Githubは素晴らしいサイトです。 しかし、プロジェクトAを見つけて、他に類似したプロジェクトが何であるかを知りたいとします。 になる方法
GitHub APIを分解するために座ったのは、このインスピレーションでした。 数週間の自由時間の後、これは何が起こったかです:
ほとんどのプロジェクトでは、いくつかの本当に興味深い提案があります。 次に例を示します。angle.js 、 フロントエンドブックマーク 、 three.js
推奨事項を作成するための主なアイデアは、「このプロジェクトにアスタリスクを付けた開発者もアスタリスクを付けます...」です。 また、アイデアの詳細、その欠点、およびコードへのリンクを以下に示します。
おそらく、私は機械学習や推奨システムの構築の分野の専門家ではないことを認めるべきです。 以下に記載されているのは、実験的な突撃と好奇心の結果です。
スタートのアイデア
プロジェクトAのすべてのフォロワーを分析し、フォローしている他のプロジェクトを確認し、最も頻繁に繰り返されるプロジェクトを選択しましょう。 残念ながら、このアプローチは惨めに失敗しました。推奨事項の検索結果の中で、最も人気のあるプロジェクトが最初に来ることがよくありますが、必ずしも現在のプロジェクトに関連するわけではありません。 すべてのGitHubは、今日最も人気のあるBootstrapを愛しています。
一般的な星の重さはどれくらいですか?
例:
プロジェクトA-星が100個のみ
プロジェクトB-星が200個のみ
プロジェクトC-星は1000個のみ
100人の同じ開発者がプロジェクトAとBにアスタリスクを付け、100人の同じ開発者がプロジェクトAとCにアスタリスクを付けたとします。どのプロジェクトBまたはCがプロジェクトAに近いでしょうか? 明らかに-B.彼のフォロワーの半分はプロジェクトAをフォローしています。プロジェクトAに気づいたのはCフォロワーの10%だけです。
3つの変数を1つの類似性式にまとめるにはどうすればよいですか? 私はゆっくり考え、両方のプロジェクトの星の総数から星の総数の割合を考慮するという考えはすぐには得られませんでした。
similarity = 2 * shared_stars_count / (project_a_stars + project_b_stars)
式は非常に良い推奨事項を提供します。 後でCameron Davidsonから学んだように、この式は1946年に2人のオタクによって派生しました(これは誰かを怒らせるための試みではなく、彼らは本当に植物学の専門家でした): SorensenとDyce 。
APIの問題
残念ながら、GitHubには、1回のリクエストですべてのプロジェクトフォロワーに関する情報を取得できるバルクAPIがありません。 すべての不便なことに、1時間あたり5,000リクエストという制限により、プロジェクト分析が耐えられないほど長くなります。 Addi Osmaniは、数百人のフォロワーのみを分析することに制限することを提案しました。 実験的に、プロジェクトの500人のフォロワーをランダムに選択しても、推奨の結果は悪化しません。
プロジェクトAのランダムなN人のフォロワーのプロジェクト類似性メトリックは、次のように書き直されました。
alpha = N/project_a_stars
similarity = 2 * N / (alpha * (N + project_b_stars))
この言い回しにより、ほぼ同じ数の星を持つプロジェクトが互いに近くなり、人気のあるプロジェクトからノイズが十分に排除されます。
残念ながら、N = 500の場合でも、1つのプロジェクトの分析の構築時間は約7分かかります。
しかし、同様のプロジェクトをすべて事前に計算するとどうなりますか?
この推奨事項は、星が200個以上あるプロジェクトに適しています。 しかし、GitHub'eにはそのようなプロジェクトがいくつありますか? 判明したように、 7000を少し上回りました(コードを書いている時点では約7,300でした)。
人気のあるリポジトリのすべてのフォロワーのニックネームを検索するためのクモを書いて、私は約457,115人のユニークユーザーを見つけました:)。 次に、ユーザーごとにお気に入りのプロジェクトを取得する必要があります。 しかし、どれくらい時間がかかりますか? 1時間あたり5,000リクエストという制限を考えると、フォロワーあたり300のスターという非常に悲観的な推定値があったとしても、停止せずに11日間githubを「掘る」必要があります。
11日間は趣味としてはそれほどではないでしょうか? このタスクは、githubでトークンを共有する準備ができている良き友人がいる場合、1週間で処理できるため、十分に分散されています。 同じ夜、クモがお気に入りのフォロワープロジェクトを収集するために現れました。
ネットをざわめく楽しさ
役に立たない事実
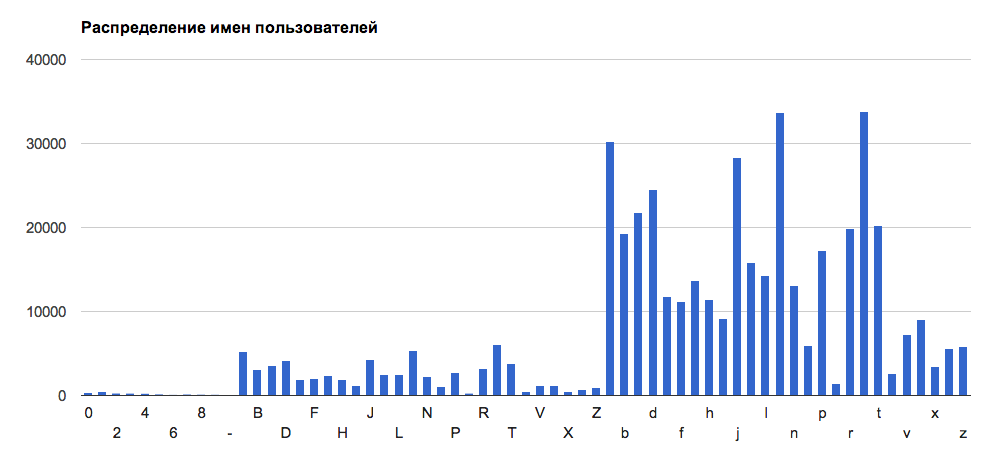
GtHubでは、ほとんどのニックネームは文字「s」で始まります。 ユーザーの後には、「m」と「a」のユーザーが続きます。 大文字の「Q」のニックネームは、番号2のニックネームほど一般的ではありません。
クラウドへ
スパイダーの結果をS3にアップロードしました。 最新のブラウザはすべてCORSを認識するため、通常のajaxリクエストを使用して、推奨事項を含む必要なjsファイルを取得できます。 プロジェクトの計算された推奨事項がクラウドに存在しない場合、サイトは推奨事項を構築するオンラインモードに移行します。 githubで認証して、大きなクォータを取得します。 中間データはローカルのIndexedDBに保存されるため、ページを閉じた後でもインデックス作成を再開できます。
コード
親愛なるhabrachitatel、あなたが推奨事項を改善する方法を知っているなら、私は大喜びです! サイトコードは、 anvaka / gazerから入手できます。
好きなプロジェクトに星を付けてください-これはリポジトリの作者だけでなく、他の開発者が適切なプロジェクトを見つけるのにも役立ちます:)。
最後まで読んでくれてありがとう。