それでは、プロジェクトに戻りましょう。 データベースのサブジェクト領域は、個人財務会計です。 データベースダイアグラムを図に示します。
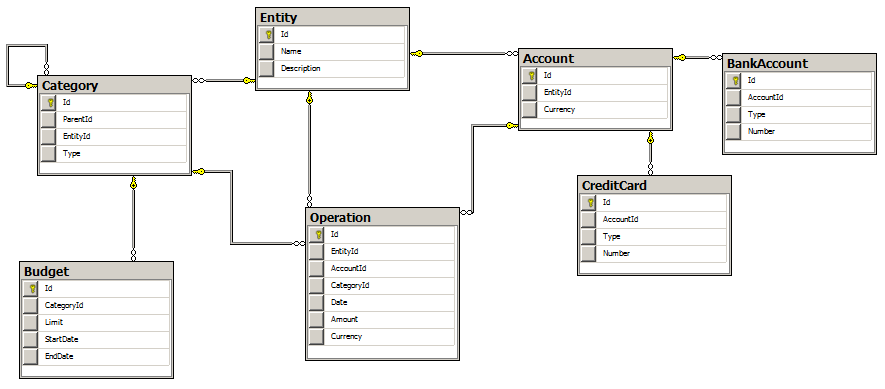
ご覧のとおり、データベースは非常に単純です。 各システムオブジェクトは、基本的なプロパティ(Id、Name、Description)を持つエンティティです。 特定のエンティティは、アカウント(それから継承:銀行口座、クレジットカード)、支出カテゴリ(それから継承:予算、および子カテゴリ)およびアカウントトランザクションです。
データベースには、テーブルに加えて、エンティティをデータベースに追加するためのロジック(ストアドプロシージャの形式でフレーム化)、およびデータベースへの一般的なクエリの結果を表示するためのいくつかのビューが含まれています。
データベースを作成するSQLスクリプトのソースコードは、 ここにあります 。
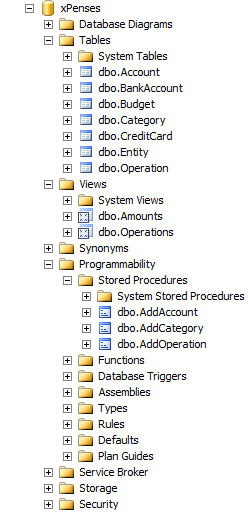
実際のプロジェクトでは、データベース内のアーティファクトの数は桁違いに大きくなる可能性がありますが、そのような小さなデータベースの移行でも、SQL Azureフェデレーションを使用するときに遭遇する可能性のある主なレーキを示すことがあります。
分析
急いでデータベースを移行してSQL Azureフェデレーションを使用する前に、データベース内のどのデータが論理的に独立しているかを判断する必要があります。 さまざまなデータベースに分散できるデータの種類。 実際、データが複数のデータベースに分割されるテーブル、いわゆる連合テーブルを選択する必要があります。
データベースの構造を見ると、最初に思い浮かぶのは、エンティティの基本テーブル(エンティティ)です。 このテーブルを作成するためのスクリプトは次のとおりです。
CREATE TABLE Entity (
[Id] INTEGER NOT NULL PRIMARY KEY IDENTITY(1,1),
[Name] NVARCHAR(MAX) NOT NULL,
[Description] NVARCHAR(MAX) NOT NULL,
)
一見、このテーブルは分割に最適です。 しかし、これはそうではありません。 はい、外部キーは含まれません。かなり単純な構造で、最大数のレコードが保存されます。 ただし、データベースのロジックに従って、「後続テーブル」のデータはこのテーブルに関連付けられています。 つまり、システムで作成されたすべてのエンティティのエンティティテーブルにエントリがあります。
この例を考えてみましょう。 データをエンティティの識別子の範囲(IDフィールド)に分割するとします。 ID 1〜50のレコードが最初のシャードに保存され、51〜100が2番目のシャードに保存されているとします。
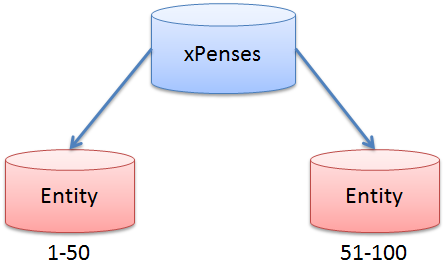
ユーザーは、Operationsテーブルに新しいレコードを追加しようとしています。 牛乳のパッケージの購入に関するデータとします。 アカウントエンティティIDが1、費用カテゴリIDが6であると仮定します。また、最初のデータベースにすでに50レコードがあると仮定します。
テーブルに新しいデータを追加するリクエストは次のようになります。
USE FEDERATION Entities(EntityId = 51) WITH RESET, FILTERING = OFF
GO
INSERT INTO Operation VALUES (
51, -- EntityId
1, -- AccountId
6, -- CategoryId
GETDATE(), -- Date
10, -- Amount
'USD' -- Currency
)
要求は完全に正しく実行されます。 このアカウント(ID = 1)のすべての操作のリストを取得してみましょう。 データベースには、これに対応するビューがあります。 そのコードは次のとおりです。
SELECT
Account_Entity.Description AS 'Account',
Operation_Entity.Name AS 'Operation',
Operation_Entity.Description,
Operation.Amount,
Operation.Currency,
Operation.Date
FROM
Operation
INNER JOIN Entity AS Operation_Entity ON Operation.EntityId = Operation_Entity.Id
INNER JOIN Account ON Operation.AccountId = Account.Id
INNER JOIN Entity AS Account_Entity ON Account.EntityId = Account_Entity.Id
INNER JOIN Category ON Operation.CategoryId = Category.Id
INNER JOIN Entity AS Category_Entity ON Category.EntityId = Category_Entity.Id
WHERE
Account.Id = 1
思い出すと、1つのアカウントのデータは異なるシャードに保存されます。 したがって、このクエリが正しい結果を返すには、各シャードで個別に実行する必要があります。
USE FEDERATION Entities(EntityId = 1) WITH RESET, FILTERING = OFF
GO
...
USE FEDERATION Entities(EntityId = 51) WITH RESET, FILTERING = OFF
GO
...
このアプローチからアプリケーションのパフォーマンスに大きな打撃が与えられることを説明する必要はないと思います。 最も単純なクエリでさえ2回実行する必要がある場合! 明らかに、Entityテーブルは私たちには適していません。
データベース設計に対するマルチテナントアプローチを思い起こせば、各ユーザーが自分のデータベースを操作し、データが重複しない場合、疑問が生じます。 SQL Azureフェデレーションのフレームワーク内で同様の何かを実装することは可能ですか? 各シャードには1人のユーザー(アカウント)のデータが含まれます。 実際、このアプローチは非常に論理的です。 ビジネスロジックの観点からは、次のようになります。
1人の家族が1つのプログラムを使用するとします。 それぞれが個別に予算を維持します。 また、夫が彼の経理を行い、妻が彼のようになっているとします。 したがって、夫のデータ(AccountId = 1)は妻のデータ(AccountId = 2)と重複しません。 この場合、勘定科目表によって断片に分割することは非常に論理的に見えます。
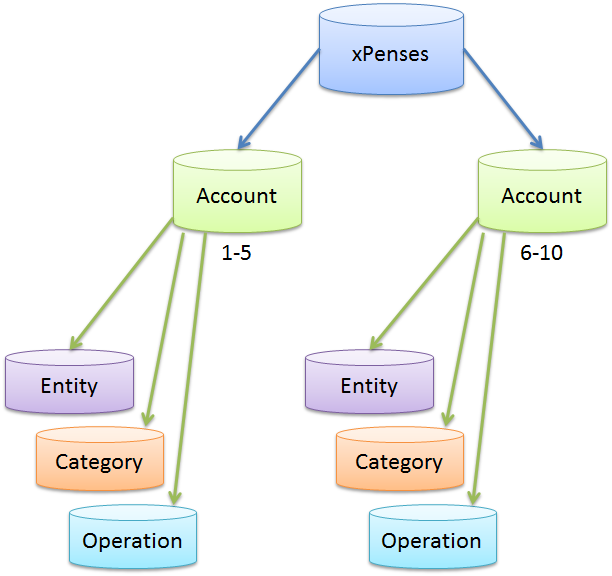
新しいアカウントの追加は、シャードの追加に対応します。 次のような頻繁な操作:カテゴリ、操作などのリストを操作しても、生産性は低下しません。
USE FEDERATION Accounts(AccountId = 1) WITH RESET, FILTERING = OFF
GO
そのようなリクエストを実行すると、現在作業しているユーザーのデータがすぐにわかります。 したがって、同じ操作は1回だけ実行されます。
そこで、既存のデータベースを分割するための2つのオプションを検討しました。 ここで、データを異なるデータベースに論理的に分割するフィールドを決定しました。 次回は、データを異なるシャードに直接拡散します。 切り替えないでください! 新しい週の仕事を始めましょう。 ご清聴ありがとうございました!