それらを結びつけるのは、それらはすべて非常に単純であるということですが、時々私たちはそれらについて考えないことがあります(とにかくそれらについて考えませんでした)。
一般に、私はそれらを集め、ノックアウトし、答えを見つけました。
だから、電撃戦の調査:
最低レベルと最も単純な質問から始めましょう。
B1。 ツイストペアにこのような奇妙な順序が選択されるのはなぜですか。青のペアは4〜5で、緑を破って3、6です。

答え
A1 :これは、2ピンの電話ジャックのために行われます。 したがって、たとえば、電話ケーブルまたはツイストペアケーブルをパッチパネルに挿入できます。
1本のケーブルでネットワークと電話の両方を取得することもできますが、私はそれを教えませんでした!
habrahabr.ru/post/158177
1本のケーブルでネットワークと電話の両方を取得することもできますが、私はそれを教えませんでした!
habrahabr.ru/post/158177
B2。 イーサネットでは、長さ12バイトのIFG(フレーム間ギャップ)と呼ばれるフレーム間に常にギャップがあります。 なぜそれが必要であり、なぜ現代の標準に存在するのですか?
答え
O2 :CSMA / CDの全盛期にIFGが広く使用されました。 これは、衝突を避けるために送信デバイスがフレームを送信する前に行う必要がある一時停止です。
実際には、複数のホストがハブに接続されている場合、ホストが同時にデータの送信を開始する可能性が高く、衝突が発生するか、1つのステーションが排他チャネルを占有します。
IFGを使用する場合、一方のホストが待機している間に、もう一方のホストが送信できます。
一般的に、IFGはマイクロ秒で測定されます。 ファストイーサネットの期間は0.96マイクロ秒です。
すでにギガビットCSMA / CDでは条件付きですが、10Gではまったく条件付きではありません。 これは、最新のスイッチのコリジョンドメインが1つのインターフェイス/ケーブルに制限されており、さらに全二重モードで動作するためです。
では、なぜ貴重な12バイトがまだ失われているのでしょうか?
誰も標準を変えたくありません。
カラフルな説明単語で検索「今表示されていないもの」
実際には、複数のホストがハブに接続されている場合、ホストが同時にデータの送信を開始する可能性が高く、衝突が発生するか、1つのステーションが排他チャネルを占有します。
IFGを使用する場合、一方のホストが待機している間に、もう一方のホストが送信できます。
一般的に、IFGはマイクロ秒で測定されます。 ファストイーサネットの期間は0.96マイクロ秒です。
すでにギガビットCSMA / CDでは条件付きですが、10Gではまったく条件付きではありません。 これは、最新のスイッチのコリジョンドメインが1つのインターフェイス/ケーブルに制限されており、さらに全二重モードで動作するためです。
では、なぜ貴重な12バイトがまだ失われているのでしょうか?
誰も標準を変えたくありません。
カラフルな説明単語で検索「今表示されていないもの」
B3。 イーサネットセグメントの長さと最小フレームサイズの制限の原因は何ですか?
答え
O3 :この事実は通常、減衰と
本当の理由は、すべて同じCSMA / CDメカニズムにあります。
ラインコリジョンを正常に検出するために、最初のビットが遠端で受信された時点で、ステーションは現在のデータの送信をまだ完了していません。
指で説明します。 半二重ネットワークを使用します。 ステーション1がデータの送信を開始するとします。 彼女に続いて、ステーション2は何かを送信しようとしていますが、ステーション1からの信号はまだ彼女に届いていないため、送信できます。 ステーション2からの信号は、データの送信が完了する前でもステーション1に到達します。 両方のステーションが衝突を検出し、送信を停止します。 すべてが素晴らしいです。 データは失われず、次回は間違いなく成功します。
次に、別の状況を想定します。 ステーション1はデータのチャンクを送信し、次の準備をしています。 しかし、信号はまだステーション2に到達していないため、送信できることを理解しています。
うん、途中で彼らは渡った。 ステーション2はこれを理解して送信を停止し、ステーション1は歪んだデータを受信しましたが、信号送信タスクを完了したと考え続けたため、次のバッチを処理しました。
その結果、フレームは失われました。なぜなら、彼らはそれを裏側で収集できなかったからです-誰もがそれを受け取ったわけではありません。 はい、上位のプロトコルはこれを検出して再度要求することができますが、無駄なミリ秒は何秒かかりますか?
冒頭に述べた条件が満たされている場合、この状況は除外されます。最初のビットがセグメントの最後に受信されたとき、送信者はまだ最後のビットを送信していません。 その後、何も失われません。
しかし、セグメントの長さに戻ります。 あなたはおそらくすでに塩が何であるかを推測し始めましたか? この条件が満たされるような長さでなければなりません。
したがって、カウントのトリッキーな方法を破棄すると、100 mは、最初のビットが受信されたときに、最後の送信が遠端によってまだ送信されていない距離になります。
このデータブロックのサイズを決定するために残ります。
ファストイーサネット標準の最小データ部分は512ビットまたは64バイトです。これは、いわゆるスロット時間です。 この図は何か似ていますか? 最小のイーサネットフレームサイズですか? (ギガビットイーサネットの場合、この値は512バイトに増加します)。
セグメントの全長に広がるのはこれらの64バイトです。
このトピックをより詳細に理解しようとし、理解しやすいように別の資料を用意しました: 100メートルイーサネット 。
www.ixbt.com/comm/tech-fast-ethernet.shtml#_Toc91050385
本当の理由は、すべて同じCSMA / CDメカニズムにあります。
ラインコリジョンを正常に検出するために、最初のビットが遠端で受信された時点で、ステーションは現在のデータの送信をまだ完了していません。
指で説明します。 半二重ネットワークを使用します。 ステーション1がデータの送信を開始するとします。 彼女に続いて、ステーション2は何かを送信しようとしていますが、ステーション1からの信号はまだ彼女に届いていないため、送信できます。 ステーション2からの信号は、データの送信が完了する前でもステーション1に到達します。 両方のステーションが衝突を検出し、送信を停止します。 すべてが素晴らしいです。 データは失われず、次回は間違いなく成功します。
次に、別の状況を想定します。 ステーション1はデータのチャンクを送信し、次の準備をしています。 しかし、信号はまだステーション2に到達していないため、送信できることを理解しています。
うん、途中で彼らは渡った。 ステーション2はこれを理解して送信を停止し、ステーション1は歪んだデータを受信しましたが、信号送信タスクを完了したと考え続けたため、次のバッチを処理しました。
その結果、フレームは失われました。なぜなら、彼らはそれを裏側で収集できなかったからです-誰もがそれを受け取ったわけではありません。 はい、上位のプロトコルはこれを検出して再度要求することができますが、無駄なミリ秒は何秒かかりますか?
冒頭に述べた条件が満たされている場合、この状況は除外されます。最初のビットがセグメントの最後に受信されたとき、送信者はまだ最後のビットを送信していません。 その後、何も失われません。
しかし、セグメントの長さに戻ります。 あなたはおそらくすでに塩が何であるかを推測し始めましたか? この条件が満たされるような長さでなければなりません。
したがって、カウントのトリッキーな方法を破棄すると、100 mは、最初のビットが受信されたときに、最後の送信が遠端によってまだ送信されていない距離になります。
このデータブロックのサイズを決定するために残ります。
ファストイーサネット標準の最小データ部分は512ビットまたは64バイトです。これは、いわゆるスロット時間です。 この図は何か似ていますか? 最小のイーサネットフレームサイズですか? (ギガビットイーサネットの場合、この値は512バイトに増加します)。
セグメントの全長に広がるのはこれらの64バイトです。
このトピックをより詳細に理解しようとし、理解しやすいように別の資料を用意しました: 100メートルイーサネット 。
www.ixbt.com/comm/tech-fast-ethernet.shtml#_Toc91050385
B4。 イーサネットオーバーヘッドの計算方法
802.3標準によると、次のものがあります。

オーバーヘッドを計算するとき、イーサネットオーバーヘッドのサイズが38または18(Dest + Source + Legth + FCS)ではなく、14バイトである理由。
答え
O4 :プリアンブルとIFGが考慮されない理由を理解するのは簡単です。 ご存じのように、イーサネットはチャネルの機能とOSIモデルの物理層を組み合わせています。 MAC DST、MAC SRC、Type、およびFCSは、データリンク層、プリアンブル、およびIFG-物理の属性です。 フレームを処理するとき、デバイスは物理層のサービスバイトを使用せずに、 有効な長さにのみ焦点を合わせることが論理的です。
同時に、帯域幅を計算する際には、38バイト+ペイロードという完全な長さが引き続き考慮されることに注意してください。
わかりましたが、FCSはどうですか? 結局、オーバーヘッドを計算する際にはほとんど考慮されておらず、ペイロード長に追加されるのは14バイト(MAC DST + MAC SRC +タイプ)だけです。
ここで悪魔は詳細にあり、答えを見つけるには、FCSの本質であるフレームチェックシーケンスに目を向ける必要があります。 IPにはソース情報の整合性を制御する機能が組み込まれていないため、これらの機能はTCP(一般的な制御-すべてのデータが正しく配信されるかどうか)およびイーサネットによって引き継がれます。 後者は、特定のフレームごとに損傷をチェックし、チェックサムを計算します。 つまり、彼はFCSフィールドを除くフレーム全体を取得して処理し、結果をチェックサムの元の値と比較し、一致しない場合は破棄します。 一致する場合、最初にFCSフィールドが削除され、次に残りのフレームが上位の機関に送信されます。 実際、この処理は初期段階でハードウェアで行われ、フレーム自体を処理してそのサイズを計算するプロセスは、実際にはヘッダーの14バイトだけを受信します。
このような興味深い算術。
forum.nil.com/viewtopic.php?f=12&p=582
同時に、帯域幅を計算する際には、38バイト+ペイロードという完全な長さが引き続き考慮されることに注意してください。
わかりましたが、FCSはどうですか? 結局、オーバーヘッドを計算する際にはほとんど考慮されておらず、ペイロード長に追加されるのは14バイト(MAC DST + MAC SRC +タイプ)だけです。
ここで悪魔は詳細にあり、答えを見つけるには、FCSの本質であるフレームチェックシーケンスに目を向ける必要があります。 IPにはソース情報の整合性を制御する機能が組み込まれていないため、これらの機能はTCP(一般的な制御-すべてのデータが正しく配信されるかどうか)およびイーサネットによって引き継がれます。 後者は、特定のフレームごとに損傷をチェックし、チェックサムを計算します。 つまり、彼はFCSフィールドを除くフレーム全体を取得して処理し、結果をチェックサムの元の値と比較し、一致しない場合は破棄します。 一致する場合、最初にFCSフィールドが削除され、次に残りのフレームが上位の機関に送信されます。 実際、この処理は初期段階でハードウェアで行われ、フレーム自体を処理してそのサイズを計算するプロセスは、実際にはヘッダーの14バイトだけを受信します。
このような興味深い算術。
forum.nil.com/viewtopic.php?f=12&p=582
B5。 実際のファストイーサネットビットレートが125 Mb / sであることをご存知ですか? なぜそう
答え
O5 :MACサブレイヤーの4ビットが0と1が交互に並んだ5つの物理ビットで表される場合、イーサネットはFDDIからの4B / 5Bエンコード方式を採用します。 これを行う理由は、すでに深い物理学です。
この場合、ソースデータは、イーサネット標準に従って100 Mb / sの速度で送信する必要があります。 この余分なビットのため、実際の速度は25%高く(4 25%以上5)、これはもちろん125 Mb / sです。
citforum.ru/nets/lvs/glava_5.shtml
この場合、ソースデータは、イーサネット標準に従って100 Mb / sの速度で送信する必要があります。 この余分なビットのため、実際の速度は25%高く(4 25%以上5)、これはもちろん125 Mb / sです。
citforum.ru/nets/lvs/glava_5.shtml
B6。 802委員会がLAN標準を扱っていることは誰もが知っています。 イーサネットが802.3であることもよく知られています
一方、イーサネットIIは現在一般的に受け入れられています。

イーサネットIIフレームと802.3フレームの違いは何ですか?それはなぜIIなのですか?
答え
O6 :802.3フレームには、通常のタイプ(EtherType)の代わりに長さフィールドが含まれます。 歴史的に、イーサネットフレームにはいくつかの標準があります(リストされているもの以外)。
その後、DEC、Intel、およびXeroxは、ユニバーサルイーサーネットイーサネットIIソリューション(企業の最初の文字によるイーサネットDIX)を完成させました。
ペイロードの合計サイズを示すために使用される長さフィールドは、一般的にあまり有益ではなく、さらに、そのようなフレームはより高いプロトコルの1つのタイプのみを運ぶことができました。 長さは最大1500(0x05dc)まで可能です。
イーサネットIIフレームでは、長さフィールドは破棄され、特殊な2バイトがアップストリームプロトコルのタイプを決定するTypeフィールド(EtherType)の下で使用されました。 802.3と明確に区別するために、値は1536(0x0600)を超えています。
たとえば、フレームがIPv4を伝送する場合、タイプは0x0800、ARP-0x0806、VLAN(802.1q)-0x8100、IPv6-0x86DD、QinQ-0x9100などになります。
pascal.tsu.ru/other/frames.html#as-h4-2325214
その後、DEC、Intel、およびXeroxは、ユニバーサルイーサーネットイーサネットIIソリューション(企業の最初の文字によるイーサネットDIX)を完成させました。
ペイロードの合計サイズを示すために使用される長さフィールドは、一般的にあまり有益ではなく、さらに、そのようなフレームはより高いプロトコルの1つのタイプのみを運ぶことができました。 長さは最大1500(0x05dc)まで可能です。
イーサネットIIフレームでは、長さフィールドは破棄され、特殊な2バイトがアップストリームプロトコルのタイプを決定するTypeフィールド(EtherType)の下で使用されました。 802.3と明確に区別するために、値は1536(0x0600)を超えています。
たとえば、フレームがIPv4を伝送する場合、タイプは0x0800、ARP-0x0806、VLAN(802.1q)-0x8100、IPv6-0x86DD、QinQ-0x9100などになります。
pascal.tsu.ru/other/frames.html#as-h4-2325214
もう少し高く上がります
B7。 LACPは、LAGのインターフェイスを管理するために使用されます。 彼はそのような状況を追跡できますか

ここでは、LAGに統合された2つの光インターフェイスによってスイッチが接続されています。 2本の光ケーブルが媒体として使用されます。1本は受信用、もう1本は送信用です。 単一のケーブルが破損した後はどうなりますか?
答え
O7 :一般的に、LACPは最も原始的なプロトコルです。 インターフェースの状態(アップまたはダウン)にのみ基づいて、LAGからインターフェースを追加するか削除するかを決定します。
1本のケーブルのみが破損した場合、1方向の伝送は停止します-レーザー信号は消えます。 原則として、スイッチは、リモート側の信号の表示を停止するとすぐに、インターフェイスをダウン状態にします。 この状況では、図のように、ケーブルが損傷し、Gi0 / 0/1インターフェイスがダウン状態になるため、SW2は信号の表示を停止します。 同時に、SW1はUpで信号とそのインターフェイスGi0 / 0/1を確認します。
SW2では、LACPはLAGからGi0 / 0/1を削除しますが、SW1では削除しません。 したがって、データ伝送の問題が発生します。
このような状況を回避するには、UDLD(UniDirectional Link Detection)プロトコルのいずれか、たとえばBFDまたはEFM OAMを使用する必要があります。
UPD: Karroplanはこの質問を修正しました:
1本のケーブルのみが破損した場合、1方向の伝送は停止します-レーザー信号は消えます。 原則として、スイッチは、リモート側の信号の表示を停止するとすぐに、インターフェイスをダウン状態にします。 この状況では、図のように、ケーブルが損傷し、Gi0 / 0/1インターフェイスがダウン状態になるため、SW2は信号の表示を停止します。 同時に、SW1はUpで信号とそのインターフェイスGi0 / 0/1を確認します。
SW2では、LACPはLAGからGi0 / 0/1を削除しますが、SW1では削除しません。 したがって、データ伝送の問題が発生します。
このような状況を回避するには、UDLD(UniDirectional Link Detection)プロトコルのいずれか、たとえばBFDまたはEFM OAMを使用する必要があります。
UPD: Karroplanはこの質問を修正しました:
LACPは、単方向リンクを完全に定義します。 1秒または30秒のタイムアウト-lacpには、高速転送と低速転送の2つのメカニズムがあります。
UDLD / BFDは、反応時間を短縮するためにのみ必要です。 さらに、かつてLACPの上にBFDの別のRFCをリリースする必要がありました。 BFDはもともとL3プロトコルであり、PortChannel全体を1つの集約リンクとして認識し、リンク全体のフォールのみを検出できます。
さらに高い
B8 このような状況では、2台のコンピューターが相互にpingを実行できますか
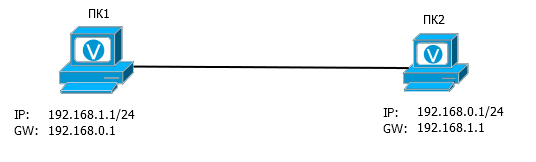
答え
O8 :はい、できます。 デフォルトゲートウェイが異なるサブネット上にあるという事実にもかかわらず、ARP要求はその検索で送信されます。
つまり、PC1は、ブロードキャストARP要求「Who is 192.168.0.1?」を送信します。 PK2はそれを受け取り、もちろん、これはそれだと答えます。 PC1はARP応答を受信し、テーブルにMACアドレスとIPアドレスを入力します。 さらに、データの交換を妨げるものは何もありません。
UPD:ユーザーmerlin-vrnは、この質問に対してより正確で包括的な回答を提供しました。
一番下の行は、このようなデフォルトルート(同じサブネットにない)を追加する前に、ルーティングテーブルにルートへのルートが必要であり、もちろん最初は存在しません。 しかし、Windowsはこっそり追加するので、pingは機能します。
つまり、PC1は、ブロードキャストARP要求「Who is 192.168.0.1?」を送信します。 PK2はそれを受け取り、もちろん、これはそれだと答えます。 PC1はARP応答を受信し、テーブルにMACアドレスとIPアドレスを入力します。 さらに、データの交換を妨げるものは何もありません。
UPD:ユーザーmerlin-vrnは、この質問に対してより正確で包括的な回答を提供しました。
PC1を192.168.0.1にするにはどうすればよいですか?
1.ローカルアドレスかどうかを確認します。 いいえ、ローカルではありません。
2.ローカルネットワーク(ここでは192.168.1.0/24)のいずれにも配置されていないかどうかを確認します。 いいえ、見つかりません。
3.ゲートウェイを探し、ARP要求を行います。 そして、どのインターフェースを通して? おっと。 192.168.0.1を探す場所は? わかりません。
「ネットワークカード1の設定で一度示された後、それを確認する」と言うでしょう。 いいね これは、「setevukha1経由の192.168.0.1/32」というルートに相当し、実際にはWindowsを作成します。
つまり 例に示されている構成は、実際には次のように構成されています。
PC1:192.168.1.1/32、192.168.0.1/32、e0経由、
PC2:192.168.0.1/32、192.168.0/e0経由。
つまり 異なるサブネット上にありますが、2つのコンピューターとローカルルートが互いに「直接」存在します。 もちろん、pingを実行します。
一番下の行は、このようなデフォルトルート(同じサブネットにない)を追加する前に、ルーティングテーブルにルートへのルートが必要であり、もちろん最初は存在しません。 しかし、Windowsはこっそり追加するので、pingは機能します。
B9。 ダイレクトブロードキャスト(192.168.0.255)と制限付きブロードキャスト(255.255.255.255)の違いは何ですか
答え
O9 :アドレス255.255.255.255に送信されるパケットは、発信元のネットワークのみに制限されます-MACアドレスはffff-ffff-ffffに設定されます。 パケットが192.168.0.255に送信される場合、最初に、すべてのルーティングルールに従って、パケットは宛先ネットワーク192.168.0.0に到達し、その後、このネットワーク上のすべてのホストに送信されます。
Q10:アドレス10.0.1.0をホストアドレスに使用できますか?
答え
O10 :はい。もちろん、たとえば、インターフェイスに構成10.0.0.0/23を適用した場合などです。 その場合、使用可能なアドレスの範囲は10.0.0.1-10.0.1.254になり、すべて使用できます。 10.0.0.255を含む。
UPD: 2番目の例は、ネットワークアドレスとブロードキャストアドレスをノードに割り当てることができる場合の/ 31マスクの使用です。
UPD: 2番目の例は、ネットワークアドレスとブロードキャストアドレスをノードに割り当てることができる場合の/ 31マスクの使用です。
B11。 リバースマスクは通常と基本的にどのように異なりますか?
答え
O11 :当然、このマスクの反転の顕著な違い、つまりゼロは、変更されるべきでない部分を示します。 しかし、結局は問題ではありません。
重要な違いは、ここではゼロが1と交互になる可能性があることです。 つまり、サブネットマスクに次のセットを含めることができない場合:10110001、リバースマスクには含めることができます。
したがって、たとえば、アドレス10.5.X.123を持つすべてのサブネット上のホストを選択し、インターネットへのアクセスを許可できます。 または、偶数アドレスをすべて奇数アドレスから分離し、送信者アドレスに基づいてトラフィック分配を正確に半分に実装します。
UPD:違いは、直接マスクがネットワーク上で動作するという事実と、逆にホスト上で動作するという事実にもあります。
重要な違いは、ここではゼロが1と交互になる可能性があることです。 つまり、サブネットマスクに次のセットを含めることができない場合:10110001、リバースマスクには含めることができます。
したがって、たとえば、アドレス10.5.X.123を持つすべてのサブネット上のホストを選択し、インターネットへのアクセスを許可できます。 または、偶数アドレスをすべて奇数アドレスから分離し、送信者アドレスに基づいてトラフィック分配を正確に半分に実装します。
UPD:違いは、直接マスクがネットワーク上で動作するという事実と、逆にホスト上で動作するという事実にもあります。
B12。 169.254.0.0/16のアドレスが必要な理由(WindowsではAPIPAを、UNIXではnonzeroconfを自動構成します)
そして、そのようなpingが機能しない理由:

答え
O12 :169.254.0.0/16ネットワークはもともとリンクローカルネットワークとして考えられていました。
その本質は、ホストに静的IPアドレスがなく、たとえばDHCPサーバーから自動的に受信できない場合、169.254.0.1-169.254.255.254の範囲のアドレスをホストに割り当てることです。 その後、彼はこのネットワーク上の同じアドレスを持つ他のホストと通信できるようになります。
アドレスは、既存のアドレス(ARP要求によってチェックされる)と一致しないように、乱数ジェネレーターによりランダムに選択されます。
アプリケーションの例は、ステーションのタスクが互いに通信することであるアドホックネットワークです。
しかし、そのようなネットワークの重要な特徴は、このセグメントに位置するステーション間でのみ関係が可能であるということです。したがって、定義内のフレーズ「リンクローカル」です。 パケットをルーターより先に送信することはできません。 さらに、標準に従って、ホストにゲートウェイアドレスがある場合でも、どのような状況でもホストにパケットを転送するべきではありません。
これは、図のようにpingが機能しないという事実を説明しています。 すべてはRFCに準拠しています 。
その本質は、ホストに静的IPアドレスがなく、たとえばDHCPサーバーから自動的に受信できない場合、169.254.0.1-169.254.255.254の範囲のアドレスをホストに割り当てることです。 その後、彼はこのネットワーク上の同じアドレスを持つ他のホストと通信できるようになります。
アドレスは、既存のアドレス(ARP要求によってチェックされる)と一致しないように、乱数ジェネレーターによりランダムに選択されます。
アプリケーションの例は、ステーションのタスクが互いに通信することであるアドホックネットワークです。
しかし、そのようなネットワークの重要な特徴は、このセグメントに位置するステーション間でのみ関係が可能であるということです。したがって、定義内のフレーズ「リンクローカル」です。 パケットをルーターより先に送信することはできません。 さらに、標準に従って、ホストにゲートウェイアドレスがある場合でも、どのような状況でもホストにパケットを転送するべきではありません。
これは、図のようにpingが機能しないという事実を説明しています。 すべてはRFCに準拠しています 。
B13。 プライベートと127/8を除いて、合計でいくつのアドレスが消えるか知っていますか?
答え
O13 :実際、私たちは失います:
1つのクラスAネットワーク:127.0.0.0/8
1つのクラスBネットワーク:169.254.0.0/16
単一ネットワーク/ 10: 100.64.0.0/10
単一ネットワーク/ 15:198.18.0.0/15
5つのクラスCネットワーク:192.0.0.0/24、192.0.2.0/24、192.88.99.0/24、198.51.100.0/24、203.0.113.0/24。
1つのネットワーク/ 4:240.0.0.0/4
合計285410560アドレス。
これらは無駄です。
1つのクラスAネットワーク:127.0.0.0/8
1つのクラスBネットワーク:169.254.0.0/16
単一ネットワーク/ 10: 100.64.0.0/10
単一ネットワーク/ 15:198.18.0.0/15
5つのクラスCネットワーク:192.0.0.0/24、192.0.2.0/24、192.88.99.0/24、198.51.100.0/24、203.0.113.0/24。
1つのネットワーク/ 4:240.0.0.0/4
合計285410560アドレス。
これらは無駄です。
トレース中にこのような状況が発生する理由
B14。 希望の1つとして、3つのトレース結果すべてについて、遅延値が次のものよりも高い
[eucariot]$ traceroute 8.8.8.8
traceroute to 8.8.8.8 (8.8.8.8), 30 hops max, 40 byte packets
...
6 vl545.mag02.lon01.atlas.cogentco.com (149.6.3.153) 11.464 ms 11.378 ms 11.347 ms
7 te0-7-0-5.ccr21.lon01.atlas.cogentco.com (154.54.74.109) 5.653 ms 4.725 ms 6.209 ms
8 te3-2.ccr01.lon18.atlas.cogentco.com (154.54.62.66) 4.951 ms te2-1.ccr01.lon18.atlas.cogentco.com (154.54.61.214) 5.050 ms te3-2.ccr01.lon18.atlas.cogentco.com (154.54.62.66) 5.086 ms
14: , , , /. , .
UPD: JDima :
, . , 3 , , , 2. ?
, . . , , .
, , — Round Trip Timer, .
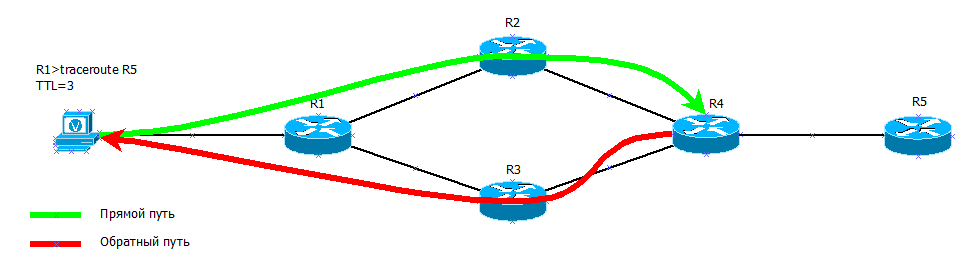
TTL=3 R4 , . R3 — 26- , 90 /. .
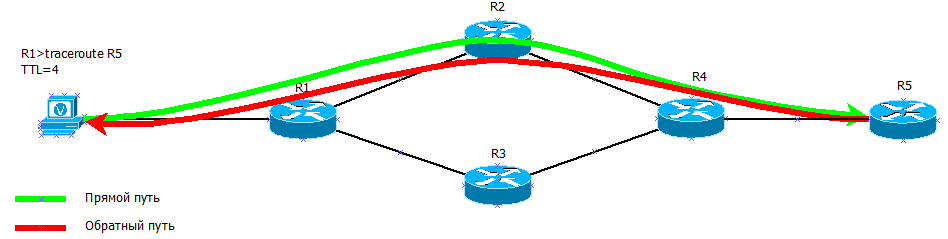
, traceroute TTL=4 .
UPD: JDima :
:
time exceeded , .
:
Cat6500. «» (, , , ssh ..) MSFC. MSFC PFC ( DFC ), . , MSFC.
TTL 0 PFC, , , ( time exceeded ( MPLS, )). MSFC. , ICMP , , .
, . , 3 , , , 2. ?
, . . , , .
, , — Round Trip Timer, .
TTL=3 R4 , . R3 — 26- , 90 /. .
, traceroute TTL=4 .
15. ( ). , ?
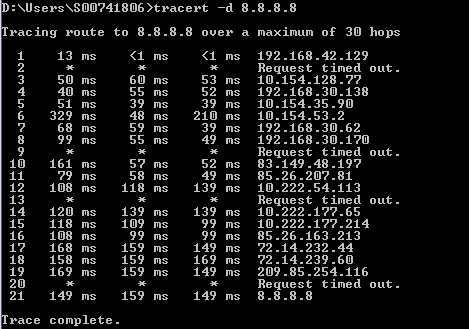
15: RFC , AS.
, - , , . , TTL expired , traceroute.
, .

.
, - , , . , TTL expired , traceroute.
, .
.
16. ?
1. te2-4 PAO2 bl (69 22 1 3 209) 1 160 1 060 1 029 4.ar5.PAO2.gblx.net (69.22.153.209) 1.160 ms 1.060 ms 1.029 ms
2. 192.205.34.245 (192.205.34.245) 3.984 ms 3.810 ms 3.786 ms
3. tbr1 sffca ip att net (12 123 12 25) 74 848 ms 74 859 ms 74 936 ms tbr1.sffca.ip.att.net (12.123.12.25) 74.848 ms 74.859 ms 74.936 ms
4. cr1.sffca.ip.att.net (12.122.19.1) 74.344 ms 74.612 ms 74.072 ms
5. cr1.cgp ( ) cil.ip.att.net (12.122.4.122) 74.827 ms 75.061 ms 74.640 ms
6. cr2.cgcil.ip.att.net (12.122.2.54) 75.279 ms 74.839 ms 75.238 ms
7. cr1.n54ny.ip.att.net (12.122.1.1) 74.667 ms 74.501 ms 77.266 ms
8. gbr7.n54ny.ip.att.net (12.122.4.133) 74.443 ms 74.357 ms 75.397 ms
9. ar3.n54ny.ip.att.net (12.123.0.77) 74.648 ms 74.369 ms 74.415 ms
10.12 126 0 29 (12 126 0 29) 76 104 76 283 76 174 12.126.0.29 (12.126.0.29) 76.104 ms 76.283 ms 76.174 ms
11.route-server.cbbtier3.att.net (12.0.1.28) 74.360 ms 74.303 ms 74.272 ms
16: , MPLS-.
, MPLS, IP-, .
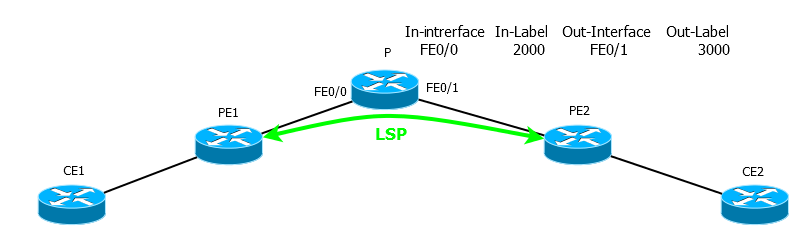
CE1 CE2. PE1 PE2 LSP.
CE1 TTL=2. P MPLS-, 2000. TTL 1, P , , TTL-expired CE1. ICMP-, CE1, ! MPLS 2000 3000 , FE0/1. .
E2, 2 IP.
2 MPLS .
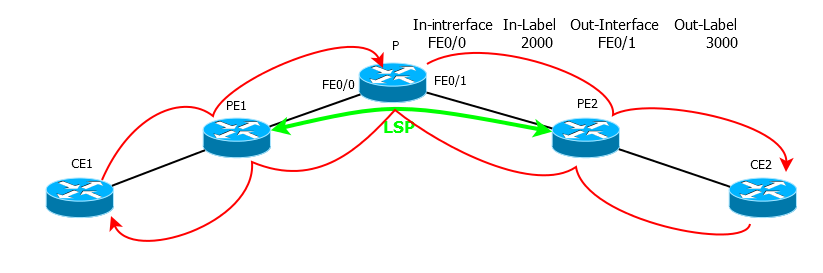
, 2 , .
TTL=3, PE2 2 , 1 — .
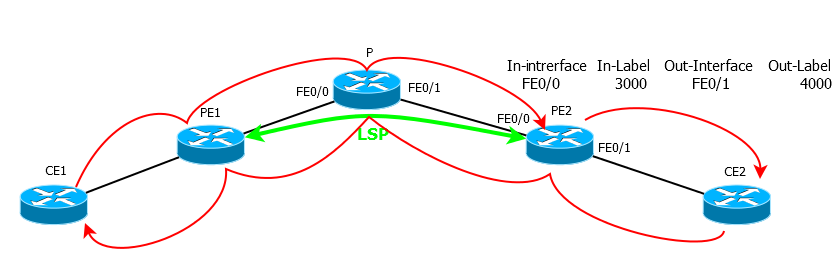
— - .
UPD: , «» TTL exceed 2, .
, MPLS, IP-, .
CE1 CE2. PE1 PE2 LSP.
CE1 TTL=2. P MPLS-, 2000. TTL 1, P , , TTL-expired CE1. ICMP-, CE1, ! MPLS 2000 3000 , FE0/1. .
E2, 2 IP.
2 MPLS .
, 2 , .
TTL=3, PE2 2 , 1 — .
— - .
UPD: , «» TTL exceed 2, .
17. cisco . ?


17: , ICMP- , ICMP-, . ICMP- , , ARP.
! :
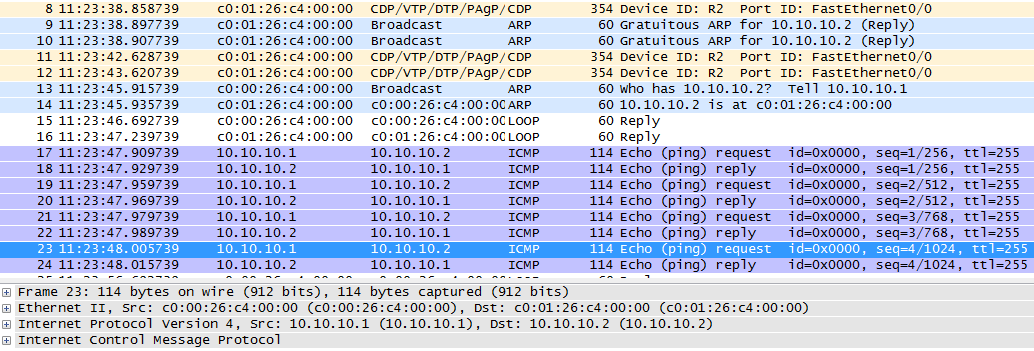
, ICMP- . ARP , ICMP . , 4 ICMP- 4 .
blog.ipspace.net/2007/04/why-is-first-ping-lost.html
! :
, ICMP- . ARP , ICMP . , 4 ICMP- 4 .
blog.ipspace.net/2007/04/why-is-first-ping-lost.html
18. , : A, B, C. 10/8, 172.16/12, 192.168/16?
18: , , — , . . IANA.
Dear YYY,
Thanks for contacting us.
We do not have the answer to your question and suggest you contact the authors of «Address Allocation for Private Internets» (RFC 1597), the document first setting these ranges aside. You can find details about the document here: www.rfc-editor.org/info/rfc1597
Kind regards,
Dear YYY,
Thanks for contacting us.
We do not have the answer to your question and suggest you contact the authors of «Address Allocation for Private Internets» (RFC 1597), the document first setting these ranges aside. You can find details about the document here: www.rfc-editor.org/info/rfc1597
Kind regards,
1597 ) .
:
Dear YYY,
Thank you for your inquiry.
For more information about the private use space, see www.rfc-editor.org/rfc/rfc1918.txt.
As to why those specific blocks were chosen, we believe 10/8 was chosen because sri-nic.arpa (10.0.0.51) was embedded in pretty much every unix and multics system as the hardcoded source of hosts.txt and various other files. For the others, the decision was made that since a class A was allocated, there should be blocks of class Bs and Cs too. It could just be that those blocks were available.
Hope that helps.
Best regards,
Michelle Cotton
Manager, IANA Services
ICANN
- . .
, , , . , , .
? ?
— . , ? 192.168.1.110/24 , 192.168.1.0/24. .
— . , , . .
, , ?
, , , , .
:
? .
UPD :
, 4 «Interworking with TCP/IP» . , . , UNIX' , .. (192.168.1.255/24), — , «» .
. , , , . , ? ( 192.168.1/24, 192.168.1.110/24)
.