチャは次のように構成されます(アーキテクチャも例外ではありません)。

Webサーバーは、要求の主な処理とディスパッチに従事し、サブジェクト領域のほとんどのロジックを実行し、データの取得場所、処理方法、新しいデータの配置場所を認識しています。 どの特定のWebサーバーがユーザーリクエストを処理するかに大きな違いはありません。 ソフトウェアが多かれ少なかれ正しく記述されていれば、Webサーバーは必要な作業を正常に実行します(もちろん、過負荷でない限り)。 したがって、いずれかのサーバーの障害が深刻な問題につながることはありません。生き残ったサーバーへの単純な負荷転送があり、Webアプリケーションは動作し続けます(理想的には、保留中のトランザクションはすべてロールバックされ、ユーザーリクエストは別のサーバーで再び処理できます) 。
主な問題は、データストレージレベルで始まります。 このサブシステムの主なタスクは、システム全体の機能に必要な情報を保存および増加することです。 このデータの一部は失われる場合があり、残りはかけがえのないものであり、それらの損失は実際にプロジェクトの死を意味します。 いずれにせよ、データが部分的に失われたり、損傷したり、一時的に利用できなくなったりすると、システムのパフォーマンスは劇的に低下します。
実際、もちろん、すべてがはるかに複雑です。 Webサーバーに障害が発生した場合、通常、システムは前のポイントに戻りません。 これは、1つのビジネストランザクションの一部として、複数の異なるリポジトリで変更を行う必要があるという事実によるものです(一方、データウェアハウスレイヤーの分散トランザクションのメカニズムは通常実装されておらず、実装および運用するには費用がかかりすぎます)。 データの不一致のその他の考えられる理由は、プログラムコードのエラー、不明なスクリプト、開発者と管理者の不注意(「ヒューマンファクター」)、開発時間の厳しい制限、およびプログラマーがそれほど完璧ではないコードを書く他の重要で重要でない理由の束です。 ただし、ほとんどの場合、これは必要ありません(すべてのアプリケーションが銀行および金融セクター向けに作成されているわけではありません)。 システムは自動的にデータの一貫性を復元できるか、クラッシュ後にシステムを復元するための半手動ツールがあります、またはこれは必要ありません(例:ユーザーが設定を編集しましたが、失敗のため、設定の一部は変更されませんでした。ほとんどの場合、特に致命的ではありません。インターフェースがユーザーに変更を適用できなかったことを正直に伝えた場合)。
上記のすべての考慮事項を考慮すると、優れたストレージおよびデータアクセスシステムを持つことは、システムが事故を乗り切る能力に大きなボーナスを提供します。 そのため、データアクセスサブシステムでフォールトトレランスを確保する方法に集中します。
近年、データベースとしてTarantulaを使用しています(これはオープンソースプロジェクトで、ストアドプロシージャを使用して簡単に拡張できる非常に高速で便利なデータベースです。Webサイトhttp://tarantool.orgを参照してください)。
したがって、私たちの目標は最大のデータ可用性です。 ソフトウェアとしてのタランチュラは通常、問題を引き起こしません。安定しているため、サーバーの負荷が十分に予測され、負荷が増加してもサーバーが予期せずに終了することはありません。 機器の信頼性の問題に直面しています。 サーバーが燃えたり、ディスクが転がったり、ラックが切れたり、ルーターが故障したり、データセンターへのリンクが消えたりすることもあります...しかし、すべてにかかわらず、ユーザーにサービスを提供する必要があります。
データが失われないようにするには、データベースサーバーを複製し、別のラック、別のルーター、または別のデータセンターに配置し、メインサーバーからバックアップサーバーへのデータ複製を構成する必要があります。 データの必須かつ定期的なバックアップを忘れてはなりません。 技術的な故障が発生した場合、データは引き続き有効であり、アクセス可能です。 ただし、注意点が1つあります。データは別のアドレスで利用可能になります。 そして、アプリケーションは壊れたサーバーを習慣的にノックし続けます。
最も単純で最も一般的なオプションは、システム管理者の1人を起こして問題を特定し、すべてのアプリケーションを再構成して新しいデータサーバーを使用できるようにすることです。 最適なソリューションではありません。切り替えには時間がかかり、何かを忘れる可能性が高く、不規則な作業スケジュールは非常に悪いです。
信頼性は低くなりますが、より自動化されたオプションがあります。サーバーが稼働しているかどうか、および複製に切り替えるタイミングかどうかを判断するための専用ソフトウェアの使用です。 紳士の管理者に私を修正させてください。しかし、偽陽性の可能性はゼロではないように思われ、異なるリポジトリ間でデータの不一致が生じます。 確かに、障害に対するシステムの応答時間を増やすことで誤検知の数を減らすことができます(これにより、ダウンタイムが増加します)。
または、データのマスターコピーを各データセンターに配置し、この構成ですべてが正常に機能するようにソフトウェアを作成することもできます。 しかし、ほとんどのタスクにとって、このようなソリューションは素晴らしいものです。
また、データのマスターコピーがクラスターの一部で利用可能な場合に、ネットワーク分割のケースを処理できるようにしたいと考えています。
その結果、妥協オプションを選択しました-データベースへのアクセスに問題がある場合、自動的にレプリカに切り替えます(ただし、読み取り専用アクセスモードで)。 さらに、各サーバーは、マスターとレプリカの可用性に関する独自の情報に基づいて、レプリカに切り替えてマスターに戻すことに決定します。 データのマスターコピーを持つサーバーが実際に故障した場合、システム管理者はそれを修正するために必要なすべての手順を実行し、この時点でシステムは少しのカット機能で動作します(たとえば、一部のユーザーには連絡先編集機能がありません)。 サービスの重要度に応じて、管理者はさまざまなアクションを実行して、問題を解消することができます-交換品の即時導入から「朝のリフト」まで。 主なものは、わずかに切り捨てられたバージョンではあるが、Webアプリケーションが引き続き機能することです。 自動的に。
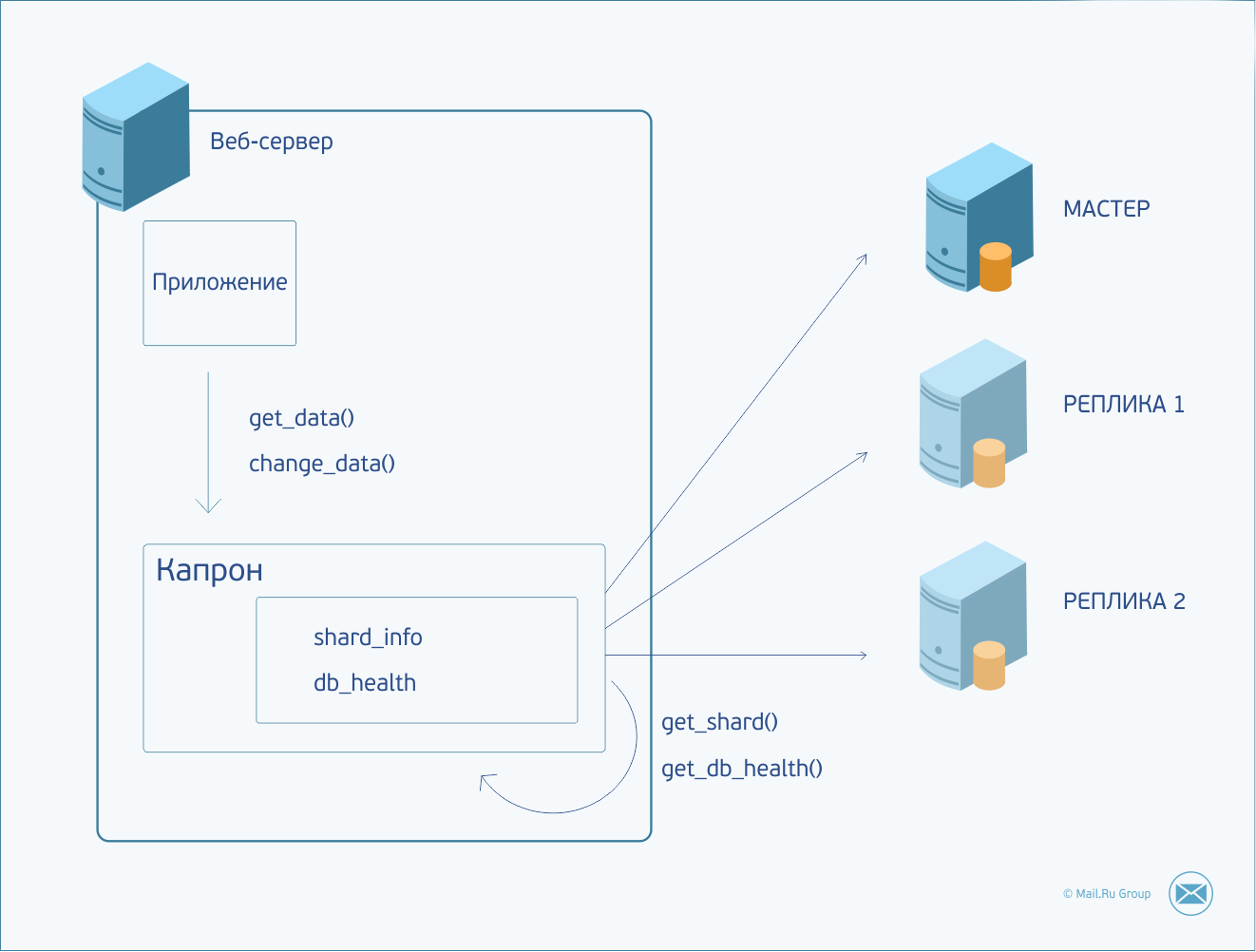
私たちの国で広く使用されている、各サーバーにある1つのコンポーネントについて説明するしかありません。 彼をカプロンと呼びます。 Kapronはデータベースクエリ(MySQLおよびTarantool)のマルチプレクサとして機能し、それらとの常時接続プールをサポートし、データベース構成、シャーディング、ロードバランシングに関するすべての情報をカプセル化します。 Kapronを使用すると、データベースプロトコルの機能を非表示にして、よりシンプルで明確なインターフェイスを顧客に提供できます。 非常に便利なもの。 そして、前述のロジックをそこに置く理想的な候補です。
そのため、アプリケーションはデータを使用していくつかのアクションを実行する必要があります。 要求を形成し、それをカプロンに渡します。 Kapronは、リクエストを送信するシャードを決定し、目的のサーバーとの接続を確立(または以前に作成した接続を使用)して、コマンドを送信します。 サーバーが利用できない場合、または応答タイムアウトが超過した場合、要求はレプリカの1つで複製されます。 障害が発生した場合、レプリカがなくなるかリクエストが処理されるまで、リクエストは次のレプリカなどに送信されます。 サーバーの可用性ステータスはリクエスト間で維持されます。 また、ウィザードが利用できない場合、次のリクエストはレプリカに直接送られます。 バックグラウンドのKapronは、マスターサーバーをノックし続け、稼働が始まるとすぐに、すぐに再び要求を送信し始めます。 レプリカに変更を加えようとすると、リクエストは失敗します。これにより、マスターまたはレプリカへのリクエストの送信先について心配する必要がなくなります。
リクエストのフローが大きいため、特定のデータベースサーバーのアクセス不能に関する知識が迅速に更新され、これにより、変化する状況に可能な限り迅速に対応できます。
その結果、かなりシンプルで多目的なスキームが実現します。 データのマスターコピーがクラッシュした場合だけでなく、通常のネットワーク遅延も処理します。 マスターがstaymautilの場合、リクエストはレプリカにリダイレクトされます(変更されないリクエストの場合、正常に処理されます)。 一般的な場合、これにより、読み取り要求に対するネットワークの期待のしきい値を下げることができ、マスターサーバーでのブレーキ中に、クライアントに結果を返す方が速くなります。
2番目のボーナス。 これで、データベースサーバーでソフトウェアの更新やその他のスケジュールされた作業をより簡単に(それほど痛みなく)実行できます。 通常、読み取り要求は大多数であるため、ウィザードを再起動してもほとんどの要求でサービス拒否は発生しません。
私たちはそこで止まらないことを計画しており、いくつかの明らかな欠点を排除しようとします。
1)ネットワークのタイムアウトの場合、レプリカにリクエストを送信しようとしています。 変更リクエストの場合、レプリカはリクエストを処理できないため、これは無駄な努力です。 変更コマンドを先験的にレプリカに送信しないのは理にかなっています。 コマンドタイプの手動設定のレベルで解決されます。
2)ネットワークタイムアウトは、ウィザードのデータが変更されないことを意味しません。 クライアントに戻りますが、彼のリクエストを処理できませんでした。 公平には、この欠陥が以前に存在したことは注目に値します。 この状況は、Tarantula側のコマンドの処理時間に制限を導入することで修正できます(指定した時間内に変更が適用されない場合、それらは自動的にロールバックされ、リクエストは失敗します)。 処理タイムアウトを1秒に設定し、ネットワークタイムアウトをKapronで2秒に設定します。
3)もちろん、Tarantulaの同期マスター-マスター-レプリケーションの開発者には期待しています。 これにより、複数のマスターコピー間でリクエストを均等に分散し、サーバーの1つが利用できない場合でもリクエストを正常に処理できます。
Dmitry Isaykin、主要Mail.Ruメール開発者