
はじめに
この記事のトピックは非常に広範囲であり、すべてのニュアンスの詳細かつ詳細な分析を期待するものではありません。 あなたがユニコード、エンコーディングなどにかなり長けていると信じているなら、この記事はほとんどまたはまったく役に立たないかもしれません。 ただし、バイナリデータとテキストデータ( バイナリデータとテキスト )の違いや、文字エンコードとは何かを理解していない人はかなりいます 。 この記事が書かれたのはそのような人々のためです。 一般に、表面的な説明にもかかわらず、いくつかの難しい点に触れていますが、詳細な説明や行動ガイドを提供するのではなく、読者が自分の存在を理解できるようにするために、これをさらに行いました。
資源
以下のリンクは、少なくともこの記事と同じくらい便利で、おそらくもっと便利です。 私自身は、この記事を書くときにそれらを使用しました。 有用で高品質の資料がたくさんあります。この記事で不正確な点に気づいた場合、これらのリソースはより正確でなければなりません。
- Unicodeコンソーシアムの公式ウェブサイト 。 すべての質問に対する回答を含む、Unicode情報の最も完全で正確なソース(ただし、サイトで有用な情報を探す必要があります)。 以下のリンクの一部は、このサイトにつながっています。
- Unicode用語集 文字エンコーディングなどの議論で使用される多くの用語の簡単な解釈を含む辞書。
- Unicode FAQ グループで配布された何百もの一般的な質問への回答。
- Unix / Linux UTF-8 FAQ 。 名前から判断して、このリンクを無視しないでください。たとえUnix / Linuxの友達でなくても、ほとんどの情報は.NETに非常に関連しています。
- Unicode文字エンコードモデル 。 「文字エンコーディングスキーム」などの用語の正確な解釈に関する詳細情報を提供します。
- ジョエル・スポルスキー。 すべてのソフトウェア開発者がUnicodeおよび文字セットについて知っておく必要がある必須の最小値(言い訳は許可されません) 。 これにやや似ているが、.NETに重点を置いていない記事。 ( ロシア語への翻訳、Habré パート1 、 パート2の翻訳)
- Unicodeの優しさについて 。 読む価値がある別の入門記事。
バイナリデータとテキストデータは2つの異なるものです。
最新のプログラミング言語(古い言語など)のほとんどは、バイナリ(バイナリ)コンテンツとシンボリック(またはテキスト)コンテンツの間に明確な線を引きます。 この違いは本能的なレベルで理解されますが、それでも定義を行います。
バイナリ(バイナリ)データは、自然な意味や解釈が付加されていない一連のオクテット (8ビットで構成されるオクテット)です。 そして、たとえ実行可能ファイルやグラフィックイメージのような1つまたは別のオクテットセットの外部「解釈」がある場合でも、データ自体はオクテットセットにすぎません。 さらに、「オクテット」という用語の代わりに、「バイト」を使用しますが、正確には、すべてのバイトがオクテットではありません。 たとえば、9ビットバイトのコンピューターアーキテクチャがありました。 ただし、このコンテキストでは、このような詳細は実際には必要ないため、以降では「バイト」という用語は正確に8ビットバイトを意味します。
文字(テキスト)データは一連の文字です。
Unicode用語集では、シンボルを次のように定義しています。
- セマンティックな意味を含む記述言語の最小コンポーネント。 特殊な形式( グリフなど)とは対照的に、抽象的な意味や形式を示します。 コード表では、読者が文字を理解するために、文字の視覚的表現のいくつかの形式が非常に重要です。
- 抽象記号の同義語(セクション3.3、文字とコード表現の定義D3を参照)。
- Unicodeコーディングシステムでのコーディングの基本単位。
- 中国起源の表意文字で書かれた要素の英語名。
この定義は役に立つかもしれませんが、ほとんどの場合、大きな文字「A」や数字「1」などを示す特定の要素のようなものとして、シンボルの直感的な理解を使用できます。 ただし、他のキャラクターはそれほど直感的ではありません。 これらには、他の文字を変更するように設計された文字の変更(たとえば、急性ストレス、 急性 )、 制御文字 (たとえば、改行)、書式設定文字(非表示ですが、他の文字に影響します)が含まれます。 テキストデータは文字セットであり、これが主なものです。
残念ながら、最近では、バイナリデータとテキストデータの違いは非常にぼやけており、あいまいでした。 たとえば、Cプログラマの場合、ほとんどの場合、「バイト」と「文字」という用語は同じことを意味していました。 .NETやJavaのような近代的なプラットフォームでは、文字とバイトの区別が明確であり、入力/出力ライブラリで修正されているため、古い習慣はマイナスの結果をもたらす可能性があります(たとえば、文字列を読み取ってバイナリファイルの内容をコピーしようとする場合があります)このファイルの内容を歪めます)。
では、Unicodeは何のためにあるのでしょうか?
Unicodeコンソーシアムは、バイナリからテキストへの変換、およびその逆の変換(それぞれデコードおよびエンコードと呼ばれる)を含む、文字データの処理の標準化を試みています。 さらに、同じことを行うISO標準のセット(さまざまなバージョンで10646)があります。 UnicodeとISO 10646はほぼ完全に互換性があるため、同じものと見なすことができます。 (理論的には、ISO 10646はより広い潜在的な文字セットを定義していますが、これが問題になることはまずありません。).NETやJavaを含む最新のプログラミング言語とプラットフォームのほとんどはUnicodeを使用して文字を表します。
Unicodeは、とりわけ以下を定義します。
- 抽象文字のレパートリー ( 抽象文字レパートリー ) -Unicodeでサポートされているすべての文字のセット。
- 文字コードのセット( コード化文字セット )-レパートリーからの各文字と、コードポイントと呼ばれる非負の整数とのバインディングが含まれています。
- 一部の文字エンコーディング形式 —コードポイントと「コードユニット」のシーケンスとの対応を決定します(単に、任意の長さの単一の整数として表されるコードポイントとこの番号をエンコードするバイトのグループとの対応)。
- 一部の文字エンコーディングスキーム -コードユニットのセットとシリアル化されたバイトシーケンス間の対応を決定します。
文字エンコード形式と文字エンコード方式の違いは非常に微妙ですが、 エンディアンネスの順序が考慮されます。 (たとえば、UCS-2エンコーディングでは、コードユニット0xC2 0xA9のシーケンスを0xC2 0xA9または0xA9 0xC2としてシリアル化できます。これが文字エンコーディングスキームによって決まります。)
抽象Unicode文字のレパートリーには、理論上、最大1114112文字を含めることができますが、多くはすでに使用不可として予約されており、残りの文字はほとんど割り当てられません。 各文字は、0から1114111(0x10FFFF)までの負でない整数でエンコードされます。 たとえば、大文字のAは10進数65でエンコードされます。数年前、すべての文字が0〜2 16 -1の範囲に収まると考えられていたため、2バイトを使用して任意の文字を表現できます。 残念ながら、時間が経つにつれてより多くのキャラクターが必要になり、いわゆる登場人物の出現につながりました。 「サロゲートペア」( サロゲートペア )。 それらによって、すべてが(少なくとも私にとっては)はるかに複雑になっているため、この記事のほとんどではそれらを扱いません。 「困難な瞬間」のセクションで簡単に説明します。
.NETは何を提供しますか?
上記のすべてが奇妙に見えても心配しないでください。 上記の違いは知っておくべきですが、実際、それらはしばしば前面に出ることはありません。 ほとんどのタスクは、特定のバイトセットをテキストに、またはその逆に変換することを中心に展開する可能性があります。 このような状況では、 System.Char構造体(C#では別名
char
で知られています )、 System.Stringクラス(C#では
string
)、およびSystem.Text.Encodingクラスを使用します。
Char
構造は、C#の最も基本的なタイプの文字です
Char
1つのインスタンスは1つのUnicode文字を表し、2バイトのメモリを占有します。つまり、0〜65535の範囲の任意の値を取ることができます。 この範囲のすべての数字が有効なUnicode文字ではないことに注意してください。
String
クラスは基本的に一連の文字です。 これは不変です。つまり、文字列のインスタンスを作成した後、それを変更することはできません(インスタンス)
String
クラスのさまざまなメソッドは、内容を変更するように見えますが、実際には新しい文字列を作成して返します。
System.Text.Encoding
クラスは、バイトの配列を文字の配列または文字列に、またはその逆に変換する手段を提供します。 このクラスは抽象です。 そのさまざまな実装は両方とも.NETで表され、ユーザー自身が作成できます。 (
System.Text.Encoding
実装を作成するタスクは、めったに発生しません。ほとんどの場合、.NETの一部であるクラスが十分にあります。)
Encoding
により、呼び出し間で状態を処理するエンコーダーとデコーダーを個別に指定できます。 これは、ストリームから受信したすべてのバイトを文字に正しくデコードできない場合のマルチバイト文字エンコードスキームに必要です。 たとえば、UTF-8デコーダーが入力として2バイト0x41 0xC2を受信した場合、最初の文字(大文字の「A」)のみを返すことができますが、2番目の文字を決定するには3番目のバイトが必要です。
組み込みのエンコードスキーム
.NETクラスライブラリには、さまざまなエンコードスキームが含まれています。 以下は、これらのスキームとその使用方法の説明です。
アスキー
ASCIIは最も一般的な文字エンコーディングの1つであり、同時に最も誤解されている文字エンコーディングの1つでもあります。 一般的な誤解に反して、ASCIIは8ビットではなく7ビットのエンコードです。127を超えるコード(コードポイント)の文字は存在しません。 たとえば、「ASCII 154」というコードを使用していると誰かが言った場合、この人は自分が何をして何を言っているのか理解していないと想定できます。 確かに、言い訳として、彼は「拡張ASCII」( 拡張ASCII )について何かを言うかもしれません。 そのため、「拡張ASCII」と呼ばれるスキームはありません。 ASCIIのスーパーセットである多くの8ビットエンコードスキームがあり、「拡張ASCII」という用語が時々それらを指すために使用されますが、これは完全に正しいわけではありません。 各ASCII文字のコードポイントは、同様のUnicode文字のコードポイントと一致します。つまり、小文字のラテン文字「x」のASCII文字と同じ文字のUnicode文字は、同じ数字-120(16進表記の0x78)で示されます。 私の意見では、 ASCIIEncoding .NETクラス(そのインスタンスはEncoding.ASCIIプロパティを介して簡単に取得できます)は、ビット7の後にすべてのビットをドロップするだけでエンコードを実行するため、少し奇妙です。 これは、たとえば、Unicode文字0xB5(「マイクロ」記号はµ )は、ASCIIでエンコードされ、Unicodeにデコードされた後、0x35文字(数字「5」)に変わることを意味します。 (代わりに、元の文字がASCIIに存在せず失われたことを示す特殊文字を表示することをお勧めします。)
UTF-8
UTF-8は、Unicode文字を表現するための適切で一般的な方法です。 各文字は、1から4までのバイトシーケンスでエンコードされます。 (コードポイントが65536未満のすべての文字は、1、2、または3バイトでエンコードされます。.NETがサロゲートペアをエンコードする方法はテストしていません。1〜3バイトの2つのシーケンスまたは4バイトの1つのシーケンス。 Unicode文字であり、ASCII互換であるため、ASCII文字のシーケンスは変更せずにUTF-8にトランスコードされます(つまり、ASCIIの文字を表すバイトのシーケンスとUTF-8で同じ文字を表すバイトのシーケンス同じです)。 さらに、文字をエンコードする最初のバイトは、同じ文字をエンコードするバイトがあればそれを決定するのに十分です。 UTF-8自体は、バイトオーダーマーク(BOM)を必要としませんが、テキストがUTF-8形式であることを示す方法として使用できます。 BOMを含むUTF-8テキストは、常に3バイトのシーケンス0xEF 0xBB 0xBFで始まります。 .NETでUTF-8で文字列をエンコードするには、単にEncoding.UTF8プロパティを使用します。 実際、ほとんどの場合、これを行う必要さえありません。他のエンコーディングが明示的に設定されていない場合、多くのクラス( StreamWriterを含む)はデフォルトでUTF-8を使用します。 (間違いなく、ここではEncoding.Defaultは適用されません。これは完全に異なります。)それにもかかわらず、読みやすさと理解のためだけに、コードでエンコーディングを常に明示的に指定することをお勧めします。
UTF-16およびUCS-2
UTF-16は、.NETが文字を処理するための単なるエンコーディングです。 各文字は2バイトのシーケンスで表されます。 したがって、サロゲートペアには4バイトが必要です。 サロゲートペアを使用する機能は、UTF-16とUCS-2の唯一の違いです。UCS-2(単にUnicodeとも呼ばれます)は、サロゲートペアを許可せず、0〜65535(0〜0xFFFF)の範囲の文字を表すことができます。 UTF-16は異なるバイト順(エンディアン)を持つことができます:高から低( ビッグエンディアン )、低から高( リトルエンディアン )、またはオプションのBOM( 少しの場合は0xFF 0xFEエンディアン、ビッグエンディアンの場合は0xFE 0xFF)。 .NET自体では、私の知る限り、サロゲートペアの問題は「スコアリング」され、サロゲートペアの各文字は独立したシンボルと見なされ、UCS-2とUTF-16の間の一種の「イコライゼーション」につながります。 (UCS-2とUTF-16の正確な違いは、サロゲートペアのより深い理解であり、私はこの側面に精通していません。)ビッグエンディアンビューのUTF-16は、 Encoding.BigEndianUnicodeプロパティを使用して取得できます。エンディアン-Encoding.Unicodeを使用します。 両方のプロパティは、 System.Text.UnicodeEncodingクラスのインスタンスを返します。これは、さまざまなコンストラクタオーバーロードを使用して作成することもできます。ここでは、BOMを使用するかどうか、およびバイトを設定する順序を指定できます。 私は(これをテストしていませんが)バイナリコンテンツをデコードするとき、コンテンツに存在するBOMはエンコーダーで設定されたバイトオーダー設定をオーバーライドするため、プログラマーがコンテンツをデコードしても余分なジェスチャーをしないでくださいこのコンテンツ内のバイト順および/またはBOMの存在が彼に知られていない場合。
UTF-7
私の経験から判断すると、UTF-7はほとんど使用されませんが、Unicode(おそらく最初の65535文字のみ)をASCII文字(バイトではありません!)に変換できます。 これは、メールゲートウェイがASCII文字のみ、またはASCIIのサブセット( EBCDICエンコーディングなど)のみをサポートする状況で電子メールを使用する場合に役立ちます。 UTF-7の詳細に一度も登ったことがないので、これから説明するつもりはありません。 UTF-7を使用する必要がある場合は、おそらく十分な知識があります。UTF-7を使用する絶対的な必要性がない場合は、使用しないことをお勧めします。 UTF-7でエンコードするためのクラスインスタンスは、 Encoding.UTF7プロパティを使用して取得できます。
Windows / ANSIコードページ
Windowsコードページは通常、それぞれ最大256または65,536文字をエンコードする1または2バイトの文字セットです。 各コードページには独自の番号があり、既知の番号を持つコードページのエンコーダーは、静的メソッドEncoding.GetEncoding(Int32)を使用して取得できます。 ほとんどの場合、コードページは、「 デフォルトコードページ 」に保存されることが多い古いデータの操作に役立ちます 。 デフォルトのコードページのエンコーダーは、 Encoding.Defaultプロパティを使用して取得できます。 繰り返しますが、可能な限りコードページを使用しないでください。 詳細については、MSDNにお問い合わせください。
ISO-8859-1(ラテン1)
ASCIIと同様に、Latin-1コードページの各文字には、Unicodeの同じ文字のコードと同じコードがあります。 Latin-1には、コードが128から159の不明な文字の「穴」があるのか、Latin-1にUnicodeと同じ制御文字が含まれているのかを気にすることはありませんでした。 (私は「穴」のアイデアに傾き始めましたが、ウィキペディアは私に同意しませんでしたので、私はまだ考えています( ウィキペディアの記事は明らかにギャップの存在を示しているため、著者の考えは明確ではありません。おそらく、元の記事を書いている時点で、 Wikipediaの記事は異なっていました-約transl。 ))Latin-1のコードページ番号は28591なので、エンコーダーを取得するには
Encoding.GetEncoding(28591)
メソッドを使用します。
ストリーム、リーダー、ライター
ストリームは本質的にバイナリであり、バイトを読み書きします。 文字列を受け取るものはすべて、特定の方法で文字列をバイトに変換する必要があります。この変換は成功する場合もしない場合もあります。 テキストを読み書きするためのストリームに相当するものは、それぞれ抽象クラスSystem.IO.TextReaderとSystem.IO.TextWriterです。 既にストリームの準備ができている場合は、 System.IO.StreamReaderクラス(
TextReader
を直接継承する)を読み取りに使用し、 System.IO.StreamWriter (
TextWriter
を直接継承する)を書き込みに使用して、ストリームをこれらのクラスのコンストラクターに渡し、このようにコーディングできます必要に応じて。 エンコードを明示的に指定しない場合、デフォルトでUTF-8が使用されます。 以下は、ファイルをUTF-8からUCS-2に変換するコードの例です。
using System; using System.IO; using System.Text; public class FileConverter { const int BufferSize = 8096; public static void Main(string[] args) { if (args.Length != 2) { Console.WriteLine ("Usage: FileConverter <input file> <output file>"); return; } String inputFile = args[0]; String outputFile = args[1]; // TextReader using (TextReader input = new StreamReader (new FileStream (inputFile, FileMode.Open), Encoding.UTF8)) { // TextWriter using (TextWriter output = new StreamWriter (new FileStream (outputFile, FileMode.Create), Encoding.Unicode)) { // char[] buffer = new char[BufferSize]; int len; // while ( (len = input.Read (buffer, 0, BufferSize)) > 0) { output.Write (buffer, 0, len); } } } } }
このコードは、ストリームを受け入れる
TextReader
および
TextWriter
を使用することに注意してください。 入力としてファイルパスを受け入れるコンストラクタオーバーロードは他にもあるため、
FileStream
を手動で開く必要はありません。 これは例としてのみ行いました。 バッファーサイズとBOMを定義する必要性を受け入れるコンストラクターオーバーロードもあります。一般的には、ドキュメントをご覧ください。 最後に、.NET 2.0以降を使用している場合は、静的クラスSystem.IO.Fileを確認すると便利です。このクラスには、エンコードを操作できる便利なメソッドも多数含まれています。
難しい瞬間
さて、これらはユニコードの基本にすぎません。 他にも多くのニュアンスがありますが、そのうちのいくつかはすでに示唆していますが、たとえこれが彼らに起こらないと信じていても、人々はそれらについて知っておくべきだと思います。 一般的な方法論やガイドラインは提供していません。問題の可能性に対する認識を高めようとしています。 以下はリストであり、完全なものではありません。 説明した問題と困難のほとんどは、Unicodeコンソーシアムの障害ではないことを理解することが重要です。 日付、時間、および国際化の問題の場合と同様に、これは人類の「メリット」であり、それ自体が時間の経過とともに多くの根本的に複雑な問題を生み出しました。
文化依存の検索、並べ替えなど。
これらの問題は、.NETの文字列に関する私の記事( オリジナル 、 翻訳 )で説明されています。
サロゲートペア
Unicodeには65536個を超える文字が含まれているため、それらすべてを2バイトで収容することはできません。 これは、
Char
構造の単一のインスタンスがすべての可能な文字を受け入れることができないことを意味します。 UTF-16(および.NET)は、サロゲートペアを使用してこの問題を解決します。これらは2つの16ビット値であり、各値の範囲は0xD800〜0xDFFFです。 つまり、2つの「シンボルのタイプ」が1つの「実際の」シンボルを形成します。 (UCS-4とUTF-32は、使用可能な値の範囲が広いという事実により、この問題を完全に解決します。各文字は4バイトで、これはすべての人にとって十分です。)これは、文字列が、10文字で構成され、実際には10〜5文字の「実際の」Unicode文字を含めることができます。 幸いなことに、ほとんどのアプリケーションは科学的または数学的な表記とカーン記号を使用していません。そのため、あまり心配する必要はありません。
修飾文字
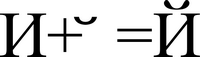
すべてのUnicode文字が画面または紙にアイコン/画像として表示されるわけではありません。 下線付き(アクセント付き)文字は、他の2つの文字として表すことができます。通常の下線付き文字と、それに続く下線( 結合文字と呼ばれます)。 一部のグラフィカルインターフェイスは文字の変更をサポートしていますが、一部はサポートしていないため、アプリケーションはどのような仮定を行うかに依存します。
正規化
キャラクターの変更などの理由もあり、ある意味で単一のキャラクターを表す方法はいくつかあります。 たとえば、アクセント付きの文字「á」は、アクセントなしの1つの記号「a」とそれに続くアクセントの修飾文字で表すことができ、アクセント付きの完成文字「a」を表す1つの記号でのみ表すことができます。 文字シーケンスは、可能な限り変更文字を使用するように正規化することができます。または、その逆も同様です。単一の文字に置き換えることができる場所では使用しません。 アプリケーションは、アクセント付きの文字「á」を含む2行を検討しますが、1行は2文字で表し、2行目は等しい、または異なると見なすべきですか? ソートはどうですか? あなたが使用するサードパーティのコンポーネントとライブラリは、文字列の正規化を行いますか?一般的に、そのようなニュアンスは考慮されますか? これらの質問に答えてください。
Unicodeの問題のデバッグ
このセクション( オリジナルは別の記事です -約Per )非常に特定の状況で何をすべきかを説明します。 つまり、1つの場所(通常はデータベース内)にいくつかのシンボリックデータ(通常はデータベース内)があり、それらは異なるステップ/レイヤー/コンポーネントを通過し、ユーザー(通常はWebページ)に表示されます。 また、残念ながら、一部の文字が正しく表示されません( クラックバック )。 テキストデータが通過する多くの手順に基づいて、多くの場所で問題が発生する可能性があります。 このページは、何がどこで「壊れている」かを簡単かつ確実に見つけるのに役立ちます。
ステップ1:Unicodeの基本を理解する
簡単に言えば、記事の本文を読んでください。 また、記事の冒頭に記載されているリンクに注意を払うこともできます。 事実は、基本的な知識がなければピンと張るということです。
ステップ2:発生する可能性のある変換を特定する
すべてが壊れる可能性のある場所を理解できれば、このセクション/ステップは簡単に分離できます。 同時に、問題はリポジトリからテキストを抽出および変換するプロセスではなく、すでに「破損した」テキストがリポジトリに以前に入力されたという事実にあることに留意してください。 (たとえば、あるアプリケーションがデータベースとの間でテキストを読み書きする際にテキストを歪めると、過去にこのような問題が発生しました。「トリック」は、変換エラーが重複し、相互に補正されていたため、出力がテキストは正しいことが判明しました。一般に、アプリケーションは正常に機能しましたが、触れた場合、すべてが崩れました。)テキストを「台無しにする」アクションには、データベースからの取得、ファイルからの読み取り、Web接続を介した転送、画面上のテキストの表示が含まれます
ステップ3:各段階でデータを確認する
最初のルール:文字データを一連のグリフとして記録するもの(つまり、標準の文字アイコン)を信頼しないでください。 代わりに、バイト単位の文字コードのセットとしてデータを記録する必要があります。 たとえば、「hello」という単語を含む行がある場合、「0068 0065 006C 006C 006F」と表示されます。 (16進コードを使用すると、コードテーブルに対して文字を簡単にチェックできます。)これを行うには、文字列内のすべての文字を調べ、各文字のコードを表示する必要があります。
static void DumpString (string value) { foreach (char c in value) { Console.Write("{0:x4} ", (int)c); } Console.WriteLine(); }
独自のロギング方法は環境によって異なりますが、その基礎は私が指定したものとまったく同じである必要があります。 文字列に関する記事で、文字データのデバッグとログのより高度な方法を説明しました。
私のアイデアの本質は、エンコーディング、フォントなどに関するあらゆる種類の問題を取り除くことです。 この手法は、特定のUnicode文字を使用する場合に役立ちます。単純なASCIIテキストの16進コードを正しく記録できない場合、大きな問題が発生します。
次のステップは、使用できるテストケースがあることを確認することです。できればアプリケーションが「失敗」することが保証されているソースデータの小さなセットを見つけ、正しい結果がどうあるべきかを正確に知っていることを確認し、すべての問題領域で結果を誓約してください。
問題のある行が確約された後、それが本来あるべきかどうかを確認する必要があります。Unicodeコードチャートの Webページがこれに役立ちます。。確かな文字セットを選択し、アルファベット順に文字を検索できます。文字列の各文字が正しい値を持っていることを確認してください。シンボルデータストリームが破損しているアプリケーション内の場所を見つけたらすぐに、この場所を調べ、エラーの原因を見つけて修正します。すべてのエラーを修正したら、アプリケーションが正常に動作していることを確認してください。
おわりに
ソフトウェア開発で発生するエラーの大半と同様に、テキストに関する問題は、普遍的な「分割統治」戦略を使用して解決されます。すべてのステップに自信が持てば、一般的に自信を持つことができます。そのようなエラーの修正中に、特に理解不能で奇妙なエラーの兆候に遭遇した場合、修正後、コードのこのセクションを単体テストでカバーすることを強くお勧めします。それらは、起こるかもしれないことの文書化と、将来の回帰に対する保護の両方の役割を果たすでしょう。
ソース
- ジョン・スキート。Unicodeおよび.NET
- ジョン・スキート。Unicode問題のデバッグ