注釈
この記事では、複数のFPGAが同時に参加するPCI Expressバスを介したデータ転送について説明します。 複数の(この場合8)端末デバイス(PCIeエンドポイント)FPGAを備えたコンピューターシステムでは、2つのタイプの複数のデータ転送トランザクションが同時に開始されます。A)RAMとFPGA間のDMA転送(読み取り/書き込み)およびB)直接2つのFPGA間のデータ転送(記録)。 メモリにアクセスするときにPCI Express x4 Gen 2.0接続を使用すると、1451 MB / sの書き込み速度が得られました(最大値の90%)。 FPGA間のデータ書き込み速度は、パケット長が128バイトで1603 MB / s(最大の99%)で、パケット長が256バイトで1740 MB / s(最大の99%)でした。 FPGA間のデータ転送のレイテンシは、中間スイッチの数に依存し、1つのスイッチで0.7μs、3つのスイッチで1μsでした。 また、共通チャネルを介した同時伝送では、総伝送速度が共通チャネルの帯域幅を超えるまで、個々の伝送速度が低下しないことが示されています。 チャネルは100%で使用され、その帯域幅はデバイス間で均等に分割されます。
はじめに
PCI Expressは、高性能コンピューティング(HPC)タスクのために、CPU、システムメモリ、およびハードウェアアクセラレータ(GPU、FPGA)間でデータを転送するための事実上の標準となっています。 第一に、PCI Expressバスのレイテンシは小さく、第二に、データ転送速度が高い(PCI Express x8 Gen 3.0接続で約7 GB / s)。 最後に、PCIeバスは優れた拡張性を備えています。通常、マザーボードではPCI Expressバスコネクタが不足せず、GPUまたはFPGAの複数のアクセラレータボードを接続できます。 また、ケーブル接続を介してPCI Expressバスを拡張し、コンピューターケースの外部に追加の周辺機器を接続できる技術的なソリューションが最近登場しました(1)。
最新のHPCシステムでは、単一のハードウェアアクセラレータだけでは不十分です。 計算ノードのローカルPCI Expressバス上に2つのGPUボードが表示されるのはすでに慣例となっています。 GPU間のデータ交換を直接保証するために、GPUDirectテクノロジーが開発されました(2)。 このテクノロジーを使用すると、RAMをバッファーとして使用せずに、PCI Expressバスを介してGPUデバイス間でデータ交換を直接整理できます。これにより、データ転送のオーバーヘッドを大幅に削減できます。
PCI Expressバス上の複数のアクセラレータの他の例には、GPUとFPGAの両方を実行するシステムが含まれます。 最初の例では、オーストラリアの研究者チームが、Intelマザーボード、Core i7プロセッサ、nVidia Tesla C2070 GPUボード、およびStratix-IV FPGAチップがインストールされたアルテラDE-530ボードからパーソナルコンピューターを組み立てました(3)。 彼らは、古代ギリシャの神話上の怪物キメラに敬意を表して「チメラ」と名付けました。キメラには、3体の頭(ヤギ、ヘビ、ライオン)があります。 彼らはいくつかの問題(モンテカルロ法を使用した統合、2D配列のテンプレートの検索)を成功裏に解決し、連続重力波の解析のためにこのシステムの使用に取り組んでいます。 彼らのプロジェクトの主な特徴は、GPUとFPGAが同じタスクで同時に動作し、データがPCI Expressバスを介してGPUからFPGAに転送されることでした。 ただし、この交換は中央プロセッサの制御下にあり、RAMのバッファを介して行われたことに注意してください。
ブリュッセルの別のチームは、nVidia Tesla C2050 GPUとPico Computing EX-500 FPGAを備えたハイブリッドコンピューターを組み立てました(4)。 最後のボードには、1〜6個のザイリンクスVirtex6 FPGAを含めることができ、それぞれに独自のPCI Expressホストインターフェイスがあります。 プロジェクトの詳細はまだ明確ではなく、メッセージはプレプリントとしてのみ利用可能です。
最後に、Microsoftの開発者チームは、PCI Expressバスを介したGPUとFPGA間のデータ転送を直接調査しました(5)。 彼らのシステムには、1つのVirtex6チップを搭載したnVidia GeForce GTX 580 GPUとXilinx ML605 FPGAがインストールされました。 開発者は、CUDA API、GPUDirectテクノロジー、およびLinux FPGAデバイスドライバーを使用して、GPUとFPGA間の直接データ転送を開始する方法を発見しました。 これにより、RAMを中間バッファーとして使用するアプローチと比較して、データ転送の速度を向上させ、レイテンシーを削減することができました。 この場合、GPUがマスターであり、FPGAがスレーブでした。
PCI Expressバスを使用して、FPGA間で直接データを転送することもできます。 ザイリンクスはこの機能を実証しています(6)。 ザイリンクスのエンジニアは、スイッチを使用せず、中央処理装置を備えたコンピューターを使用せずに、PCI Expressバスを介して2つのFPGAを直接接続しました。 1つのチップがPCI Expressインターフェイスを個別に構成し、2番目のチップとの接続を確立して構成しました。 その後、2つのFPGAクリスタル間で両方向にデータを転送できました。 このアプローチは、PCI Expressバスを介してFPGA間でデータを転送する基本的な可能性を示していますが、複数のFPGAがPCI Expressスイッチを介して中央処理装置を備えたコンピューターに接続されている場合は使用できません。
この記事では、PCI Expressバス上の多くのFPGAを含むシステムでのデータ転送について説明します。 システムメモリと複数のFPGA間での同時データ転送の問題、および複数のFPGA間で相互に直接データを同時に転送する問題について説明します。 私たちの知る限り、このメッセージは、コンピューターのPCI Expressバスを介したFPGA間でのデータ転送を説明する最初のメッセージです。
システムの説明
実験は次のシステムで実施されました。 Intel Core i7プロセッサーを搭載したマザーボードでは、Rosta(1)製のRHA-25アダプターがPCI Express 2.0 x8コネクターに取り付けられ、ケーブル接続を介してPCI Expressバスを拡張します。 PCI Expressスイッチ(PLXテクノロジー)がRHA-25アダプターにインストールされ、その3つのポートが外部接続に使用されます:1つのx8 Gen 3.0ブレードアップストリームポートと2つのx4 Gen 3.0ケーブルダウンストリームポート。 RB-8V7コンピューティングユニット(1)は、2つのケーブル接続PCI Express x4 Gen 3.0を介してこのシステムに接続されました。 RB-8V7ユニットは対称アーキテクチャを備えており、2つのRC-47ボードで構成されています。 各RC-47カードには、1つのケーブルアップストリームポートと4つのダウンストリームポートを備えたPLX PCI Expressスイッチがあり、それぞれがXilinx Virtex-7 FPGA(XC7V585T)に接続されています。 したがって、システムでは、8つのVirtex-7(V7)FPGAが1つのRHA-25アダプターを使用してPCI Expressバス経由でホストに接続されました。 PCI Express x4 Gen 2.0を介してPLXスイッチに接続されたすべてのFPGA。
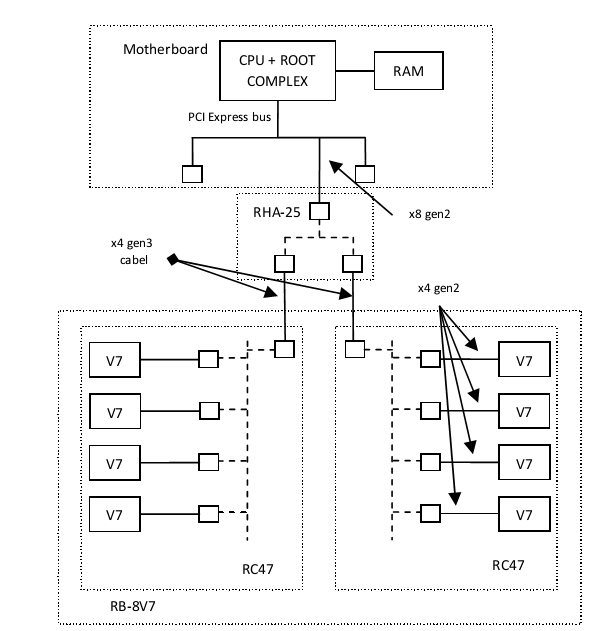
図 1ハードウェア。 RB-8V7ユニットは、ケーブルPCIe接続とRHA-25アダプターを介してホストコンピューターに接続されます。
FPGA内では、次のスキームが実装されました(図2)。 このプロジェクトでは、ザイリンクスのPCI Express IPコアを使用しています(7)。 Rosta DMA Engineブロックは、PCI Expressバス上のデバイスの機能を決定します。 FPGAはマスターまたはスレーブとして機能できます。 スレーブデバイスとして、FPGAは中央プロセッサにそのレジスタへの読み取りおよび書き込みアクセスを提供します。また、EP_RX_FIFOキューに受信データを格納しながら、バス上の他のデバイス(たとえば、他のFPGA)から大きなデータパケットを受信できます。 FPGAはマスターデバイスとして、DMA(読み取り/書き込み)モードでコンピューターのRAMにアクセスできます。 この場合、メモリに書き込む場合、データはTX_FIFOから読み取られ、メモリから読み取る場合、RX_FIFOに書き込まれます。 デバイスは、バス上の任意のアドレスで書き込みトランザクションを生成することもできます(たとえば、他のFPGAにデータを転送するため)。この場合、送信するデータはEP_TX_FIFOキューから読み取られます。 RX_STATE_MACHINEサブマシンガンは着信パケットの受信を担当し、TX_STATE_MACHINEサブマシンはパケットの送信を担当します。 パケットの受信と送信は同時に行われます。 TX_ARBITERブロックは、送信のために送信するパケットを次のように決定します:中央プロセッサによるレジスタの読み取り中に応答の生成に絶対優先順位が与えられ、残りのパケット(ランダムアクセスメモリの読み取り/書き込み要求または任意のアドレスへの書き込み要求)は同じ優先順位(ラウンドロビン)で計画されます。
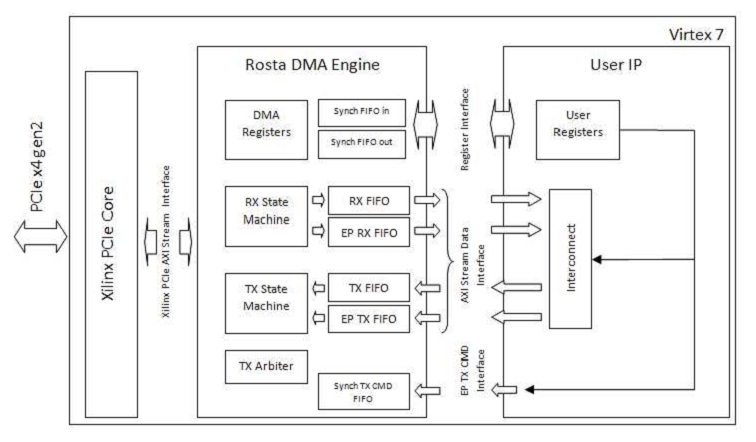
図 2 FPGAプロジェクトのブロック図
(DMA_REGISTERSブロックへの書き込みによる)中央処理装置は、FPGAとRAM間のDMAデータ転送のプログラミングに従事し、別のFPGAの任意のアドレスへのデータ書き込みプロセスを制御するための内部EP TX CMDハードウェアインターフェイスがあります。 ユーザーIPブロックのユーザーレジスタへのアクセスには、レジスタインターフェイスがあり、PCI Expressスペースとユーザー回路間のブロックデータ転送には、RX_FIFO、TX_FIFO、EP_RX_FIFO、EP_TX_FIFOキューに接続された4つのAXIストリームインターフェイスがあります。 最後に、PCI Expressザイリンクスコアに向けて、Rosta DMA Engineは幅64ビットのザイリンクスPCIe AXIストリームインターフェイスをサポートします。 ユニットは2つのクロック周波数で動作します。ザイリンクスコアPCIe周波数(250 MHz)の回路の左側と、任意のユーザー周波数の回路の右側です。 周波数分離は、FIFOキューを介して行われます。 ただし、以下で説明するすべての実験では、ユーザー周波数はPCIeコアが動作する周波数(250 MHz)と等しくなりました。
ユーザーIPブロックは、アプリケーションレベルでのデバイスの動作を定義します。 この作業では、さまざまな目的のためにいくつかの異なるスキームが使用されました。
まず、回路を使用して、FPGAとRAM間のデータ転送の正確性を検証しました。 この場合、インターコネクトブロックでは、出力RX_FIFOは入力TX_FIFOで単純に閉じられます。 これにより、RAMから読み取られたデータとまったく同じデータをRAMに書き込むことができました。 中央処理装置(以降、単にホスト)上のプログラムは、FPGAにデータを書き込み、それらを読み取り、比較し、データが正しく比較されたことを確認しました。
次に、回路を使用して、FPGAとRAM間の両方向の最大データ転送速度を測定しました。 このため、RX_FIFOから、データは常に読み込まれました。 キューは常に空であり、オーバーフローによるデータ受信の遅延はなく、TX_FIFOは絶えずデータを書き込んでいました。 キュー内のデータの不足による送信の遅延はありませんでした。
第三に、FPGA間の直接データ転送の正確性を検証するスキームが開発されました。 Interconnectブロックでは、出力RX_FIFOおよびEP_RX_FIFOと入力TX_FIFOおよびEP_TX_FIFOの回路が実装されました。 最初のケースでは、出力RX_FIFOが入力TX_FIFOに対して閉じられ、出力EP_RX_FIFOが入力EP_TX_FIFOに対して閉じられました。 2番目のケースでは、出力RX_FIFOが入力EP_TX_FIFOに対して閉じられ、出力EP_RX_FIFOが入力TX_FIFOに対して閉じられました。 この回路は、ユーザーレジスタの1つからのビットによって制御されました。 EP TX CMDインターフェイスを制御するために、ユーザーレジスタブロックにレジスタが追加されました。 この場合、ホスト自体がFPGA間のデータ転送を制御しましたが、一般にEP TX CMDインターフェイスはFPGA回路自体がデータ転送を開始できるように設計されました。
第4に、FPGA間の最大データ転送速度を測定するために、データを送信するときは常にEP_TX_FIFOにデータを送信し、データを受信するときはEP_RX_FIFOからデータを常に読み取る特別なスキームが開発されました。 同時に、回路内にハードウェアタイマーが実装され、その値が保存されてからホストに送信されました。 EP TX CMDインターフェイスは、ユーザーレジスタを介してホストによって制御されていました。
最後に、レイテンシを測定するために、データを別のFPGAに転送する回路が使用されました。 受信したFPGAデータはすぐに同じデバイスに書き戻しました。 送信FPGAでは、転送の開始と同時にハードウェアタイマーが起動され、データがEP_RX_FIFOキューに入るようになった瞬間に停止しました。 さらに、タイマー値はユーザーレジスタを介してホストに読み込むことができます。
Linuxがホストにインストールされました。 独自の設計のドライバーとライブラリを使用して、機器を操作しました。
PCI Expressバス帯域幅
データ転送速度の測定に関する実験の説明に進む前に、その理論的な限界を見つける必要があります。 8B / 10Bコーディングの使用により、2.5 GHz(gen1)の周波数での単一PCI Expressラインの最大理論データレートはV_theory = 2.0 Gbit / sであることが知られています。 周波数が5 GHzのGen 2.0の第2世代プロトコルの場合、この速度は2倍になります(V_theory = 4.0 Gbit / s)。 第3世代の情報転送速度は2倍高く、1行あたりV_theory = 8.0 Gbit / sです(周波数は8 GHzですが、第3世代のプロトコルは、追加の負荷を削減する別の128B / 130B文字エンコード方式を使用します)。
ただし、データは追加情報(開始/停止ビット、ヘッダー、チェックサムなど)を含むパケットで送信されるため、データはわずかに低い速度で送信されます。 その結果、書き込みトランザクションの1つのパケットを送信する場合、データに加えて、同じパケットに関連する追加の20バイトが送信されます。 また、データはまったく含まれていないが、純粋にサービス機能を実行するパケットがPCI Expressバスを介して送信されます。 これには、データパケットの受信の確認、チェックサムの不一致が発生した場合に送信を繰り返す要件、スイッチの空き領域バッファーのカウンターを更新するパケットなどが含まれます。 データ転送速度への影響を正確に評価することは困難です(これは特定の実装に依存します)が、平均して、それらの寄与は1データパケットあたり3バイト追加として概算できます(8)。 合計で、単一のデータパケットを送信するために平均23の追加サービスバイトが送信されることを受け入れます。 これについては、(8)で詳しく説明します。 将来的には、特に指定のない限り、パケットの長さとは、パケット内のデータ量を意味します。
PCI Expressバスでは、異なる長さのパケットでデータを送信できます。 1つのパケットを送信するときの最大データ量は、パラメーターMAX_PAYLOAD_SIZEによって決まります。その値は2の累乗に等しくなります。 各デバイスにはパラメーターMAX_PAYLOAD_SIZE_SUPPORTEDがあり、このパラメーターはこのデバイスが送信できる最大パケットサイズを決定します。 構成ソフトウェア(BIOSプログラム)は、システム内のすべてのデバイスのMAX_PAYLOAD_SIZEパラメーターを、システム内のデバイスでサポートされている最小値に設定します。 原則として、最新のチップセットは最大128バイトのパケットサイズをサポートしていますが、256バイトのシステムがあります。 私たちの実験では、MAX_PAYLOAD_SIZE_SUPPORTEDチップセットパラメーターは128バイトでした。RHA-25およびRC-47ボード上のFPGAおよびPCI Expressスイッチは大きなパケットサイズ(最大512)をサポートしていましたが、BIOSはすべてのデバイスのMAX_PAYLOAD_SIZEパラメーターを設定しました128バイトに等しいシステム。
送信パケットのサイズが大きいほど、帯域幅は情報転送の理論上の限界に近づきます。 理論的な制限が1である場合、次の式に従って、パケットのサイズに応じてデータ転送の実際的な制限を計算できます(表1を参照)。
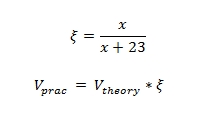
ここで、xはパケットサイズです。

表1.相対データレートとパケットサイズ
表の中。 図2は、パケット長が128バイトと256バイトの場合の最大の理論的および実用的なデータ転送速度の比較を示しています。
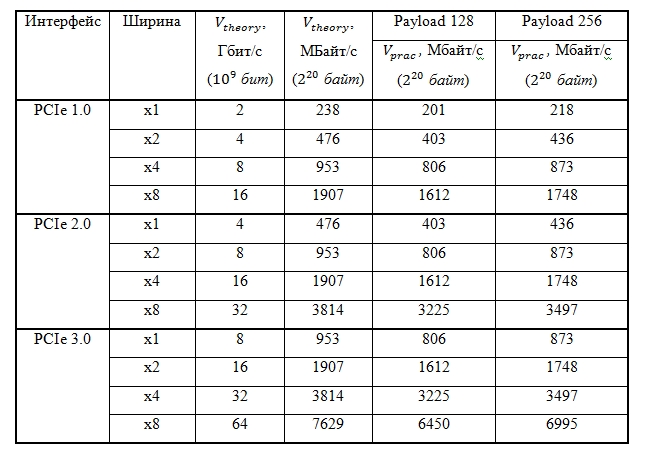
表2. 128および256バイト長のパケットに対するPCI Expressバス上の情報およびデータの最大転送速度
HOST-FPGA伝送
FPGAとシステムメモリ間でデータを転送する場合、ダイレクトメモリアクセスメカニズムが使用されます。 ホスト上のユーザーアプリケーションは、RAMにバッファーを準備し、書き込みまたは読み取りシステムコールを行います。 PCI Expressデバイスドライバーは、メモリ内のユーザーバッファーページをキャプチャし、スキャッター/ギャザーDMAメカニズムを使用します。 ページの記述子のリスト(アドレスと長さのペア)はFPGAデバイスの内部メモリに書き込まれ、FPGA自体はこのリストのアドレスによってアクセスされます。 データ転送が完了すると、FPGAは割り込みを生成し、システムコールが完了します。 ユーザーアプリケーションがFPGAにデータを書き込む場合、デバイスは読み取りトランザクションでRAMに接続し、FPGAから読み取る場合、デバイスは書き込みトランザクションを生成します。 以下、「記録」および「読み取り」という言葉はFPGAを指すことを意味します。 書き込み速度とは、FPGAによって開始される記録プロセスの速度を指します。
PCI Expressバスで生成された書き込みトランザクションは常に単方向です。 書き込みトランザクションイニシエーターは、ヘッダーとデータで構成されるパッケージを形成します。 イニシエーター自身が、MAX_PAYLOAD_SIZEの制限のみを考慮して、データのサイズを決定します。 前の段落でデータ転送速度について述べられたことはすべて、特に書き込みトランザクションに関連しています。 書き込みトランザクションの場合、データ転送速度は理論的に簡単に推定でき、送信パケットのサイズへの依存性を測定できます。
読み取りトランザクションでは、事態はもう少し複雑です。 読み取りトランザクションのイニシエーターは、最初に読み取り要求(ヘッダーのみで構成される短いパケット)を生成します。 このパッケージは、どこから(どのアドレスから)どれだけのデータを読み取るかを示します。 一度に要求できるデータの最大量は、MAX_READ_REQUEST_SIZEパラメーターによって決まり、通常は4 KBです。 通常、周辺機器はRAMで読み取り要求を行いますが、別のデバイスからデータを要求できます。 デバイス(周辺またはRAMコントローラー)が読み取り要求を受信すると、最初にそのメモリーから必要なデータを要求し、それをPCI Expressバス経由でトランザクションイニシエーターに返し、応答完了パケットを生成します。 同時に、MAX_PAYLOAD_SIZEの制限のみを考慮して、返されるパケットのサイズを決定します。 トランザクションイニシエーターは、返されるパケットのサイズに影響を与えることはできません。 通常、RAMコントローラーはMAX_PAYLOAD_SIZEに等しいデータ長のパケットを返します。
読み取りトランザクションのデータ転送速度は、いくつかの理由により評価が困難です。 最初に、反対方向に移動する2種類のパケットが生成されます-読み取り要求と最終応答。 第二に、データ転送速度は、RAMからの読み取り時に発生する遅延の影響を受けます。 最後に、パケット内のデータ量に対するデータレートの依存関係を追跡する方法は不明です。 したがって、この作業では、最初の読み取り要求を送信してからデータの最後のバイトが到着するまでの積分時間を単純に測定し、それを使用してRAMからのデータの読み取り速度を計算し、パケットサイズへの依存関係を追跡しませんでした。
PCI Expressバスは、トランザクションレベルで信頼性の高いデータ転送を提供します。つまり、データを送信することにより、エージェント(端末デバイスと中間スイッチ)は自動的にパケットのチェックサムを計算し、パケット自体のエンコードされたものと比較し、送信エラーが検出された場合は再送信を要求しますデータ。 ただし、これは、ホストアプリケーションまたはFPGAスキームがプログラマエラーの結果として不正なデータを生成および送信できないことを意味するものではありません。 そのため、アプリケーション、ドライバー、FPGA回路を含む回路の正確性を検証するために、データ転送の正確性をチェックしました。 このため、最初のユーザーIPスキームが使用されました。このスキームでは、RX_FIFO出力がTX_FIFO入力に対して閉じられていました。 FIFOキューのサイズは4 KBでした。 2つの実験が行われました。 最初に、ホストは4 KBのデータをFPGAに連続して記録し、次にそれを読み取って比較しました。 2番目の実験では、FPGAとデータを送受信するパスが並行して機能するという事実を使用しました。 ホストは最初に書き込み操作と読み取り操作の両方をプログラムし、次にFPGAはRAMからデータの読み取りを開始し、RX_FIFOに到達してすぐにTX_FIFOに到達するとすぐに、RAMへの書き戻しを開始しました。 これにより、RX_FIFOおよびTX_FIFOキューのサイズ(実験では4 MB)と比較して、一度にはるかに大量のデータを転送できました。 両方の実験で、送信データと受信データの比較に成功し、回路の正しい動作を判断することができました。
データ転送速度の測定に関する実験は、1つのFPGAデバイスのRAMへの書き込み速度の、送信パケット内のデータのサイズへの依存性の測定から始まりました。 8、16、32、64、および128バイトのペイロード値で実験が行われました。 各実験では、4 MBが一方向に転送されました。 Virtex7-RAMパスのボトルネックは、FPGAとRC47ボード上のPCI Expressスイッチ間のPCI Express x4 Gen 2.0接続でした(図1を参照)。 結果を図に示します。 3.上部のVtheory曲線は、達成可能な最大データ転送速度の理論上の依存性(式1)をパケット長に表しています(PCI Express x4 Gen 2.0インターフェイスの場合)。 Vhardの中央の曲線は、FPGAのハードウェアタイマーを使用して測定された速度を表し、PCI Expressバス上の直接データ転送のみを考慮します(データの最初のパケットの送信の開始から最後の転送の終了までの時間を測定しました)。 最後に、Vapp曲線は、ホスト上のアプリケーションで測定された速度を表します(読み取りシステムコールの実行時間が測定されました)。
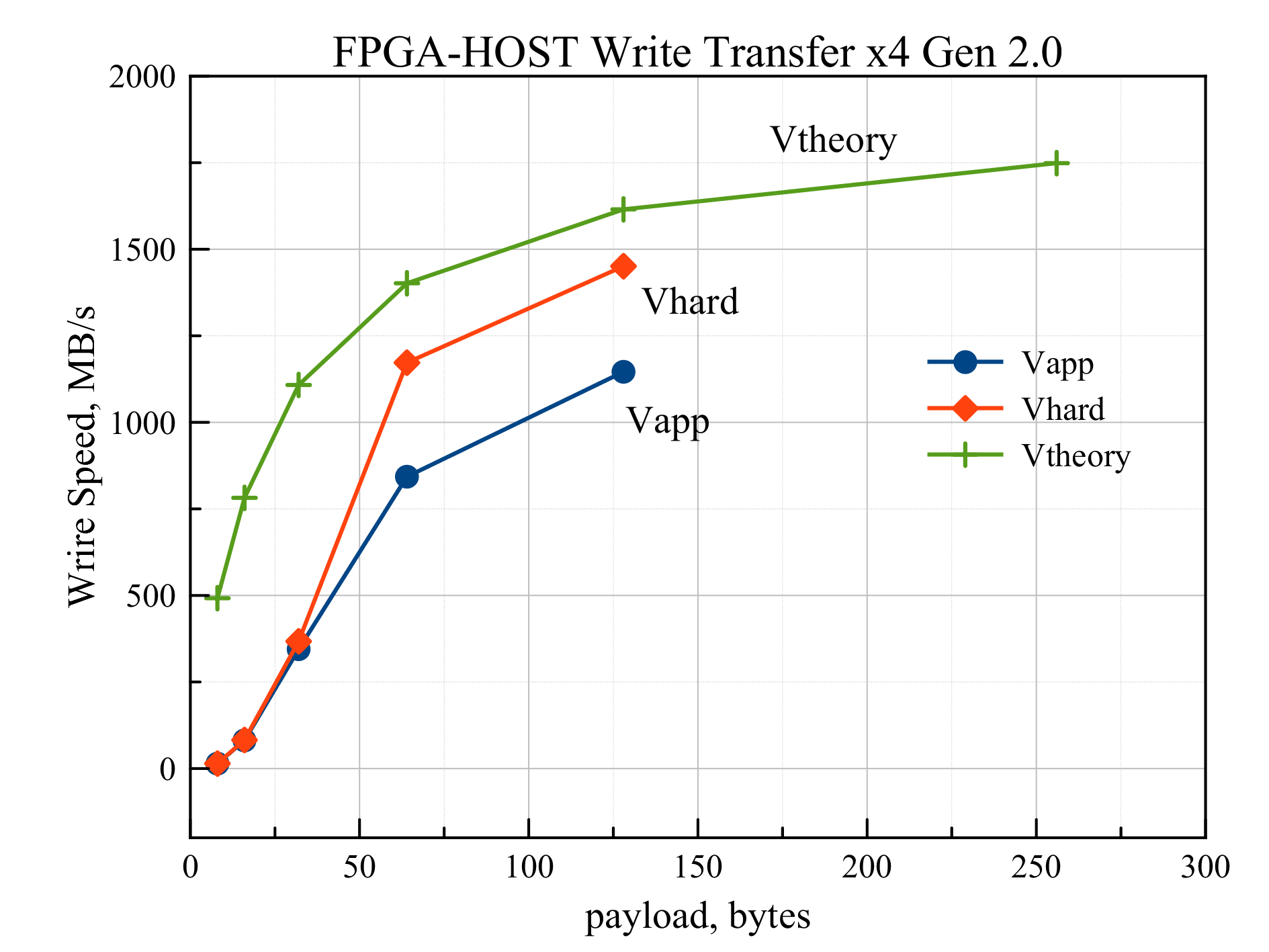
図 3インターフェースPCI Express x4 Gen 2.0のパケット長に対するRAMの書き込み速度の依存性
このグラフは、ペイロード値が64バイト未満の場合、VhardおよびVappの速度がVtheoryよりもはるかに遅いことを示しています。 これは、この場合、DDR RAMメモリがデータレシーバーとして機能し、バーストモードでのみ高い書き込み速度を提供し、1つのトランザクションで大量のデータを転送するためです。 128バイトのパケットの場合、Vhard = 1451 MB / s、これは1612 MB / sの最大値の90%です。 また、Vappアプリケーションで測定された速度(ペイロード= 128で1146 MB / s)は、64バイトから始まるペイロード値のVhardよりもはるかに低いことがわかります。 これは、4 MBのデータを送信すると、約1000ページの記述子が形成され、プロセッサがFPGAに書き込むためです。 この初期遅延(1ミリ秒のオーダー)は、データレートに大きく影響します。 ペイロード= 128バイトの読み取りシステムコールの合計実行時間は約3.7ミリ秒です。 この時間から1 msの初期遅延を取り除いた場合、ハードウェアで測定されたVhard速度と一致する1450 MB / sにほぼ等しい速度が得られます。
私たちの計画には、ドライバー転送とRosta DMA Engine回路を変更して、DMA転送のプログラミング時の初期遅延を減らすことが含まれています。 改善のアイデアは、ユーザーバッファーのページ記述子のリスト全体をFPGAに転送するのではなく、RAM内のFPGAにアクセス可能な領域に保存することです。 その後、FPGA自体がRAMから記述子を読み取ることができ、そのデータは既に送信されます。 メモリから記述子を読み取るプロセスと実際のデータ転送を並行して開始できるため、初期遅延が大幅に削減され、その結果、データ転送速度が向上します。 それまでは、ハードウェアで測定される速度に焦点を当てます。 また、後続の実験では、ペイロードが128バイト未満のデータ転送は調査されません。
次の実験では、異なるFPGAを含む複数のデータ送信が同時に開始されました。ホスト上のアプリケーションが複数のpthreadスレッド(個別の送信ごとに1つのスレッド)を開始しました。各スレッドで、FPGAは最初にRAMからの読み取り用にプログラムされ、次に書き込み用にプログラムされました。同時送信は、アプリケーションでバリア同期を使用して実現されました。送信されたバッファのサイズは4 MBで、記録中のパケットのサイズは128バイトでした。実験には、RB-8V7ユニットに含まれる8つのVirtex7 FPGAデバイスすべてが含まれます。同時FPGAの数に応じたRAM内のデータの書き込み速度を図に示します。4。
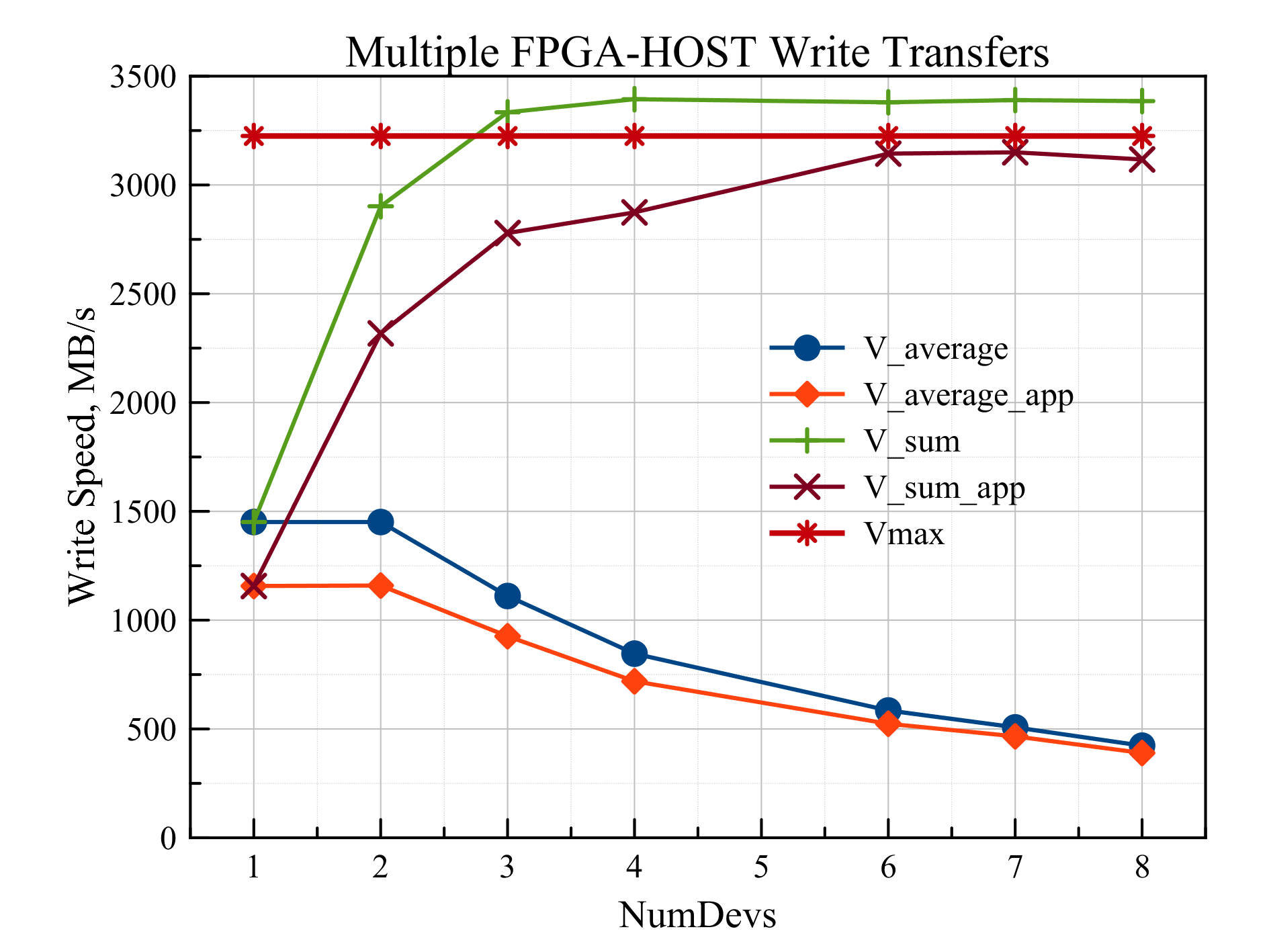
図 4 RAMの書き込み速度の同時トランザクション数への依存
下の2つの曲線(V_averageとV_average_app)は、それぞれハードウェアとアプリケーションで測定された平均書き込み速度を示しています。個々のFPGAは、PCI Express x4 Gen 2.0インターフェイス(この場合は1451 MB / s)を介して、最大書き込み速度に制限されています。 V_sumおよびV_sum_app曲線は、個々のデバイスのデータレートの合計です。直接Vmax = 3225 MB / sは、システムのボトルネックを介した最大データ転送速度を表し、同時データ転送の速度を制限します。このようなボトルネックは、PCI Express x8 Gen 2.0アダプターRHA-25のコンピューターマザーボードへの接続です。 1回と2回の同時転送では、2回の転送の合計速度がVmax未満であるため、書き込み速度は同じです(1451 MB / s)。 3つのギアから始めて、個々のデバイスの記録速度が低下し、ただし、合計速度はVmaxと同じです。グラフ上で3つ以上のデバイスの合計速度がVmaxを超えるという事実は、データ送信の「疑似同時性」によって説明されます。スレッドが中央プロセッサのコア間でどれだけ並列に分散されていても、PCI Expressバスコマンドは引き続き連続して実行されます。したがって、一部のデバイスはより早く送信を開始し、他のデバイスは後で送信を開始します。これにより、データ転送の開始時と終了時に短時間、アダプタとマザーボードの共通接続チャネルが転送に関与するすべてのデバイスによって使用されないという事実につながります。したがって、それらの場合、伝送速度が大きくなり、すべての速度の合計が最大値を超えます。実際には、共通チャネルは100%で使用され、帯域幅は等しいシェアのデバイス間で共有されます。グラフでは、データ転送の「疑似同時性」のために、3つ以上のデバイスの合計速度がVmaxを超えています。スレッドが中央プロセッサのコア間でどれだけ並列に分散されていても、PCI Expressバスコマンドは引き続き連続して実行されます。したがって、一部のデバイスはより早く送信を開始し、他のデバイスは後で送信を開始します。これにより、データ転送の開始時と終了時に短時間、アダプタとマザーボードの共通接続チャネルが転送に関与するすべてのデバイスによって使用されないという事実につながります。したがって、それらの場合、伝送速度が大きくなり、すべての速度の合計が最大値を超えます。実際には、共通チャネルは100%で使用され、帯域幅は等しいシェアのデバイス間で共有されます。グラフでは、データ転送の「疑似同時性」のために、3つ以上のデバイスの合計速度がVmaxを超えています。スレッドが中央プロセッサのコア間でどれだけ並列に分散されていても、PCI Expressバスコマンドは引き続き連続して実行されます。したがって、一部のデバイスはより早く送信を開始し、他のデバイスは後で送信を開始します。これにより、データ転送の開始時と終了時に短時間、アダプタとマザーボードの共通接続チャネルが転送に関与するすべてのデバイスによって使用されないという事実につながります。したがって、それらの場合、伝送速度が大きくなり、すべての速度の合計が最大値を超えます。実際には、共通チャネルは100%で使用され、帯域幅は等しいシェアのデバイス間で共有されます。データ送信の「疑似同時性」のため。スレッドが中央プロセッサのコア間でどれだけ並列に分散されていても、PCI Expressバスコマンドは引き続き連続して実行されます。したがって、一部のデバイスはより早く送信を開始し、他のデバイスは後で送信を開始します。これにより、データ転送の開始時と終了時に短時間、アダプタとマザーボードの共通接続チャネルが転送に関与するすべてのデバイスによって使用されないという事実につながります。したがって、それらの場合、伝送速度が大きくなり、すべての速度の合計が最大値を超えます。実際には、共通チャネルは100%で使用され、帯域幅は等しいシェアのデバイス間で共有されます。データ送信の「疑似同時性」のため。スレッドが中央プロセッサのコア間でどれだけ並列に分散されていても、PCI Expressバスコマンドは引き続き連続して実行されます。したがって、一部のデバイスはより早く送信を開始し、他のデバイスは後で送信を開始します。これにより、データ転送の開始時と終了時に短時間、アダプタとマザーボードの共通接続チャネルが転送に関与するすべてのデバイスによって使用されないという事実につながります。したがって、それらの場合、伝送速度が大きくなり、すべての速度の合計が最大値を超えます。実際には、共通チャネルは100%で使用され、帯域幅は等しいシェアのデバイス間で共有されます。PCI Expressバスでは、コマンドは引き続き順番に実行されます。したがって、一部のデバイスはより早く送信を開始し、他のデバイスは後で送信を開始します。これにより、データ転送の開始時と終了時に短時間、アダプタとマザーボードの共通接続チャネルが転送に関与するすべてのデバイスによって使用されないという事実につながります。したがって、それらの場合、伝送速度が大きくなり、すべての速度の合計が最大値を超えます。実際には、共通チャネルは100%で使用され、帯域幅は等しいシェアのデバイス間で共有されます。PCI Expressバスでは、コマンドは引き続き順番に実行されます。したがって、一部のデバイスはより早く送信を開始し、他のデバイスは後で送信を開始します。これにより、データ転送の開始時と終了時に短時間、アダプタとマザーボードの共通接続チャネルが転送に関与するすべてのデバイスによって使用されないという事実につながります。したがって、それらの場合、伝送速度が大きくなり、すべての速度の合計が最大値を超えます。実際には、共通チャネルは100%で使用され、帯域幅は等しいシェアのデバイス間で共有されます。データ転送の開始時と終了時に短期間、アダプタとマザーボード間の共通接続チャネルが転送に関与するすべてのデバイスによって使用されるわけではありません。したがって、それらの場合、伝送速度が大きくなり、すべての速度の合計が最大値を超えます。実際には、共通チャネルは100%で使用され、帯域幅は等しいシェアのデバイス間で共有されます。データ転送の開始時と終了時に短期間、アダプタとマザーボード間の共通接続チャネルが転送に関与するすべてのデバイスによって使用されるわけではありません。したがって、それらの場合、伝送速度が大きくなり、すべての速度の合計が最大値を超えます。実際には、共通チャネルは100%で使用され、帯域幅は等しいシェアのデバイス間で共有されます。
同様に、RAMから読み取る場合を考えることができます(図5)。
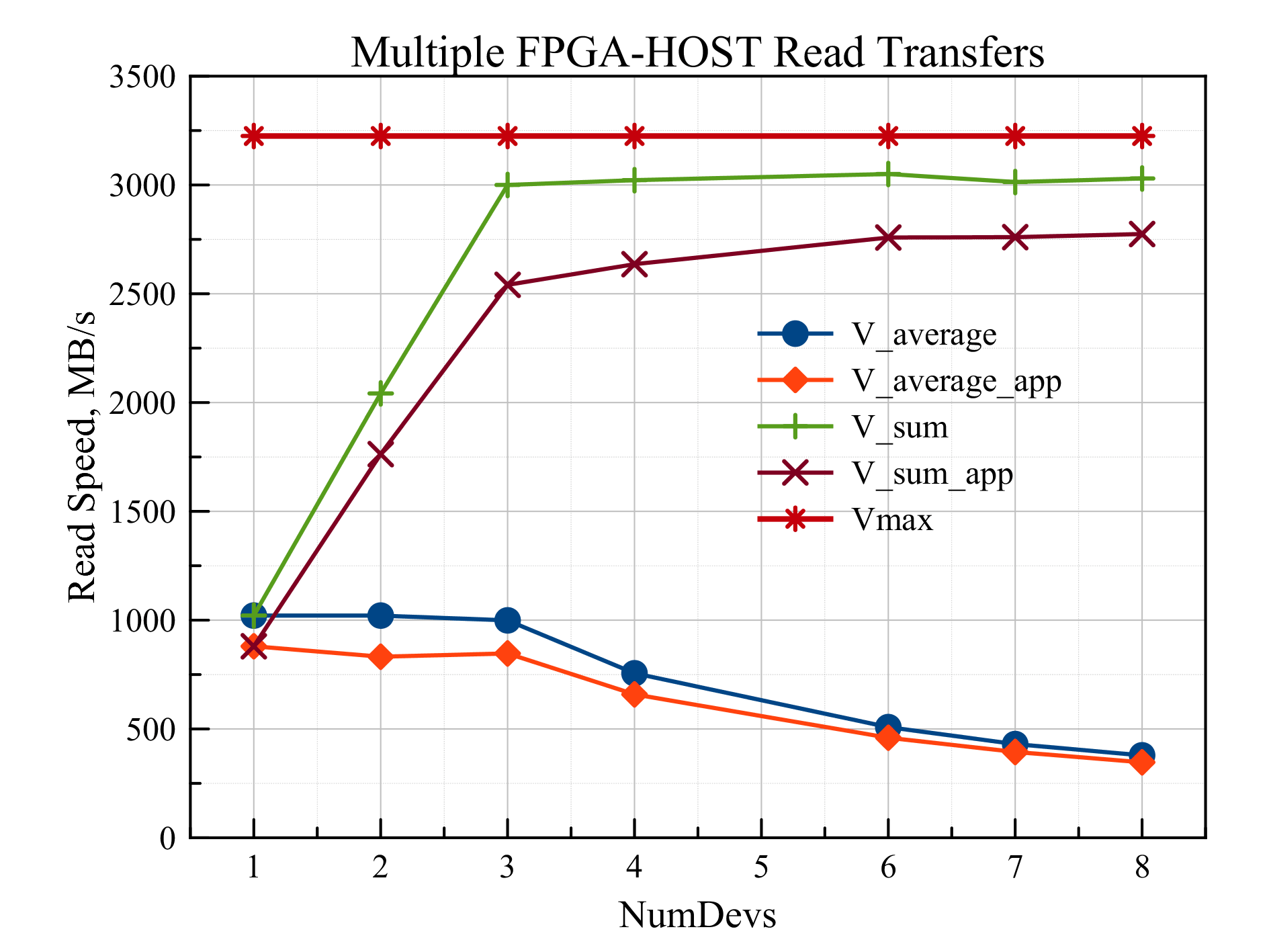
図5 RAMからの読み取り速度の同時トランザクション数への依存
ここでは、1〜3台のデバイスを含むデータ転送の場合、各デバイスの読み取り速度は同じで、1000 MB / sに等しいことがわかります。4つのデバイスから開始すると、速度はホストとの通信チャネルの帯域幅によって制限されます。
伝送FPGA-FPGA
PCI Expressバス上のメモリの書き込みおよび読み取り要求は、パケットヘッダーにエンコードされたアドレスに従って送信されます。マスターは、任意のアドレスを持つパケットを生成できます。このアドレスは、RAM内を示す場合もあれば、別の周辺機器に割り当てられたアドレスの領域に属する場合もあります。後者の場合、要求パケットは1つのデバイスから別のデバイスに送信されます。この場合、異なるFPGA間で書き込み要求が送信されました。読み取りテストは実行されませんでした。
各FPGAは、BIOSまたはオペレーティングシステムから、このデバイスにアクセスできるアドレスの範囲を受け取ります。 FPGA AからFPGA Bへのデータ転送をプログラムするには、ホストのアプリケーションがFPGA BのベースアドレスをFPGA Aに通知する必要があります(ユーザーIPブロックの対応するレジスタに書き込みます)。RostaDMA EngineのFPGAでは、ハードウェアインターフェイスEP EP CMDが実装されました。回路内から別のFPGAへのデータ転送を開始します。回路は、送信用のデータをEP_TX_FIFOに書き込み、EP TX CMDインターフェイスを介して他のデバイスのベースアドレスと送信長を送信します。次に、Rosta DMA EngineブロックのTX_STATE_MACHINE送信マシンは、EP_TX_FIFOから指定されたアドレスへのデータ送信を開始します。受信FPGAでは、データはEP_RX_FIFOキューに書き込まれます。
まず、FPGA間のデータ転送の正確性を検証する必要がありました。このために、次の実験が行われました。伝送には、RB-8V7ブロックの一部である8つのVirtex7 FPGAすべてのシーケンスが含まれていました(図6)。
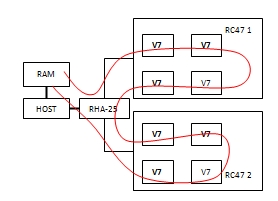
図 6データ伝送方式HOST-FPGA-HOST
最初の7つのFPGAでは、ホストは次のスキームに従ってデバイスのベースアドレスを記録しました。最初のデバイスでは-2番目のベースアドレス、3番目では-3番目、というように。ホストは、RAMからデータを読み取り、読み取ったデータを2番目のデバイスに転送するように、最初のデバイスをプログラムしました。これを行うために、ユーザーIPでは、ユーザーIPレジスタを介したインターコネクトスイッチングユニットが、出力RX_FIFOを入力EP_TX_FIFOに接続するように構成されました。デバイス2〜7は、チェーン内の次のデバイスにデータを転送するように構成されました。それらでは、EP_RX_FIFOを入力EP_TX_FIFOに接続するようにインターコネクトブロックが構成されました。最後に、8番目のデバイスは、EP_RX_FIFOで受信したデータをTX_FIFO経由でRAMに送信するようにプログラムされました。転送後、ホストはデータを比較しました。この実験では、パスのデータレートも測定しました。これは、1つのFPGAデバイスでRAMから読み取る速度と同等でした。
データ転送が正しいことを確認した後、速度の測定に進むことができました。チップセットでサポートされる最大パケット長は128バイトであったため、システム内のすべてのスイッチと端末のMAX_PAYLOAD_SIZEパラメーターは128バイトに設定されていました。そのため、デフォルトでは、FPGA間のデータ伝送は同じ長さのパケットで行われていました。ただし、RC-47ボードとRHA-25アダプターにある中間のPCI Expressスイッチ、およびFPGA内のPCI Expressインターフェイスは、256バイトのパケット長をサポートしていることが確認されました。同時に、チップセット自体はFPGA間のデータ転送に参加しませんでした。 256に等しいFPGA-FPGAデータパス内のすべてのデバイスに対してMAX_PAYLOAD_SIZEを設定すると、事実にもかかわらず、256バイト長のパケットの送信を開始できることが示唆されました。チップセットは128のみをサポートします。
Linuxを使用してMAX_PAYLOAD_SIZEパラメーターを変更するには、setpciコマンドを使用して、RHA-25およびRC-47ボード上のすべてのデバイスとスイッチポートのPCI Expressデバイス制御レジスタに書き込みます。 Rosta DMA Engineブロックも変更され、256バイトのパケットを生成できるようになりました。その後、パンケーキパケット256からのデータ転送を整理することが実際に可能になり、データ転送速度が向上しました。
FPGA-FPGAの記録速度の測定は、異なる数の同時送信に対して実行されました。結果を表3に示します。

表3. FPGA-FPGAの記録速度の、128および256バイトのパケット長での同時送信数への依存。
最初の4つのケースでは、同じRC47ボード上のデバイス間で転送が行われました。1回のデータ転送中に最大書き込み速度が得られ、128バイトのパケット長で1603 MB / s、256バイトのパケット長で1740 MB / sに達しました。どちらの場合も、速度は対応するパケット長の最大値の99%でした。
ケース8.1および8.2のデバイスインタラクションスキームを図に示します。 7。
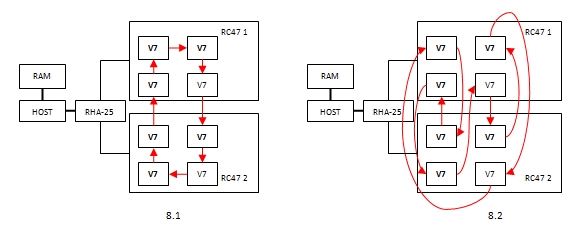
図 8つの同時転送の場合の7つのFPGA相互作用
ケース8.1では、データはFPGAからFPGAに順番に送信されました。最初に一方のボードで円を描き、次に外部ケーブル接続とRHA-25アダプターを介して、もう一方のボードのFPGAに送信が続きました。 2番目のボードでは、データは1つのFPGAから別のFPGAに順次コピーされ、最初のFPGAに返されました。その結果、RHA-25アダプターを介して、各側に1つのデータ伝送が行われ、PCI Express x4 Gen 3.0ケーブル接続は速度を制限しませんでした。ケース8.2では、データは1つのFPGAから別のFPGAに転送されましたが、別のボードに配置されていました。その結果、RHA-25アダプターを介して、各方向に4つずつ、8つの同時送信が行われました。パケット長が128バイトの場合、一方向の一般的なデータフローの速度は4 * 1520 = 6080 MB /秒で、PCI Express x4 Gen 3.0チャネルの最大速度である3225 MB /秒を超えています。したがって、チャネル速度はデバイス間で均等に分割される必要があり、各ペアの平均データ転送速度は3225/4 = 806 MB / sになります。これは、808 MB / sの測定値によって確認されます。したがって、ボード間の通信チャネルは100%エンゲージされていると言えます。 256バイトの長さのパケットを送信する場合も、同様の推論を行うことができます。
最後に、データ伝送遅延を測定するための実験が行われました。実験のアイデアは次のとおりです。 FPGA AはデータをFPGA Bに送信し、ハードウェアタイマーを開始します。異なるデバイスのクロックは同期が難しいため、タイマーはFPGA Aでのみ使用されます。FPGABはデータを受信するとすぐにFPGA Aへの書き込みを開始します。FPGAAはデータの最初のバイトを受信するとすぐにタイマーを停止します。タイマー値は、1つのFPGAのユーザーIPブロックと他のFPGAのユーザーIPブロック間のデータ転送のレイテンシが2倍になることを表します。レイテンシは2つのケースで測定されました。1つのRC-47ボード上のFPGA間(図8 A)および異なるボード上のFPGA間(図8 B)での伝送中です。
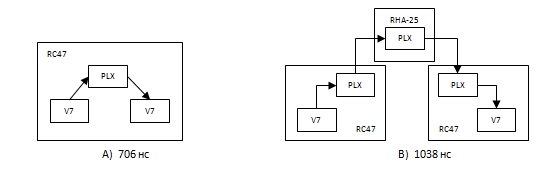
図8レイテンシを測定するためのデータ送信スキーム
同じRC-47ボード上のデバイス間でデータを送信する場合、送信パスに1つのPLXスイッチがあり、遅延は706 nsでした。ボード間を転送する場合、3つの中間スイッチがあり、遅延は1038 nsでした。このデータから、FPGAで発生し、スイッチによって導入される遅延を判断できます。受信および送信時のFPGAの遅延は270 nsに、スイッチ166 nsに等しくなります。これは、PLXテクノロジーが150 nsで宣言したスイッチのレイテンシとよく一致しています。
おわりに
このペーパーでは、複数のFPGAが同時に参加するPCI Expressバスを介したデータ転送について説明しました。 RAMに書き込むとき、PCIe x4 Gen 2.0接続の最大の90%に等しい速度が、128バイト(1451 MB / s)のパケット長で得られました。 RAMから読み取る場合、速度は1000 MB / sでした。 FPGA-HOST同時送信の場合、同時送信の数がホストとの狭い通信チャネルを飽和させるまでデータ転送速度は低下せず、チャネルは100%使用され、その帯域幅はデバイス間で均等に共有されました。
FPGA-FPGA伝送中に、256バイトパケットの交換を開始することができましたが、ホストコンピューターのチップセットは128のみをサポートしていました。この場合、1740 MB / sの速度を得ることができました。 256バイトのパケット。また、複数のFPGA-FPGA同時送信を開始できることも示されており、総送信速度は共通チャネルの帯域幅を超えないが、個々の送信速度は低下せず、チャネルは100%使用され、その帯域幅はデバイス間で均等に分割されます。
FPGA-FPGAのデータ伝送レイテンシを測定しました。これは、1つの中間スイッチで706 ns、3つのスイッチで1038 nsでした。
このすべてにより、PCI ExpressザイリンクスインターフェイスのFPGAおよびIPコアとPLXテクノロジースイッチの使用に基づくアプローチは、コンピューターのローカルPCI Expressバスに接続された多数のFPGA間のデータ交換を効果的に整理できると考えることができます。
参照資料
1. Rosta LTD、2013。www.rosta.ru。
2. nVidia Corporation。 GPUDirect developer.nvidia.com/gpudirect。
3. Ra Inta、David J. Bowman、Susan M. Scott、「The“ Chimera”:既製CPU GPGPU FPGAハイブリッドコンピューティングプラットフォーム、International Journal of Reconfigurable Computing、2012。4
. Bruno da Silva、An Braeken、エリック・H. D'ホランダー、アブデラ Touhafi、ヤンG.コルネリス、ヤンLemeire、«複合GPU / FPGAデスクトップのパフォーマンスとツールチェーン»、フィールド・プログラマブル・ゲート・アレイ上のACM / SIGDA国際シンポジウムの議事録、2013年
5 Ray Bittner、Erik Ruf、Alessandro Forin、「PCI Expressを介したGPU / FPGAの直接通信」、Cluster Computing、2013年。
6. Sunita Jain、Guru Prasanna、「PCI Expressデザイン用の統合エンドポイントブロックを使用したポイントツーポイント接続」、Xilinx Corporation、XAPP869、2007。7.
PCI Express v1.7用7シリーズFPGA統合ブロック製品ガイド、Xilinx Corporation 2012.
8. Alex Goldhammer、John Ayer、「PCI Expressシステムのパフォーマンスについて」、Xilinx Corporation、WP350、2008年。