私はMahout in Actionの本を読んでいます。 「本を見る-イチジクが見える」という効果に直面した それをなくすために、メモを取ることにしました。
Apache Mahoutは、機械学習アルゴリズムを操作するためのライブラリで、Hadoopのアドオンとして、または単独で使用できます。 このライブラリは、 協調フィルタリング 、 クラスタリング 、および分類方法を実装しています 。
協調フィルタリングに基づく推奨システムを検討しています。 ユーザーベース(ユーザーベース)またはプロパティ指向(アイテムベース)にすることができます。
協調フィルタリングは、ユーザーグループの既知の設定(推定)を使用して別のユーザーの未知の設定を予測する予測方法の1つです。 彼の主な仮定はこれです。過去に同じ被験者を評価した人は、将来、他の被験者にも同様の評価をする傾向があります。 (ウィキペディアから)
ユーザー指向の推奨システムの基本概念の1つは、ユーザーの類似性を判断するためのメトリックです。 さまざまなユーザーによる映画の視聴回数と評価に関するデータがあるとします。 XとYの 2人のユーザーを比較します。 彼らは映画X(x 1 、x 2 、...、x n )およびY(y 1 、y 2 、...、y m )を評価しました。ここで、 n 、 mはそれぞれ第1および第2ユーザーによって与えられた評価の数です。 N-両方のユーザーが同じ映画に設定した評価の数(最初と2番目に見た映画のセットの共通部分)。 (x i 、y i )は、ユーザーが1つの映画に付けた評価のペアであると想定しています。
Mahoutは、いくつかのアルゴリズムに基づいてメトリックを実装しています。 Mahoutでの実装ではなく、アルゴリズム自体について説明します。
ピアソン相関係数(4.3.1)
カッコ内では、オーウェン、アニル、ダニング、フリードマンの著書「行動のマハウト」の章をマークします。
Mahout- ピアソンCorrelationSimilarityでの実装。
ピアソンの相関係数は数K(-1≤K≤1)であり、2組の数が対になって類似する傾向を示します。 つまり 1番目と2番目のセットの数の間でほぼ線形の関係を形成します。 x i = iによって (すべてのi Bについて 、ほぼ同じになります)。 依存関係が線形の場合、相関係数は1です。逆数が-1の場合、依存関係がない場合は0です。
次の式で計算されます。

右ベクトル入力。
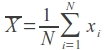 -算術平均。 このようにして、データを中央に配置します。 手動で計算する場合、これを考慮する必要がありますが、Mahoutでの相関の実装はこれを自分で処理します。
-算術平均。 このようにして、データを中央に配置します。 手動で計算する場合、これを考慮する必要がありますが、Mahoutでの相関の実装はこれを自分で処理します。
ピアソン相関メトリック問題(4.3.2)
200の同一の映画を視聴した2人のユーザーは、3つの同一の映画を視聴して同じ評価を与えた2人のユーザーとは異なる評価を付けても、より類似していると仮定するのが論理的です。 しかし、式からは逆の結果が得られます。
2番目の欠点は、評価が1つしかないユーザーの相関を計算できないことです(分母がゼロになるため)。
係数は、ユーザーの1人がすべての映画に同じ評価を与えた場合にも定義されません。 たとえば、ユーザーは3つの映画を見て、5の評価を与えました。再び、分母はゼロです。
相関の重み(4.3.3)
最初の欠点を解消するために、相関重みの概念が導入されました。 計算に多くのパラメータが使用される場合、正の相関には1が掛けられ、負の相関には-1が掛けられます。 T.O. 多数の同一の映画が視聴されたが、反対の評価が設定された場合、相関は正になります。
また、係数の計算に使用されるパラメーターが少ない場合は、1未満の数値を乗算して、ユーザーの類似性を減らすこともできます。
ユークリッドメトリック(4.3.4)
Mahout- EuclideanDistanceSimilarityでの実装。
実装は、ユーザー間の距離を見つけることです。 ユーザーは、座標推定を使用して多次元空間内のポイントとして機能します。 映画の両方のユーザーによって与えられた評価のみが考慮されます。
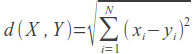
距離が短いほど、ユーザーの好みは似ています。 したがって、Mahoutで実装されたメトリックは、 K = 1 /(1 + d)を返します。 前のメトリックとは異なり、これは0〜1の値を取ります。係数が大きいほど、ユーザーの好みが似ています。
このメトリックの欠点は、1つの映画を同じ方法で評価したユーザー(他の一般的な映画はない)は、100の映画をほぼ同じ評価したユーザーよりも似ていることです。
コサイン係数(4.3.5)
Mahoutの実装-PearsonCorrelationSimilarityを使用します 。
これは、点O(0,0、...)とユーザー点X(x 1 、x 2 、...) 、 Y(y 1 、y 2 、...)によって形成される2つの線の間の角度の余弦です。
-1≤cos A≤1 角度A = 0(cos A = 1)の場合、ユーザーは似ています。 角度A = 180(cos A = -1)の場合、ユーザーの好みは反対です。 角度が90度に近い場合、これら2人のユーザーの好みの間に相関関係はありません。 コサイン係数の詳細をご覧ください。
Mahoutにはこのメトリックの特別な実装はなく、ピアソン相関メトリックを使用して計算されます。 手動計算は、次の式に従って実行できます。 右側のベクトル表記は、座標を中心に配置しないという点でのみピアソンの相関と異なります。

スピアマンの相関係数(4.3.6)
Mahout- スピアマンCorrelationSimilarityの実装。
スピアマンの相関係数は、ランク付けされた変数間のピアソン相関係数として定義されます。 最も優先度の低い映画の評価は1、次は2などです。 すべての推定値を設定した後、ピアソン相関係数が計算されます。
このメトリックの欠点は、作業が遅いことです。 結局、相関係数を計算する前に、ランキングを実行する必要があります。 さらに、このメトリックにはピアソンメトリックに欠陥があります。
谷本比(4.3.7)
Mahout- TanimotoCoefficientSimilarityでの実装。
Tanimoto係数は、1番目と2番目のユーザー(交点)のすべてのプロパティの数に対する1番目と2番目のユーザー(交差)の両方で満たされたユーザー数の比率です。K= I / U このメトリックは、設定値がブール値である場合に使用することをお勧めします。
対数尤度(4.3.8)
Mahout- LogLikelihoodSimilarityでの実装。
メトリック計算アルゴリズムは、以前のアルゴリズムとは異なり、完全に直感的ではありません。
最初のユーザーがn本の映画を、2番目のユーザーがpを 、 2人のユーザーが合計で見ている(関連付け)とします。

*-映画はユーザーによって評価されていません(または視聴されていません)。 フィルムの評価が1の場合は1、それ以外の場合は0です。


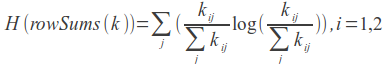
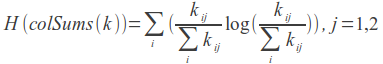
LLR = 2(H(k)-H(rowSums(k))-H(colSums(k)))は対数尤度係数です。
このアルゴリズムの詳細: 数式 、 実装 。
誰かが重宝してくれたら嬉しいです。 私たちはPMのエラーについて書き、コメントで荒らしについて書きます。