簡単だが効率的なリアルタイム音声アクティビティ検出アルゴリズム
M.H. MoattarおよびMM Homayonpour
インテリジェント音声音声処理研究所(LISSP)、コンピュータ工学および情報技術部、アミランカビル工科大学、テヘラン、イラン
元のリンク
まとめ
音声アクティビティ検出アルゴリズム(VAD)は、音声および音声処理アプリケーションで非常に重要な方法です。 すべてではありませんが、ほとんどの音声/音声処理方法の有効性は、使用されるVADアルゴリズムの効率に大きく依存します。 音声アクティビティの理想的な検出器は、アプリケーションの範囲、ノイズレベルに依存せず、使用されるアプリケーションの最大パラメータに最も依存しないものでなければなりません。 この記事では、実装が簡単でノイズに強い、完璧に近いVADアルゴリズムを提案します。 提案する方法では、スペクトルの平坦性(SF)(スペクトルの平坦性、均一性)や短期的なエネルギーなどの短期的な特性を使用しているため、リアルタイムでの使用に適しています。 この方法は、ノイズレベルの異なる複数の録音でテストされ、最近提案された方法と比較されました。 実験では、さまざまな騒音レベルで満足のいく結果が示されました。
1.はじめに
音声アクティビティ検出(VAD)、つまり音声または音声信号の無音を検出することは、エンコード、認識、音声明瞭度の改善、音声のインデックス作成など、音声または音声で動作する多くのアプリケーションにとって非常に重要なタスクです。 たとえば、GSM 729標準[1]は、サンプル内の異なるビット数でのエンコードに2つのVADモジュールを使用します。 ノイズ耐性VADは、音声認識(自動音声認識ASR)にとっても非常に重要です。 優れた検出器は、ノイズの多い環境でASRの精度と速度を向上させます。
[2]によれば、理想的な音声アクティビティ検出器に必要な特性は、信頼性、安定性、精度、適応性、単純性、リアルタイムの使用可能性、ノイズに関する情報なしです。 ノイズ耐性を達成することが最も困難です。 SNR(Signal-to-Noise Ratio)が高い条件では、最も単純なVADアルゴリズムは十分に機能しますが、SNRが低い条件では、すべてのVADアルゴリズムがある程度低下します。 同時に、リアルタイムの適用要件を満たすために、VADアルゴリズムは単純なままにする必要があります。 したがって、シンプルさとノイズ耐性は、実用的な音声アクティビティ検出器の2つの重要な特性です。
多くのVADアルゴリズムが提案されていますが、その主な違いは使用される特性にあります。 すべての特性の中で、短期エネルギーとゼロ交差率は、その単純さのために、より頻繁に使用されました。 ただし、ノイズが存在すると大幅に劣化します。 この欠点を修正するために、自己相関関数[3、4]、スペクトル(スペクトルベース)[5]、狭帯域セグメントのパワー(帯域制限領域のパワー)[1、6 、7]、MFCC(メル周波数ケプストラム係数[4]-トーン周波数のケプストラム係数。本spbuで読むことができます)、デルタスペクトル周波数(6)および高次統計[8]。 これらの特性を使用すると、VADノイズ耐性が向上することが実験で示されています。 一部の論文では、CART(分類および回帰ツリー)[9]やANN(人工神経回路網)[10]などのモデリングアルゴリズムと組み合わせてさまざまな特性を使用することを提案していますが、これらのアルゴリズムはVAD自体の複雑さに匹敵します。
一方、いくつかの方法では、ノイズモデル[11]を使用するか、Wienerフィルターによるノイズの統計的フィルタリング後に得られる改善された音声スペクトルを使用します[7、12]。 ほとんどの特性は一定期間定常ノイズを想定しているため、処理された信号のSNRの変化に敏感です。 一部の論文では、VADの安定性を改善するためのノイズ計算と適応が提案されています[13]が、これらの方法は計算が非常に複雑です。
また、新しい検出方法を作成するために使用されるVAD標準があります。 その中には、GSM 729 [1]、ETSI AMR [14]、およびAFE [15]があります。 たとえば、GSM 729標準は、周波数ペアの線形スペクトル、フルバンドエネルギーとローバンドエネルギー、ゼロクロッシングレートを使用し、限られたスペースで固定境界を使用して分類器を適用します[1]。
この作業では、VADアルゴリズムが提案されます。これは、実装が簡単で、リアルタイムの音声/音声処理に使用でき、十分なノイズ耐性を提供します。 セクション3では、提案されているVADのアルゴリズムについて詳しく説明しています。
2.短期機能(短期特性)
提案手法では、各フレームに3つの異なる特性を使用します。 最初の特性は、短期エネルギー(E)です。 エネルギーは、音声/無音の定義で最も一般的に使用される特性です。 ただし、特に低SNRのノイズ条件では無効になります。 したがって、周波数から計算される2つの特性を使用します。
2番目の特性は、スペクトルの平坦性の尺度です(SFM-Spectral Flatness Measure)。 スペクトルノイズの測定値は、音声/非音声検出および無音検出でよく表れます。
SFMは次のように計算されます。
SMF db = 10log 10 (G m / A m )
ここで、A mとG mは、それぞれ音声スペクトルの算術平均と幾何平均です。
これらの2つの特性に加えて、最も支配的な周波数成分を持つ音声フレームのコンポーネントは、音声と無音のフレームを区別するのに非常に役立つことがわかった。 この作業では、この特性をFで示します。スペクトルの最大値に対応する周波数を見つけることで、簡単に計算できます。 S(k)|。
提案された音声アクティビティの検出方法では、3つの特性すべてが各フレームに対して同時に計算されます。
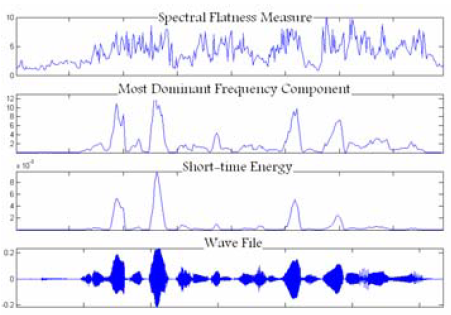
図1.明瞭な音声信号の特性値

図2.ホワイトノイズによって損傷した信号の特性値
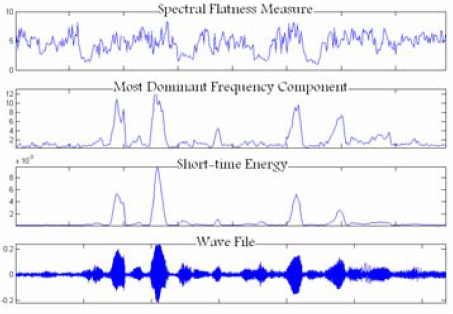
図3.せせらぎノイズによって損傷した信号の特性値
図1〜3は、クリーンでノイズが損傷した信号に対するこれら3つの特性の有効性を表しています。
3.推奨VADアルゴリズム
提案されたアルゴリズムは、オーディオ信号をフレームに分割することから始まります。 実装では、ウィンドウ関数は使用されません。 最初のNフレームは、しきい値を初期化するために使用されます。 着信フレームごとに、3つの特性が計算されます。 複数の特性の値がしきい値を超える場合、音声フレームは音声と見なされます。 提案された方法の完全な手順を以下に示します。
1 - Frame_Size = 10ms - ( Num_of_frames ) // 2 - . // * (Energy_PrimTreshhold) * F (F_PrimTreshhold) * SFM (SF_PrimTreshhold) 3 - For i 1 Num_of_frames 3.1 - (E(i)) 3.2 - FFT 3.2.1 - F(i) = arg max (S(k)) - 3.2.2 - Measure(SFM(i)) 3.3 - 30 - , (Min_E), F (Min_F), SMF (Min_SF) 3.4 - E, F, SFM * Tresh_E = Energy_PrimTresh * log(Min_E) * Tresh_F = F_PrimTresh * Tresh_SF = SF_PrimTresh 3.5 - Counter = 0 * ((E(i) - Min_E) >= Tresh_E) Counter++ * ((F(i) - Min_F) >= Tresh_F) Counter++ * ((SFM(i) - Min_SF) >= Tresh_SF) Counter++ 3.6 - Counter > 1 , 3.7 - , tythubb Min_E = ((Silence_Count * Min_E) + E(i)) / (Silence_Count + 1) 3.8 Tresh_E = Energy_PrimTresh * log(Min_E) 4 - 10 5 - 5 .
アルゴリズムには、最初に設定する必要がある3つのパラメーターがあります。 これらのパラメータは、純粋な音声信号の有限セットで自動的に見つかりました。 以下は、実験の結果として得られた最適値です。
Energy_PrimThresh = 40
F_PrimThresh(Hz)= 185
SF_PrimThresh = 5
元の記事は、異なるノイズの条件下で行われた実験の結果を提供します。 このトピックと翻訳自体についてのコミュニティの意見を知りたいです。 このトピックについて翻訳を続けていくのは理にかなっていますか? 翻訳のすべての不正確さ、プライベートメッセージに書き込むエラーについて。
翻訳ハブに投稿を割り当てることを除いて、これが翻訳であることを示す方法が見つかりませんでした。
参照資料
[1] A. Benyassine、E。Shlomot、HY Su、D。Massaloux、C。LamblinおよびJP Petit、「ITU-T勧告G.729付録B:V向けに最適化されたG.729で使用するための無音圧縮方式」 70のデジタル同時音声およびデータアプリケーション、「IEEE Communications Magazine 35、pp。 64-73、1997。
[2] MH Savoji、「音声の正確なエンドポインティングのための堅牢なアルゴリズム」、Speech Communication、pp。 45-60、1989。
[3] B.キングズベリー、G。サン、L。マング、M。パドマナハン、R。サリカヤ、「ノイズの多い環境での堅牢な音声認識:2001 IBM SPINE評価システム」、Proc。 ICASSP、1、ページ 53-56、2002。
[4] T. Kristjansson、S。DeligneおよびP. Olsen、「ロバストな音声検出のためのボイス機能」、Proc。 Interspeech、pp。 369-372、2005。
[5] REヤントルノ、KLクリシュナマチャリ、JMラブキン、「スペクトル自己相関ピークバレー比(SAPVR)-同一チャネル検出システムとして使用される使用可能な音声測定」、Proc。 IEEE Int。 ワークショップIntell。 信号プロセス。 2001年。
[6] M. MarzinzikおよびB. Kollmeier、「パワーエンベロープダイナミクスの追跡によるノイズスペクトル推定のための音声ポーズ検出」IEEE Trans。 スピーチオーディオプロセス、10、pp。 109-118、2002。
[7] ETSI標準文書、ETSI ES 202 050 V 1.1.3。、2003。
[8] K. Li、NS Swamy、MO Ahmad、「高次統計を使用した音声アクティビティ検出の改善」IEEE Trans。 Speech Audio Process。、13、pp。 965-974、2005。
[9] WH Shin、「堅牢なエンドポイント検出のための複数の機能を使用した音声/非音声分類」、ICASSP、2000。
[10] GD WuandとCT Lin、「ノイズの多い環境でのメルスケール周波数バンクによるワード境界検出」、IEEE Trans。 Speechand Audio Processing、2000。
[11] A.リー、K。中村、R。西村、H。猿渡、K。鹿野、「意図しない入力のGMMベースの拒否を使用したノイズに強い実世界の音声対話システム」Interspeech、pp。 173-176、2004。
[12] J.ソーン、NSキム、W。ソン、「統計モデルベースの音声アクティビティ検出」、IEEEシグナルプロセス。 Lett。、Pp。 1-3、1999。
[13] B. LeeおよびM. Hasegawa-Johnson、「最小平均二乗誤差、高分散車両ノイズの事後推定」、Proc。 2007年6月、トルコ、イスタンブールの車載およびモバイルシステム向けDSPに関するビエンナーレ。
[14] ETSI EN 301 708勧告、「適応型マルチレート(AMR)音声トラフィックチャネル用の音声アクティビティ検出器」1999。
リンク集
[1] A. Benyassine、E。Shlomot、HY Su、D。Massaloux、C。LamblinおよびJP Petit、「ITU-T勧告G.729付録B:V向けに最適化されたG.729で使用するための無音圧縮方式」 70のデジタル同時音声およびデータアプリケーション、「IEEE Communications Magazine 35、pp。 64-73、1997。
[2] MH Savoji、「音声の正確なエンドポインティングのための堅牢なアルゴリズム」、Speech Communication、pp。 45-60、1989。
[3] B.キングズベリー、G。サン、L。マング、M。パドマナハン、R。サリカヤ、「ノイズの多い環境での堅牢な音声認識:2001 IBM SPINE評価システム」、Proc。 ICASSP、1、ページ 53-56、2002。
[4] T. Kristjansson、S。DeligneおよびP. Olsen、「ロバストな音声検出のためのボイス機能」、Proc。 Interspeech、pp。 369-372、2005。
[5] REヤントルノ、KLクリシュナマチャリ、JMラブキン、「スペクトル自己相関ピークバレー比(SAPVR)-同一チャネル検出システムとして使用される使用可能な音声測定」、Proc。 IEEE Int。 ワークショップIntell。 信号プロセス。 2001年。
[6] M. MarzinzikおよびB. Kollmeier、「パワーエンベロープダイナミクスの追跡によるノイズスペクトル推定のための音声ポーズ検出」IEEE Trans。 スピーチオーディオプロセス、10、pp。 109-118、2002。
[7] ETSI標準文書、ETSI ES 202 050 V 1.1.3。、2003。
[8] K. Li、NS Swamy、MO Ahmad、「高次統計を使用した音声アクティビティ検出の改善」IEEE Trans。 Speech Audio Process。、13、pp。 965-974、2005。
[9] WH Shin、「堅牢なエンドポイント検出のための複数の機能を使用した音声/非音声分類」、ICASSP、2000。
[10] GD WuandとCT Lin、「ノイズの多い環境でのメルスケール周波数バンクによるワード境界検出」、IEEE Trans。 Speechand Audio Processing、2000。
[11] A.リー、K。中村、R。西村、H。猿渡、K。鹿野、「意図しない入力のGMMベースの拒否を使用したノイズに強い実世界の音声対話システム」Interspeech、pp。 173-176、2004。
[12] J.ソーン、NSキム、W。ソン、「統計モデルベースの音声アクティビティ検出」、IEEEシグナルプロセス。 Lett。、Pp。 1-3、1999。
[13] B. LeeおよびM. Hasegawa-Johnson、「最小平均二乗誤差、高分散車両ノイズの事後推定」、Proc。 2007年6月、トルコ、イスタンブールの車載およびモバイルシステム向けDSPに関するビエンナーレ。
[14] ETSI EN 301 708勧告、「適応型マルチレート(AMR)音声トラフィックチャネル用の音声アクティビティ検出器」1999。