
Evernoteに参加した後、私が最初にしたことは、Evernote for Macで自動検索プロンプトを考えて実装する作業でした。
現在は次のようになっています。
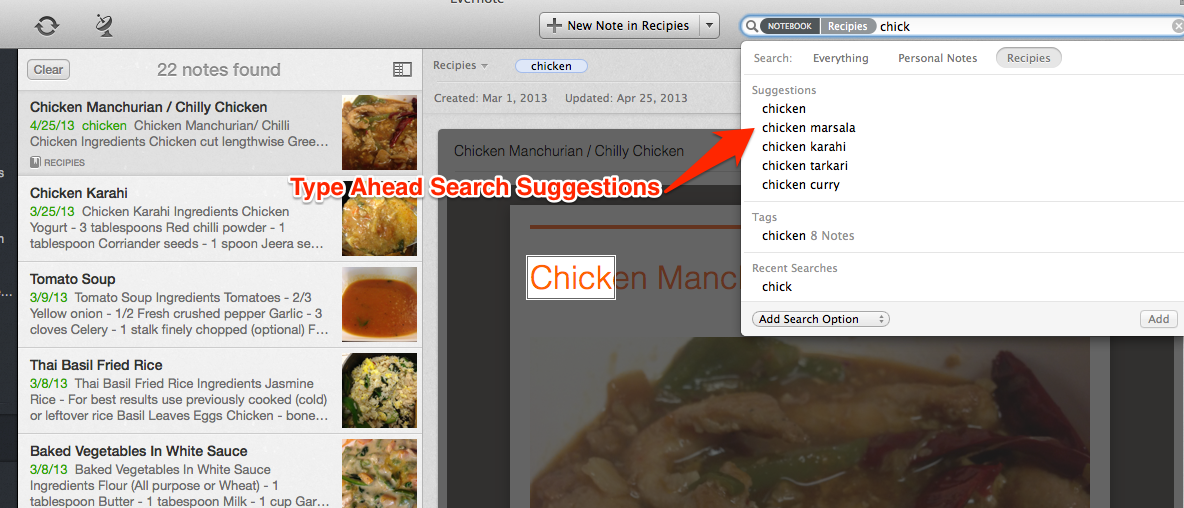
私たちのほとんどは、クエリを正確に定式化できず、検索行と点滅するカーソルが1対1であるという事実に時折遭遇します。 この問題を解決するために、入力時に提供される動的な検索候補が追加されました。これは、ユーザーのメモに基づいて形成されます。
この記事では、Evernoteでの検索のヒントの実装のいくつかの機能に触れたいと思います。
Evernoteの検索のヒントは他とどのように違いますか?
私たちの多くにとって、検索のヒントは日常生活の不可欠な部分になっています。 ヒントの前にGoogle検索がどのようなものであったかを覚えるのはそれほど簡単ではありません。 それほど前のことではありませんが、広く分布しているという事実にもかかわらず、私たちはすでに、私たちが見るあらゆる検索文字列から適切なクエリオプションのドロップダウンリストを期待しています。
外観が似ているため、さまざまなサービスのヒントは実際にはさまざまな方法で機能します。 Googleは、増え続ける検索クエリのデータベースからオプションを構築しています。 そのため、ユーザーは他の人が頻繁に探していたオプションを求められますが、これらのオプションは彼にはまったく馴染みがないかもしれません。 ただし、このモデルは、世界中で最も多様な情報を見つけることができるWeb検索には適しています。
Evernoteでの検索の場合、私たちは自分の情報について話しています。 Evernoteの検索結果には、追加したデータが表示され、それを使用してヒントが生成されます。 孤立した一連のメモを扱っているため、許可されていないユーザーのデータで補足することはできません。 したがって、他の多くのサービスがビッグデータの問題について話している一方で、Evernoteは何百万もの小さなデータの問題に直面しています。 すべてのユーザーと同様に、各データセットは一意です。
もう1つの違いは、ヒントを作成するために使用するコンテンツのタイプです。 検索ヒントをサポートする多くのサービスは、有限の(大規模ではありますが)セットから個別のクエリオプションを提供します。これらは、以前に入力した検索クエリ、人、企業などです。Evernoteでは、構造化されたいいえ、メモや言語に含まれています。 システムは、メモ自体の内容を分析することにより、ユーザーへのプロンプトの関連性を判断します。
実装プラットフォームの選択
私たちはクロスプラットフォームサービスに取り組んでおり、Evernoteユーザーが好きなデバイスで同じように快適に作業できるようにしています。 したがって、最初にプロンプトを実装するプラットフォームを選択する際に、すべてのクライアントですぐに使用できるようにするためにサーバー側でシステムを作成するか、単一のクライアントでネイティブ実装で開始するかを選択する際に、難しい決定を行う必要がありました。 2番目のオプションを選択し、いくつかの理由でMacを使い始めました。
- 他の検索機能と同様に、検索ヒントをオフラインで利用できるようにしたかったのです。
- プラットフォームを活用したかったのです。 Mac OSは、タスクを達成するために使用できる印象的な言語APIセットを提供します。
- 生産性とユーザーエクスペリエンスを確保したかったのです。たとえそれが、私たち自身により多くの仕事をしなければならなかったとしても。
詳細
この機能の基礎となる3つの主要なコンポーネントは、用語のインデックス、プロンプトの作成、およびそれらの抽出です。
用語の索引
検索ヒントは、メイン検索インデックスとは別の逆インデックスに保存されます。 検索インデックス自体を使用する可能性を検討しましたが、理論的にはそれを基礎とすることはできますが、個々のキーワードの検索に集中しすぎており、出力は非常に低品質のヒントを与えることがわかりました。
そのため、インデックスでは、各用語を、それを含むメモのリストにリンクしました。
ツールチップを作成する
ユーザーが検索バーに入力し始める前でも、検索ヒントのメカニズムは機能し始めます。 ノートを作成、変更、または削除するたびに、タイトル、タグ、およびノートの内容から潜在的なヒントのリストが生成され、それらは逆索引にソートされます。
次のように機能します。
ノートのテキストで個々の単語を見つけることから始めます。 単語は一連のフィルターを通過して、テキストを正規化し(小文字、発音区別符号を削除するなど)、ストップワードを削除します(あまりにも一般的です)。 フィルタリングされた単語は、特定のテキストに関連する可能性のあるフレーズにさらにグループ化できます。 最後に、フィルターを通過した単語とフレーズは、インデックスエントリとしてシリアル化されます。
このステップでは、一部の言語の機能を考慮することも必要です。 たとえば、中国語と日本語では、単語を互いに区切るためにスペースを使用しません。 したがって、単語の境界を見つけるには、より複雑なアルゴリズムを適用する必要があります。 この問題は、メモに複数の言語のエントリが一度に含まれる可能性があることを考えると、さらに面白くなります(さらに難しくなります)。
そしてもちろん、プロセス全体はバックグラウンドで行われ、システムの現在使用されていないリソースを使用して、ユーザーに干渉しないようにします。
ヒントを取得する
検索する準備ができました-今何が起こっていますか? ユーザーが検索文字列にテキストを入力し始めると、ツールチップ抽出システムは、主にコンテキストによって入力クエリに該当し、ユーザーが探しているノートブックとラベルの組み合わせを満たすノートのセットを決定します。 次に、検索クエリの入力された部分がヒントインデックスで検索され、一連の可能なフレーズの末尾が取得されます。 最後に、文脈的に関連するノートに分類されないすべてのエンディングを除外します。
次に、各ヒントを評価し、 TF-IDFに基づく特別な式に従って関連性によってランク付けします。 最も評価の高いヒントは決勝戦に進み、非常によく似たヒント(「アイススケート」と「アイススケート」など)が組み合わされます。
多くの点で、このコンポーネントは最も複雑ですが、1秒以内にユーザーに結果を提供する必要があるため、最速でなければなりません。 したがって、パフォーマンスの観点から、ヒントシステムのこの部分に特に注意を払いました。
次は何ですか
Evernote for Macを使用していて、この機能をまだ試していない場合は、この機能を使用して印象をお聞かせください。
将来、この機能を他のEvernoteクライアントに追加する予定です。