少し前、私は顧客が保存したPDFマーケティングの傑作を、PNGなどのグラフィック形式の1つに変換したいプロジェクトに出会いました。 多くの説得と反論の後、プロジェクト予算により、安価な.NETコンポーネントを購入することができました。
顧客の要件に最も適したものを選択し、可能であれば、英語を話す、ライティングを適切にサポートするサービス(ヒンズータン半島ではない)を選択しました。
PDFコンバーターの要件
主な注意は、次のようなコンバータの機能に向けられました。
- フォントのカスタマイズを含む、APIのシンプルさ(埋め込みフォントに加えて、不足しているシステムフォントまたはそれにリンクを追加できるようにする必要があります)
- TIFF、PNG、JPEG、BMP形式にエクスポートする機能
- PDFドキュメント内の透明な画像のサポート
- カラーマスクのサポート
- アジアのフォントのサポート
- 注釈はドキュメントとともに変換する必要があります(このオプションを無効にする機能)
- さまざまなブレンドモード
- さまざまなタイルパターン
- さまざまな色空間RGB、CMYK、グレー、DeviceN
- Adobe Illustratorを使用して作成されたドキュメントの透明なグループ
いくつかのクエリの後、検索エンジンは適切な.NETコンポーネントのグループを返しました。
| ABCpdf | 6.1.1.5 |
| Adobe Acrobat(Interop.Acrobat) | Adobe Acrobat 10.0タイプライブラリ |
| Apitron.PDF.Rasterizer | 3.0.1.0 |
| O2S.Components.PDFRender4NET | 4.5.1.0 |
| PDFLibNET | |
| PDFSharp | 1.31.1789.0 |
| SautinSoft.PdfFocus | 2.2.2.2 |
| TallComponents.PDF.Rasterizer | 3.0.91.0 |
テスト開始
テスト目的で、単一ページのPDFファイル3BigPreview.pdfが選択されました(Adobeの公式Webサイトから取得)。 多数のグラフィック要素が含まれており、PDFグラフィックオブジェクトのコンポーネントとそのプロパティによる視覚化の可能性を示しています。
ABCPDF
プラットフォームをAnyCPUからx86に変更することによってのみ、64ビットマシンでこのライブラリの例を起動することはできませんでした。結果が得られました。 問題は、正しい画像解像度の設定で発生しました。 正しいサイズの612 x 792ピクセルの画像は、結果の画像の解像度を明示的に72 dpiに設定することによってのみ得られました。これは、他のコンポーネントが96dpi(Win7の場合)を設定するためです。 きんそくしょうりのキャラクターの正しい表示。 一部の文字は他の文字よりも明るく見えますが、これはアンチエイリアスの公平な使用法ではないことを示しています。 結果は、コードが100%使用されないことを気にしない人にとっては良いことですが、さらに先に進みます。
ABCpdfのコードの一部:
public static void ConvertPDFToImage(string pdfInputPath, string imageOutputPath, string imageName, ImageFormat imageFormat) { FileStream fs = new FileStream(pdfInputPath, FileMode.Open); Doc document = new Doc(); document.Read(fs); document.Rendering.DotsPerInch = 72; document.Rendering.DrawAnnotations = true; document.Rendering.AntiAliasImages = true; document.Rect.String = document.CropBox.String; document.Rendering.Save(Path.ChangeExtension(Path.Combine(imageOutputPath ,imageName), imageFormat.ToString())); }
結果:

Adobe Acrobat 10.0タイプライブラリ
ネイティブのAdobeライブラリがお気に入りから外れることはないことを理解するのは簡単です。 しかし、comオブジェクトへの呼び出し、これは取得したいものではありません。特に、これには製品のProバージョンをインストールする必要があるためです。
Adobe向けのコード:
public static void ConvertPDFToImage(string pdfInputPath, string imageOutputPath, string imageName, ImageFormat imageFormat) { CAcroPDDoc pdfDoc = (CAcroPDDoc) Interaction.CreateObject("AcroExch.PDDoc", ""); pdfDoc.Open(pdfInputPath); CAcroPDPage pdfPage = (CAcroPDPage) pdfDoc.AcquirePage(0); CAcroPoint pdfPoint = (CAcroPoint) pdfPage.GetSize(); CAcroRect pdfRect = (CAcroRect) Interaction.CreateObject("AcroExch.Rect", ""); pdfRect.Left = pdfRect.Top = 0; pdfRect.right = pdfPoint.x; pdfRect.bottom = pdfPoint.y; pdfPage.CopyToClipboard(pdfRect, 0, 0, 100); IDataObject clipboardData = Clipboard.GetDataObject(); if (clipboardData.GetDataPresent(DataFormats.Bitmap)) { using(Bitmap pdfBitmap = (Bitmap) clipboardData.GetData(DataFormats.Bitmap)) { pdfBitmap.Save(Path.ChangeExtension(Path.Combine(imageOutputPath, imageName), imageFormat.ToString()), imageFormat); } } pdfDoc.Close(); Marshal.ReleaseComObject(pdfPage); Marshal.ReleaseComObject(pdfRect); Marshal.ReleaseComObject(pdfDoc); Marshal.ReleaseComObject(pdfPoint); }
結果:
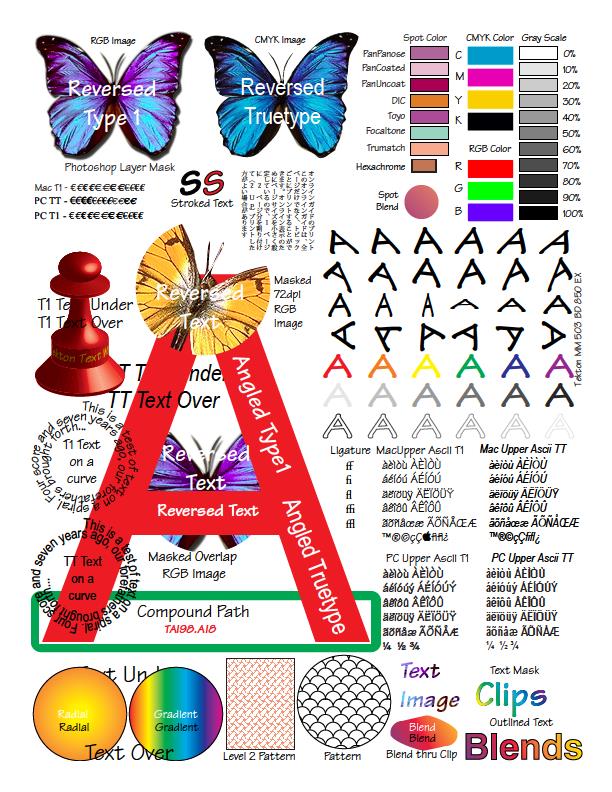
Apitron.PDF.Rasterizer for .NET
コンポーネントはテストでうまく機能しました。 便利なAPIにより、フォントをカスタマイズし、描画注釈を無効にすることができます。 画像が鮮明に見えます。 元のPDFドキュメントのすべての要素が描画されます。 ドキュメントを変換するときに、作業マシンの8つのコアすべてが関係していることに気付きました。おそらく、作業システムのRAMとプロセッサ数を増やしてアプリケーションのパフォーマンスを向上させたい人にとって便利です。
Apitronのコードの一部:
public static void ConvertPDFToImage(string pdfInputPath, string imageOutputPath, string imageName, ImageFormat imageFormat) { FileStream fs = new FileStream(pdfInputPath, FileMode.Open); Document doc = new Apitron.PDF.Rasterizer.Document(fs); RenderingSettings option = new RenderingSettings(); option.DrawAnotations = true; doc.Pages[0].Render((int) doc.Pages[0].Width, (int) doc.Pages[0].Height, option).Save(Path.ChangeExtension(Path.Combine(imageOutputPath, imageName), imageFormat.ToString()), imageFormat); }
結果:

O2S.Components.PDFRender4NET
ルーマニアのコンポーネントはテストを十分に完了しました。 すべてのドキュメント要素が正しく保存されるわけではありません。 結果のファイルからわかるように、すべての仕様要素がサポートされています。 テキストの描画には明らかな問題があります。
O2Sのコードの一部:
public static void ConvertPDFToImage(string pdfInputPath, string imageOutputPath, string imageName, ImageFormat imageFormat) { PDFFile pdfFile = O2S.Components.PDFRender4NET.PDFFile.Open(pdfInputPath); using (Bitmap pageImage = pdfFile.GetPageImage(0, 300)) { pageImage.Save(Path.ChangeExtension(Path.Combine(imageOutputPath, imageName), imageFormat.ToString()), imageFormat); } }
結果:

xPDFラッパーライブラリ(PDFLibNET)
テストケースの生成に失敗しました。 画像がぼやけて見え、テキストが判読できません。 テストファイルの変換時にエラーを受け取りました。
PDFLibNETのコードの一部:
public static void ConvertPDFToImage(string pdfInputPath, string imageOutputPath, string imageName, ImageFormat imageFormat) { PDFWrapper pdfWrapper = new PDFWrapper(); pdfWrapper.LoadPDF(pdfInputPath); pdfWrapper.ExportJpg(Path.ChangeExtension(Path.Combine(imageOutputPath, imageName), imageFormat.ToString()), 10); pdfWrapper.Dispose(); }
結果:

PDFSharp(GhostScriptおよびその他のラッパー)
PDFSharpは、有名なGhostScriptツールの他のラッパー(gouda、GhostscriptSharpなど)と同様に、常に予測どおりに機能するわけではありません。 数時間を費やした結果、写真しか抽出できず、ドキュメント全体を写真として保存できないことが判明しました。 新しい記事の良いアイデアとして注目します。
みんなのお気に入りのiTextSharpもここで確認できます。 便利なツールですが、私たちのタスクには適していません。
SautinSoftによるPdfFocus
私のレビューも国内の要素を捉えました。 しかし、残念ながら、彼はテストに対処できませんでした。
テストファイルで、彼はNREエラーを出しました。 しかし、他のファイルでは、彼は自分自身をうまく見せました。
(著者にとって:「格言、あなたは優れたソフトウェアを持っていると確信しています。この小さなことはすぐに修正されます。」)
SautinSoftのコードの一部:
public static void ConvertPDFToImage(string pdfInputPath, string imageOutputPath, string imageName, ImageFormat imageFormat) { PdfFocus pdfFocus = new PdfFocus(); pdfFocus.OpenPdf(pdfInputPath); pdfFocus.ImageOptions.Dpi = 96; pdfFocus.ImageOptions.ImageFormat = imageFormat; using (Image bitmap = pdfFocus.ToDrawingImage(1)) { bitmap.Save(Path.ChangeExtension(Path.Combine(imageOutputPath, imageName), imageFormat.ToString()), imageFormat); } pdfFocus.ClosePdf(); }
TallComponents.PDF.Rasterizer
オランダのコンポーネントは、テストで良い仕事をしました。 特定のAPIの複雑さは、基本的なグラフィックスの知識によって相殺されました。 テキストの描画にはわずかな問題があります。
TallComponentsのコードの一部:
public static void ConvertPDFToImage(string pdfInputPath, string imageOutputPath, string imageName, ImageFormat imageFormat) { FileStream fs = new FileStream(pdfInputPath, FileMode.Open); Document document = new Document(fs); Page page = document.Pages[0]; RenderSettings renderSettings = new RenderSettings(); renderSettings.GdiSettings.WorkAroundImageTransparencyPrintSize = true; using (Bitmap bitmap = new Bitmap((int) page.Width, (int) page.Height)) { using (Graphics graphics = Graphics.FromImage(bitmap)) { graphics.SmoothingMode = SmoothingMode.AntiAlias; graphics.CompositingQuality = CompositingQuality.HighQuality; graphics.Clear(Color.White); page.Draw(graphics, renderSettings); } bitmap.Save(Path.ChangeExtension(Path.Combine(imageOutputPath, imageName), imageFormat.ToString()), imageFormat); } }
結果:
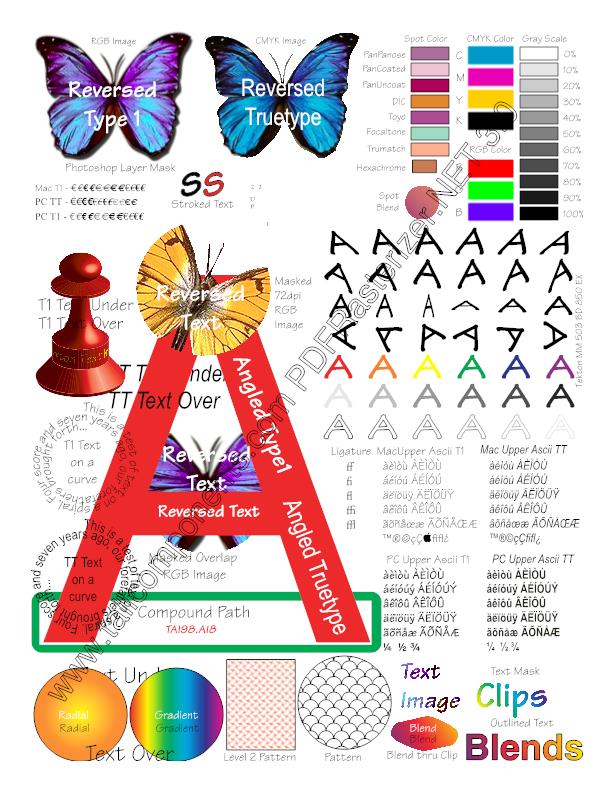
まとめ
PDFドキュメントをBMP、JPEG、TIFF画像に保存するのは簡単な作業ではありません。 多くのソフトウェアユーティリティ、ライブラリ、商用サービス、およびそれらに相当するシェアウェアを見つけることができますが、小規模なスタートアップでは、サードパーティの開発者からの信頼できるコンポーネントなしではできません。 結果を分析し、サイトのドキュメント、コード例、価格を読み直した後、プロジェクトのコンポーネントを選択しました。 パフォーマンスの点では、すべてのライブラリは同じレベルにあります。これは、おそらくPDFドキュメントを単一のストリームに読み込むための仕様によるものです。 選択する際、モバイルデバイスで製品を使用する可能性を考慮しませんでした。GDI+制限によるすべてのコンポーネントがAndroidプラットフォームで正常に機能しないか、Mono.Xamarinと互換性がないためです。