ボクセルグラフィックスの紹介
GameDev Webサイトで衝突計算アルゴリズムを検索する過程で、 idTech 6エンジンに関する小さな記事に出会い 、ボクセルグラフィックスに興味を持ちました。これは、ほぼすべてのコンピューターグラフィックスのベースとなっているポリゴングラフィックスとは対照的です。
一般に、ボクセルは「体積ピクセル」の略ですが、現在ではボクセルは基本的にプリミティブであり、ほとんどの場合、特定のサイズと色を持つ立方体または長方形の箱を意味します。 idTech 6およびKen Silverman Voxlapエンジンでは、それらはスパースボクセルオクツリー(SVO)に格納されます。これにより、メモリが節約され、「詳細レベル」の実装が容易になります。

言い換えれば、ボクセルはそのようなLEGOコンストラクターであり、異なるサイズの同じパーツから(小さなディテールを大きなディテールに接続するだけでなく)多種多様なモデル、フィギュアなどを実装できます。
ポリゴンに関するボクセルの最大の利点の1つは、それらを破壊できることです。プログラムは、ボクセルが部分的に破壊されると、親と同じマテリアルからなる小さなボクセルに分割できることを確実に知っています。



最初の試み
私は一度に3次元空間に突入することを敢えてしませんでした-学ばなければならなかった数式の全リスト(後で説明します)が恐ろしく見えたので、プラットフォーマーが「ボックス」を使用するようにコードを書き直すことにしました-正方形であり、したがって、スパースに保存されませんでした八分木、まばらな四分木。
最初のコードはひどいものでした-削除、ツリーのトラバース、ノードの作成など、ツリーを操作するすべての機能は、QuadTreeクラスとは別の反復機能でした。 他の問題では、クラスにそれらを追加しても実際には役割を果たしませんでした。なぜなら、この場合、再帰関数が大いに役立つことが後に判明したからです。 これらの最初の試みが有用になった唯一のことは、私が必要とする機能の明確な声明と、C ++ツリーの実装の基本でした。これは後で大いに役立ちました。 そしてもちろん、OpenGLを研究するきっかけとなった最初の試みでした(Direct2Dは以前に誘惑されていましたが、すぐに失望しました)。
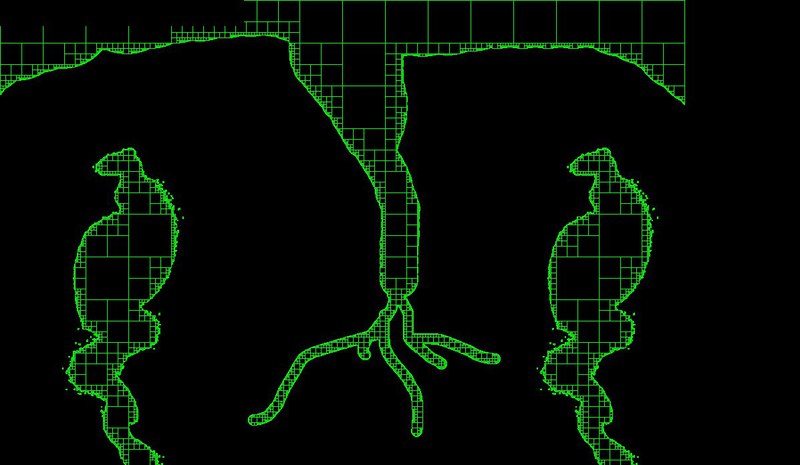


ボリュームへの移行
私はNeHe gamedevで OpenGLを研究し始め、どういうわけかすぐに3次元空間に入り、Quakeのようなゲームのエンジンを計画し始めました。 四分木は八分木に書き直され、最初の困難が始まりました。 オクトツリーはより多くのメモリを消費し、すべての基本機能が再帰的になったとしても、時間とメモリを使いすぎています。 この問題を解決するために、次の方法が実装されました。
メモリ最適化
octreeでは、動的メモリ(ヒープ)内のポインターにスペースを割り当てるnew / delete演算子を使用することが非常に頻繁に必要です。 動的メモリは静的(スタック)よりも遅く、新しい/削除機能自体は私にとって遅すぎました。 このため、独自のMemoryPoolクラスとmem_pool_treeテンプレートが作成されました。
mem_pool_treeは、T。Cormanの本「Algorithms。Building and Analysis」で出会ったBSTツリーの影響を受けて作成されたもので、メモリでは直接機能せず、数値のみで動作します。静的メモリ領域。 削除を予測することはできませんでしたが、「正しい」メモリを選択するのは現実的でした。そのため、アイデアを取り入れてBSTツリーから「blockiness」を追加しました。さらに2つの変数-占有スペースの開始と終了。 占有スペースの中央でピースを削除しようとすると、ノードが分割されます。ピースを選択するための関数が呼び出されると、アルゴリズムは、スペースの割り当てにより隣接ブロックとマージできるようなブロックを検索します。 そして、バランス関数が定期的に呼び出されます。
マルチスレッド
親ノードには8つの子ノードの配列へのポインターがあるツリー構造のため、完全なツリーウォークを必要とする関数(ツリー全体の削除、冗長な要素の削除、平均ボクセルの計算など)マルチスレッドを有効にする機能を使用して書かれています。 マルチスレッドはOpenMPを使用して実装されました。 たとえば、ツリーを最適化する必要があります(たとえば、8つの子ノードを保存する理由、それらの色を親ノードに転送して削除できる場合)。 私たちは実現します:
class Octree { class Node { Node * son; void Optimize(); }; void Optimize() { #pragma omp parallel { #pragma omp for for(int n = 0; n<8; ++n) { son[n].Optimize(); } } } };
子ノードは相互接続されていないため、このような操作にはミューテックスは必要ありません。これは、最小限のメモリコストが必要な場合に非常に適しています。
ボクセルのロードと保存
長い間、ボクセルをファイルに保存する最適な方法を探す必要がありました。RAMが貴重な状況では、RAMに余分なボクセルを保存することは受け入れがたい贅沢だからです。 多くの検索を行った結果、SQLite3が選択されました。これには、キャッシュがあり、「詳細レベル」の値に基づいて必要なボクセルのみをダウンロードする機能があります。 SQLite3データベースでの最速の作業は、プロジェクトにsqlite3ソースコードを埋め込み、自己コンパイルするときに判明しました(正確な数値は覚えていませんが、200〜250ミリ秒で50万個の変数、Intel Atomを搭載したネットブック)。 当然、SQLite3は「トランザクションの開始;」、「トランザクションのコミット;」、「PRAGMA journal_mode = MEMORY;」、「PRAGMA同期= OFF;」を高速化するために使用されていました。 など
スクリーンショット
実際、実装段階にあるコードの説明がさらに進むにつれて、ここに小さなスクリーンショットを示します。 もちろん、スクリーンショットのオブジェクトは非常にシンプルですが、これの唯一の理由は、通常の複雑なモデルを描画したり、既存のモデルを変換するために手が届かないことです。 さらに、これらは最初のスクリーンショットであり、ラスタライズのために、OpenGLではなくGDIを使用して小さなコードが記述され、レイトレーシングは、回転行列計算およびその他の計算がCPUで実行される最も一般的なサイクルで実行されました。






現在の課題と結論
多型
これで、オクトツリーはポリモーフィズムを使用して再び書き換えられます。 主なタスクは、ツリーを純粋な八分木ではなく、 kdツリー (ボクセルが8つの小さなボクセルに分割されていないが、特定の割合と特定の軸を持つ2つのボクセルに分割されているツリー)とのクロス、およびその他の修正です。
レイキャスティング
octreeツリーにより、 レイキャスティング 、「キャスティングレイ」アルゴリズムが可能になり、これを使用してラスタライザを作成します。 また、アルゴリズムの実装は、OpenGL(配列からのテクスチャ生成とポリゴン上のその表示)、「グループトレース」、およびC ++ AMPによって使用されます。 一般に、このトピックはray-tracing.ruでよく公開されています 。
おわりに
一般的に、このトピックは興味深いものであり、多くの興味深いものを見つけることができます。 例: アトモンタージュエンジンとSIGGRAPH 2012 でのSVOテクノロジーのプレゼンテーションに関するハブに関する記事。
UPD
静的メモリ内の配列を使用して記述したメモリ割り当てクラスは、測定後に次のデータを生成しました。
- 各100バイトの2,000万個のオブジェクトの削除(合計で220 MB以上かかりました)には2〜3秒かかりました(もちろん、オブジェクトはランダムに削除されました)
- メモリの割り当てを測定するのに長い時間を費やしましたが、最後の結果は4〜5秒で8バイトの5000万オブジェクトでした
- スタックのメモリはヒープのメモリよりも速いため、読み取りは高速になりますが、これまでのところ、平均的な速度の差を見つけるために異なるハードウェアでテストしています
- 5000万オブジェクトのダイナミックメモリから通常のnew演算子を使用してメモリを割り当てようとすると、プログラムは例外std :: bad_allocをスローし、try-catchを処理してそれらを処理すると、プログラムがメモリをロードして、コンピューターで実行中のほぼすべてのアプリケーションがクラッシュしました。