- Unixパイプラインは異なるプロセスで非同期に実行されますが、ここでは1つのプログラムのフレームワーク内で処理を実装する必要があり、並列化は望ましくない場合があります。
- 必ずしもテキストではないデータを送信できますが、「リニア」という用語で特徴付けることができます。
- バイト単位でファイルを読み取り、
- UTF-8でのデコード、
- プリプロセッサ
- 字句解析
- 解析
この場合、データ全体をメモリに保存する必要がないのは秘密ではありません。 メモリ内に残ることなく、変換のすべての段階をすぐに通過する部分でファイルを読み取る方がはるかに効率的です。
コンバーターは「パイプライン」の形式で配置され、それぞれが前のパイプラインからデータを受け取ります。 コンバーターはデータ型を変更することもできます。たとえば、レクサーの入力には文字があり、出力にはトークンがあります。
私はこれらのアルゴリズムの公開に値する実装を持っていないので、一般的なアイデアと実装スキームに限定します。 サンプルスキームはC ++で提供され、テンプレートと同様に仮想および多重継承を使用します 。
特に気にすることなく線形データの処理を設計するとどうなりますか
コンバーターソフトウェアインターフェイスの可能な実装を見てみましょう。 最も単純なバージョンでは、3種類のコンバーターが使用可能です。
class Source { … public: T getData(); … }; class Sink { … public: void putData(T); … }; class Universal { … public: void process(); };
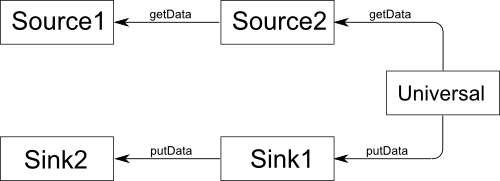
図1.単純なパイプライン実装のスキーム。
このようなパイプラインの簡単な例は、「加算器」です(std :: cinから数値を読み取り、ペアに入れ、std :: coutに出力します。これは動作するC ++プログラムです)。
#include <iostream> // std::cin class IntSource { public: int getData() { int next; std::cin>>next; return next; } bool good() const { return std::cin.good(); } }; // std::cout class IntSink { public: void putData(int data) { std::cout<<data<<std::endl; } }; // IntSource IntSink class IntUniversal { IntSource source; IntSink sink; public: void process() { int i1 = source.getData(); int i2 = source.getData(); if( good() ) sink.putData(i1+i2); } bool good() const { return source.good(); } }; int main() { IntUniversal belt; while( belt.good() ) belt.process(); }
Sourceコンバーターは、パイプライン内の次のコンバーターがそこからデータのチャンクを受信できるようにするインターフェイスを提供します。 これに対して、Sinkコンバーター(吸収体)は、データの準備ができているという以前のコンバーターから信号を受信できます。 ソースは「オンデマンド」でデータを生成しますが、データの受信は処理しますが、Sinkは次の要素にデータを送信できますが、前の要素に満足した場合にのみ受信します。 完全に自由なのはユニバーサルコンバーターだけです。前のコンバーターからデータを受信し、必要に応じて次のコンバーターにデータを転送できます。 コンバーターの機能の制限に基づいた、このような単純化された「コンベヤー」に関するいくつかの単純で強制的なルールに注意してください。
- パイプラインの最初の要素はSourceです。
- 最後の要素はシンクです。
- シンクコンバーターは別のシンクコンバーターのみに直接先行でき、ソースコンバーターは別のソースコンバーターのみに直接追従できます。
- ユニバーサルコンバーターは、ソースの後にシンクの前になければなりません。
- ソースk :: getData
- ...
- ソースn :: getData
- ユニバーサル::プロセス、
- シンクl :: putData
- ...
- シンク1 :: putData
- ユニバーサル::プロセス。
コンベアの改善
SourceとSinkを使用すると、手順の実装とその有効性に制限が課せられます。 パイプラインがUniversal、...、Universalのようになっている場合、プログラマはより便利になります。 コンベアに本当に欠けているもの、つまり「テープ」を追加することで、この願いをかなえることができます。 テープは、コンバーターの「間にある」データを保管するメモリー領域になります。 コンバーターがデータを生成するとすぐに、次のコンバーターが読み取ることができるテープに配置されます。 コンベアは以前より複雑になり、それ自体では制御できないため、ベルトとコンバータを監視する特別な「コンベアマネージャー」が必要です。 これから、インターフェイスを持つ基本クラスから継承者の形でコンバータを構築します。 以下に簡略化したビューを示します。
class UniversalBase { public: virtual void process()=0; }; template<class S> class UniversalSource; template<class T> class UniversalSink; // template <class S> class UniversalSource : public virtual UniversalBase { UniversalSink<S>* next; protected: void putOnBelt(const S&); }; // template <class T> class UniversalSink : public virtual UniversalBase { UniversalSource<T>* prev; protected: T getFromBelt(); }; // , T S template <class T, class S> class Universal : public UniversalSink<T>, public UniversalSource<S> { };
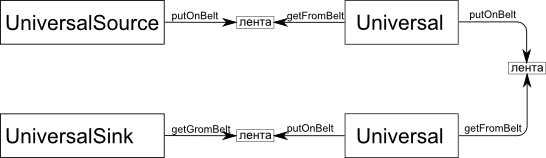
図2.改善されたパイプライン実装のスキーム。
プロセス関数は、特定のコンバーターごとに独自の方法で実装され、その目的の本質を満たします。 彼女の仕事は、一定量のデータを生成し、それをコンベヤマネージャに転送してテープに配置することです。 これを行うために、プロセスは基本クラスで定義されたputOnBelt関数を呼び出します。 各コンバーターのプロセスは複数回呼び出すことができ、ある程度の妥当な量のデータ(たとえば、1ユニット)を生成して終了する必要があることを理解することが重要です。 プロセスの実装に入力が必要になるとすぐに、 getFromBeltを呼び出してマネージャーに連絡します。
同じ加算器の例ですが、新しいパイプラインの概念を使用して実装されています。 現在、これは本格的なプログラムではなく、パイプラインマネージャーの実装がありません。
#include <iostream> #inlcude <belt.h> // std::cin class IntSource : public Belt::UniversalSource<int> { public: void process() { int data; if( std::cin>>data ) putOnBelt(data); } }; // std::cout class IntSink : public Belt::UniversalSink<int> { public: void process() { if(!hasData() ) return; std::cout<<getFromBelt()<<std::endl; } }; // class IntUniversal : public Belt::Universal<int,int> { public: void process() { int i1 = getFromBelt(); int i2 = getFromBelt(); if(!good() ) return; putOnBelt(i1+i2); } }; int main() { IntSource source; IntUniversal universal; IntSink sink; (source >> universal >> sink).process(); }
ここでは、前に言及しなかった関数とクラスが使用されます。
bool UniversalSink::hasData(void); bool UniversalSink::good(void); template<class T,class S> class UnboundedBelt : public Universal<T,S> {...}; template<class T> class RightBoundedBelt : public UniversalSink<T> {...}; template<class S> LeftBoundedBelt : public UniversalSource<S> {...}; class Belt : public UniversalBase {...}; template<class T, class R, class S> UnboundedBelt<T,S> operator >> (Universal<T,R>&,Universal<R,S>&); template<class R, class S> LeftBoundedBelt<S> operator >> (UniversalSource<R>&,Universal<R,S>&); template<class T, class R> RightBoundedBelt<T> operator >> (Universal<T,R>&,UniversalSink<R>&); template<class R> Belt operator >> (UniversalSource<R>&,UniversalSink<R>&);
データの終わりを決定する問題は、次のように解決できます:仮想関数bool UniversalSource :: hasData()が定義され、その実装はデフォルトでルールに基づいています-プロセスが反復として何も渡さなかった場合、データは終了したと考えられます。
パイプラインマネージャーの実装アプローチ
プロセス関数は、パイプラインマネージャーによって呼び出されます。 パイプラインマネージャーの異なる実装間の違いは、さまざまなコンバーターのプロセス関数が呼び出される順序にあります。 テープが過剰なデータを蓄積しないようにすることをお勧めします。これにより、メモリ消費量が増加します。また、コールスタックが深くなりすぎないようにすることをお勧めします。
getFromBelt関数は、テープからデータを読み取ります(テープにある場合)。そうでない場合、データの一部をテープに渡すまで、前のコンバーターからプロセスを開始します。 putOnBeltは、単にデータをテープに書き込みます。 次のコンバーターのプロセスを呼び出して、すぐにそれらを処理することができますが、これは必要ではなく、少し遅れて困難を生じます。
したがって、単純な場合の呼び出しスタックは次の形式を取ります。
- ...
- コンベアマネージャー
- UniversalSink :: getFromBelt()
- コンバーターn 2 ::プロセス()
- コンベアマネージャー
- UniversalSink :: getFromBelt()
- コンバーターn 1 ::プロセス()
- コンベアマネージャー
ほとんどの通常のアプリケーションの機能に必要なパイプラインの正常な動作を保証するには、1つの公理のみを実行する必要があります。
- パイプラインマネージャーには、同じコンバーターのプロセス関数が既に呼び出しスタックにある場合、コンバーターのプロセス関数を呼び出す権利がありません。 (A)
- パイプラインマネージャーには、左端のコンバーターのプロセス関数が呼び出しスタックにある場合、コンバーターのプロセス関数を呼び出す権利がありません。
以下に2つの可能なマネージャーの実装を示します。
- 再帰的 。 最後のコンバーターでのみ直接プロセスを呼び出し、残りは必要に応じて再帰的に開始されます。
- シーケンシャル 。 プロセスを順番に呼び出して(左から右へ)、テープにデータを「生成」します。 十分なデータがあると判断するとすぐに、右側の1つのコンバーターに進みます。 このオプションでは、プロセスの1回の反復で特定のコンバーターが消費するデータの量について推定することが望ましいです。
可能なパン
この記事では、パイプラインの実装の簡略図を提供します。 その改善は実装できます:
- 「先読み」操作:コンバーターはデータを読み取りますが、実際にはテープから削除されず、要求に応じて返されます。
- 「キャンディボックス」:バッチなどのデータ出力。大量の小さなデータ(シンボルなど)を扱うときの効率が向上します。 「ボックス」は、「1キャンディ」の送信ではなく、コンベアに沿ってすぐに送信されます。これにより、各データユニットの関数呼び出しが回避されます。
- 「スマート」メモリアロケータ(アロケータ)。これにより、パイプライン操作中の動的メモリの絶え間ない割り当て/削除を回避でき、不要なコピー操作からも節約できます。
- 複数のスレッドでの実行。 コンベアの場合、これは常に可能であり、各コンバーターがシングルスレッドの場合に効果的です。
また、「額装実装」と比較して、大きな利点は次のとおりです。プログラムの個々の部分が互いに独立していること(各コンバーターは入力データと出力データのタイプのみを知っており、入出力によって接続されているコンバーターについては何も知らない場合があります)、新しいコンバータをシームレスにオンにし、順序を変更する機能。
おわりに
私は謝ります:
- トピックを研究し、このトピックに関する用語を読んだり、用語や概念を恐れたりする。
- 識別子に英語の単語を使用した先例に恐れられている英語を知っている。
- 私とは異なるコーディングスタイルの多くの支持者(そして間違いなく、より正しい);
- C ++または多重継承の嫌い。
- 使用されるC ++コンストラクトに精通していないプログラマー。
これらの概念、そしておそらくもっと便利な概念が、Boostなどの人気のあるライブラリに実装されていることを認めます(もしそうなら、見るのは面白いでしょう)。 しかし、私にとっては、この記事の内容は美しいパターンであり、実用的な重要性だけでなく、共有したいものです。