Yandex内の技術はシベリアと呼ばれています。 CBIRから- コンテンツベースの画像検索 。
もちろん、タスク自体は新しいものではなく、多くの研究がそれに専念しています。 しかし、学術コレクションで動作するプロトタイプを作成し、数十億の画像と大量のリクエストを処理する産業システムを構築することは、まったく異なる話です。

これは何のためですか?
ダウンロードしたイメージを検索する必要があり、処理方法を学習する必要がある3つのシナリオがあります。
- 人は同じまたは類似の画像を必要としますが、解像度が異なる(通常は最大)か、色が異なるか、品質が高いか、切り取られていません。
- あなたは絵の中にあるものを理解する必要があります。 この場合、画像の横にある短い説明で、誰が何を描いているかを明確にすることができます。
- 同じ絵のあるサイトを見つける必要があります。 たとえば、写真の中にあるものについて読みたいとき。 または、同じ写真を見てください。 または、写真に示されているものを購入します。この場合、ショップが必要です。
どのように機能しますか?
類似の画像を見つけるためのさまざまなアプローチがあります。 最も一般的なものは、 視覚的な単語の形での画像の表現に基づいています -特異点で計算された量子化されたローカル記述子。 画像が変更されたときに最も安定しているポイントは、特別と呼ばれます。 それらを見つけるために、画像は特別なフィルターによって処理されます。 これらのポイントの周囲のエリアのデジタル形式での説明は、記述子です。 記述子を視覚的な単語に変換するために、視覚的な単語の辞書が使用されます。 画像の代表的なセットに対して計算されたすべての記述子をクラスタリングすることにより取得されます。 将来、新しく計算された各記述子は対応するクラスターに割り当てられます。これが、量子化された記述子(視覚的な単語)の取得方法です。
通常、大規模なコレクション内のダウンロードされた画像から画像を検索するプロセスは、次の順序で構築されます。
- ダウンロードした画像の視覚的な単語のセットを取得します。
- 逆索引によって候補を検索します。逆索引は、指定された一連の視覚的な単語によって、それを含む画像のリストを決定します。
- 調査中のサンプル画像と画像の一致する記述子の相対位置を確認します。 これは、候補者の検証とランキングの段階です。 従来、ハフ変換またはRANSACのクラスタリングが使用されていました。
アプローチのアイデアは記事に記載されています。
- J.フィルビン、O。チュム、M。アイサード、J。シビック、A。ツィサーマン。 大量の語彙と高速空間マッチングを使用したオブジェクト検索。 CVPR、2007年
- J.シビックとA.ジサーマン。 ビデオグーグル:ビデオ内のオブジェクトマッチングへのテキスト取得アプローチ。 ICCV、2003年。
- ジェームズ・フィルビン・ジョセフ・シビック・アンドリュー・ツィッサーマン大規模画像データセットのマッチング・グラフ上の幾何学的潜在ディリクレ配分(項目3.1、3.2)
ピクチャリクエストから画像を検索するために使用する方法は、上記の従来のアプローチに似ています。 ただし、ローカルフィーチャの相対位置の検証には、かなりの計算リソースが必要です。 また、Yandex検索インデックスに保存されている膨大な画像のコレクションで検索するには、問題を解決するためのより効果的な方法を見つける必要がありました。 インデックス作成方法により、サンプルに関連すると見なせる画像の数を大幅に減らすことができます(リクエスト)。
候補の検索の実装で重要なのは、視覚的な単語のインデックス付けから、より差別的な機能、特別なインデックス構造のインデックス付けへの移行です。
候補の選択には、2つの方法が同等に優れていることが証明されています。
- 高度な機能または視覚的なフレーズ(フレーズ)のインデックス作成。 それらは、画像の対応する局所的な特徴の相対的な位置と他の相対的な特徴を特徴付ける視覚的な言葉とパラメーターの組み合わせです。
- キーが記述子の量子化された部分で構成されるマルチインデックス(製品の量子化)。 メソッドが公開されました: download.yandex.ru/company/cvpr2012.pdf
検証時には、画像間のクラスタリング変換の独自の実装を使用します。
次に、1つ上のレベルに進み、製品レイアウト全体を見てみましょう。
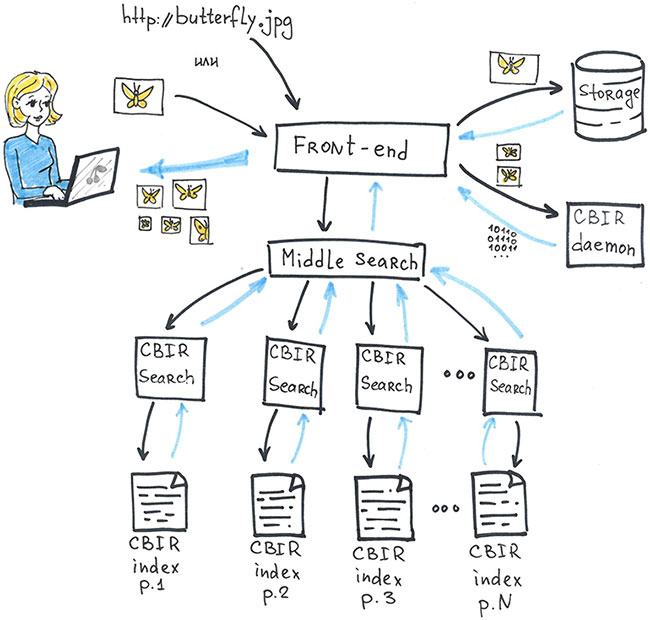
- ユーザーの写真は一時的に保存されます。
- そこから、画像の小さなコピーがデーモンに分類され、そこで記述子と視覚的な単語が画像に対して計算され、それらから検索クエリが形成されます。
- 要求は最初に平均的なメタ検索に送信され、そこから基本的な検索に従って配信されます。 各ベース検索には多くの画像を含めることができます。
- 見つかった画像は、中規模のメタ検索に返送されます。 そこで結果がマージされ、結果のランク付けされたリストがユーザーに表示されます。
各基本検索は、インデックスの独自の部分で機能します。 これにより、システムのスケーラビリティが確保されます。インデックスの増加に伴い、基本検索の新しいフラグメントと新しいレプリカが追加されます。 また、基本的な検索とインデックスフラグメントの複製により、フォールトトレランスが提供されます。
そしてもう1つの重要なニュアンス。 検索効率を高めるために、画像の検索インデックスを作成する際に、重複画像について既に持っている知識を使用しました。 重複の各グループから代表者を1人だけ取り、写真の検索インデックスに含めるように使用しました。 ロジックは単純です。画像がリクエストに関連している場合、そのすべてのコピーは関連する同じ回答になります。

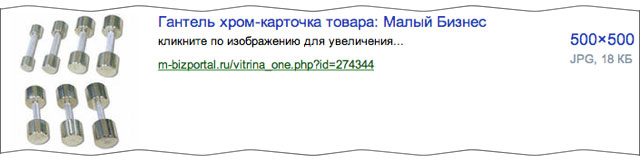

このバージョンでは、ロードされた画像に完全に一致するか、一致するフラグメントを含む画像のコピーのみを見つけることが期待されていました。 しかし今、私たちのソリューションは一般化する能力を示しています:時には同じ絵だけでなく、別の絵が同じオブジェクトを含んでいることがあります。 たとえば、これはしばしばアーキテクチャに現れます。
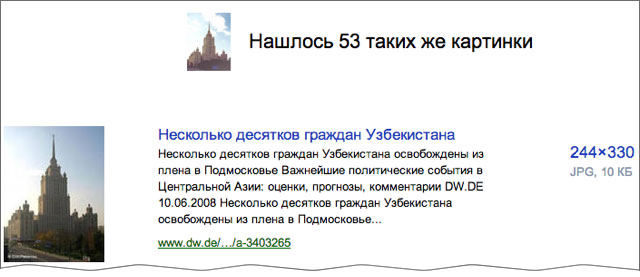




これは、コンテンツごとに画像を見つけるための最初のステップです。 もちろん、このような技術を開発し、それらに基づいて新製品を作成します。 それで何か、しかしこれには十分なアイデアと欲求があります。