
形態に関する一連の記事の内容
前回の記事では、見出し語化問題の解決に近づき、それが必要かどうかを見つけましたが、記述された言語のすべての単語を含む辞書を何らかの形で保存する必要があります。
ロシア語の場合、これは数十万語です。 これは経済的ではないかもしれませんが、多くのボーナスを提供します。
まず、 単語が辞書にあるかどうかを確認できます。 正規表現に基づくルールの助けを借りても、ロシア語で「自分を洗う」という言葉があるかどうかはわかりません。 語尾は完全にロシア語の規則に従い、音節の繰り返しも例外ではありません。 この単語は正規表現を見逃しますが、実際にはロシア語には「ウォッシュ」はありません。
モルフォロジーに格納されている辞書が解決するもう1つのタスクは、 エラー修正です。 辞書に単語が見つからないが、検索されたレーベンシュタインから短い距離に別の単語が見つかるとすぐに、訂正に関する決定を下します。
これらの問題を解決するには、すべての単語だけでなく、すべての形式も保存する必要があります。 互いに類似した単語のグループのフォームの形成に関するすべてのルールは、変曲パラダイムと呼ばれます 。 「budlanut」という動詞を取る:budlanul、budlanet、budlanet、budlanul、budlanula、budlanul。 同じルールに従って変化する多くの動詞を見つけることができます。 一方、他の規則に従って、膨大な数の動詞が変更されます。 したがって、これらの動詞は異なるパラダイムに属します。
構文の質問に答えるために、各フォームに文法的な意味を保存します。
辞書ストレージ
したがって、システムに格納されている辞書は、喜ばざるを得ない多くの問題を解決します。 しかし、この辞書を保持する方法は? ロシア語には数十万語があります。 平均して、単語ごとに15のフォームがあります。 この番号はどこから入手できますか? ケースを考えてみましょう:単数用に6個、複数用に6個あります-すでに12個です。そして、ロシア語では学校で教えるように6個ではなく、8個あることは言うまでもありません。
第一に、前置詞の場合は、位置詞と呼ばれる場合です。 前置詞の場合に「森」という言葉を使うと、「森について」と「森の中」という2つの選択肢があります。 フォレストでは、前置詞のケースではなく、場所のケースです。 多くの名詞では、「テーブルの上」、「テーブルについて」、「テーブルの上」を区別しないため、これらのケースの形式は一致します。 これは、「テーブル内」に場所はなく、「フォレスト内」に場所があるためです。
8番目のケースは、partitiveと呼ばれます。 このケースは全体の一部を示しています。 私たちがお茶を使い果たして、怠toに近づき、誰かが近くに人のいない散歩をした場合、私たちは彼に言います:「お茶を注いでください」。 原則として、分詞の単語の形式は、属格または対格の場合と一致します。 ウィキペディアは、複数のパーティティフ以外の形を持たない単語の素晴らしい例を提供します-「頬」(「頬はしたくない?」;「頬を注いでください!」)
 合計、8つのケースに2つの形式(単数形と複数形)を掛けた-すでに16。動詞には時間、数、性別があります。 単純な算術計算を使用すると、15のフォームがかなり控えめな見積もりであることがわかります。
合計、8つのケースに2つの形式(単数形と複数形)を掛けた-すでに16。動詞には時間、数、性別があります。 単純な算術計算を使用すると、15のフォームがかなり控えめな見積もりであることがわかります。
ロシア語の平均文字数は9です。1バイトが2バイトであることを忘れずに、得られた結果を乗算します。ロシア語のすべての形式の辞書には、50メガバイトが必要であることがわかります。 実際には、理想的な50メガバイトは1.5倍増加します。その結果、ロシア語のすべての形式のテキストファイルは75メガバイトを超えます。
さらに、これらの単語をすべてファイルに書き込んだとしても、それを検索する必要があります(そうでなければ、なぜ必要なのでしょうか?)。 つまり、単語をアルファベット順に並べ、各単語に加えて、単語の初期形式へのポインタを追加する必要があります。 ポインターは、一度に1つずつ重いものではありませんが、辞書に重みを追加します。 この場合、検索速度は

また、これはロシア語のみで、英語、フランス語、スペイン語、イタリア語、および他の多くの美しく豊かな言語もあります。 たとえば、FineReaderで多くの言語を認識およびサポートする場合は、形態学的辞書をギガバイトに収めるだけで済みます。 認識およびその他のdllの標準について話すことは何ですか? そのような重い技術を持つユーザーは私たちを理解しません-そして彼は正しいでしょう。 私たちはもっと謙虚になり、より良くならなければなりません。
プレフィックスツリー
プレフィックスツリーが役立ちます。 どのように配置されていますか? それはすべて上から始まります-アルファベットが格納される空の文字。 最初の文字については、アルファベット全体、より正確には33個のポインターの配列が格納されます。 各ポインターは、そのシンボルに対応しています。 最初のポインター-キャラクターAへ、2番目-キャラクターBへ、いくつかのK番目のポインター-キャラクターKへ、そしていくつかのP番目-キャラクターPへ。ポインターに従って、ロシア語のアルファベットの文字に対応するこのツリーの次のノードを取得できます。
次のノードは再び配列を保存します。 さらに、検索速度を上げるために、ポインターが必要な文字が既に33未満であるという事実を無視します(たとえば、「ay」の組み合わせが必要になることはほとんどありません)。 不足している文字にNULLポインターを挿入することにより、配列の次元を変更しません。
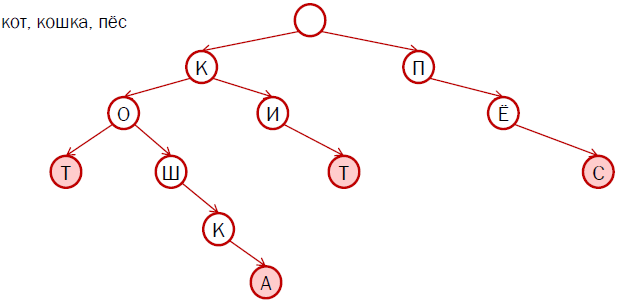
この図は、「猫」、「猫」、「クジラ」、「犬」の4つの単語のプレフィックスツリーの例を示しています。 ピンクは最終的なピークを日陰にした。
このアプローチの利点は、同じ単語に対して異なる形式で繰り返し文字の巨大なチェーンを保存しないことです。 したがって、辞書を使用してファイルのサイズを小さくします。 たとえば、ロシア語の場合、このツリーと追加データは約2メガバイトかかります。 まず、75メガバイトと比較して、これは確かに成功です。 第二に、このようなツリーの検索速度は、ソートされたファイルの検索速度よりもはるかに高速です。 今では、辞書全体のサイズではなく、探しているものだけに依存しています。 ユニオン「a」を探している場合、1つのステップでそれを見つけます。たとえば、「ヘリコプター」などの長い単語を探している場合、検索に少し時間がかかります。
もちろん、すべての単語のすべての形式を文法的な意味なしでツリーに入れると、コンピューター言語について話すことはできません。意味論はもちろんのこと、構文のレベルまで上げることはできず、それらがないと自動翻訳は不可能です。 そのため、データ構造について引き続き作業する必要があります。
辞書に保存するもの
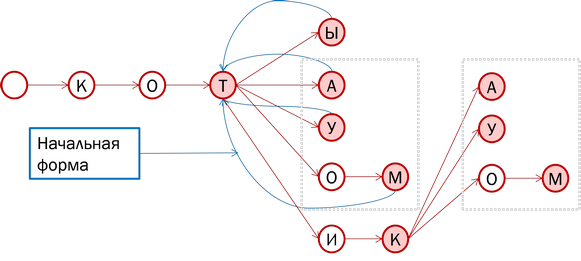
理論的には、最初の形式(図の青い線)へのポインターを保持しながら、実際にすべての形式の単語をツリーに格納できます。 ただし、注意:「猫」と「猫」は異なる語形成パラダイムを指すという事実にもかかわらず、いくつかの語尾変化(エンディングと呼ばれる)は一致します。 これらの単語の尾が別々に保存され、猫、オットセイ、クジラの初期形態がツリーに残っている場合はどうなりますか? したがって、より効果的です。
徹底的なアプローチ
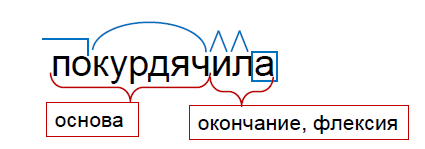
学校では、単語は次のように構成要素に分割されます:接頭辞、ルート、いくつかの接尾辞、および末尾。 私たちは他の方法で行きます。 まず、プレフィックスをルートから分離しません。 これは、多くの場合、プレフィックスとルートが完全に新しい意味を形成するためです。 たとえば、「プレフィックス」と「レート」という言葉を考えてみましょう。 「Pri-」は「rate」という単語の単なる接頭辞ですが、「prefix」と「rate」はまったく異なるものです。
また、接頭辞は文法的なカテゴリを表しません。 接頭辞「re-」(「redo」または「smoke」)を追加すると、文法的な意味ではなく、単語の語彙的な意味が変わります。 したがって、プレフィックスとルートを単一の全体と見なし、これを単語の基礎と呼びます。
学校とのもう1つの違い:ほとんどの場合、接尾辞は文法的なカテゴリを表すため、接尾辞を末尾から分離することはほとんどありません。 この例では、「-l-」と「-a-」は過去形、女性の性別を表し、それらを組み合わせて変曲にしています。 この分割により、語の可変部分-屈折と不変-の基礎が得られます。
便利な仮定

おそらく、コンピュータ言語学では何も起こらないという事実にすでに慣れているでしょう。 ここにあります:単語のさまざまな形式では、ルートの一部でさえも変更できます。 もちろん、これは「friend-g」と「friend-friend」のルートにある単なる可変子音であると退屈に議論できますが、実際の問題を解決するには、これらの単語が「friend-friend」と同じ根拠を持っていることを受け入れる方が便利です屈折は異なります。
そのため、トークン(語幹)と変曲は別々に保存されると判断しました。 最後に、補題化がABBYYの形態学的モジュールをどのように解決するかに近づきます。
最終補題
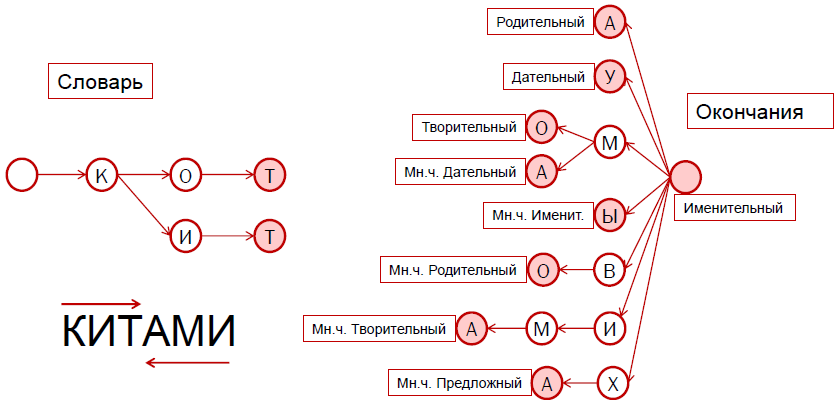
左の図では、すでにおなじみのプレフィックスツリーの形で、ロシア語辞書の10万分の1が描かれています。 右側には、同じ方法で格納されている語尾辞の辞書があります。
エンディングをよく見ると、「猫」と「クジラ」の両方に起因していることに気付くでしょう。 「a」を追加すると、属格を取得し、「y」を使用すると、与格などを取得します。 これらはすべて、同じパラダイムに属する2つの単語の異なる形式であり、したがって等しく変化します。
クジラの解析
単語の形式を取得すると、最初からではなく、最後から分析し始めます。 最初に、ピンクでマークされたゼロの終了があると仮定します。これは、主格の場合、単数形であることを示します。 その後、私たちに与えられた「クジラ」という言葉に従い、「と」の文字に会います。 プレフィックスツリーに「and」という文字があります。 次の文字は「m」です。 これらの文字は最後ではないため、ツリーの奥深くに移動し続けます。 ピンクでマークされている次の文字「a」は、ツリーの終了ノードです。 したがって、左から右への「-ami」、または右から左への「-ima」-これは、単語の末尾に使用できる終了オプションの1つです。
そのため、2つのエンディングが見つかりました:emptyと“ -ami”。 次に、辞書のプレフィックスツリーで基礎を探す必要があります。 この検索は左から右に実行されます。 文字「k」、「and」、「t」を順番に見つけ、文字「t」でツリーが終了します。 つまり、「クジラ」はこのツリーに格納されている単語の1つです。 さらに検索しようとすると、次の文字が「a」であることがわかりますが、次の頂点へのポインターがないため、検索を停止します。
左側の3文字と右側の3文字が1つの単語にマージされていることがわかりますが、空のエンディングは役に立ちませんでした。 私たちは、「クジラ」が複数形、道具の場合、最初の形が「クジラ」のトークンであるという決定を下します。
次の投稿で、形態のサブシステムでまだカバーされていない問題について読んでください。