このような自発的なウィッシュリスト(特に時間がある場合)には多くのオプションがあり、本質的にセマンティックの負荷をもたらさない一連の装飾からすべてがありますが、それだけです。
このミニ記事では、これらの「ウィッシュリスト」の1つを検討します。
TListViewに要素のリストが表示されていると仮定して、それをソートしてそのような結果を得ようとします。
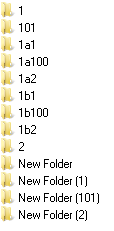
美しくない、なぜ「101」という名前のこの2番目の要素が適切でないのですか? 結局のところ、これは数字であるため、少なくとも「2」という名前の要素の後には彼にとっての場所になるはずです。 はい、「新しいフォルダー(101)」は明らかに「新しいフォルダー(2)」の後にあるはずです。 結局のところ、エクスプローラーではすべてが正常に見えます。

この振る舞いの理由を理解し、人間の観点からより正確なソートのアルゴリズムを実装してみましょう。
最初に、間違ったソートの理由を見てみましょう。
デフォルトでは、TListViewはlstrcmp関数を使用して文字列を比較し、文字列を文字ごとに比較します。
たとえば、2つの行「1」と「2」を使用する場合、最初の行は2番目の行の上に配置する必要があります。 ユニット記号はデュースの前にあります。 ただし、最初の行の代わりに「101」を使用すると、lstrcmp関数は、この行が最初に移動することを示します。この場合、両方の行が数字の文字列表現であるという事実を考慮せずに、両方の行の最初の文字を比較した結果を決定するためです。
もう少し複雑にして、lstrcmpが再び間違った結果を与える「1a2」と「1a101」の行を取り、2行目が最初になるようにします。 彼女は、この場合は数字の文字列表現でもあるにもかかわらず、両方の文字列の3番目の文字を比較した結果に基づいてこの決定を行います。
私たちはその理由を突き止めました。今、解決策を考えています。
lstrcmpは数字の一部をシンボルの形で解釈して比較に誤りがあるため、それに類似した比較アルゴリズムを実装する必要があります。
アルゴリズム的には、これは非常に簡単です。
繰り返しますが、「1a2」と「1a101」を取ります。 それらを別々のコンポーネントに分割し、文字と数字を分離します。 最初の行を「1 + a + 2」の形式で表し、2行目を「1 + a + 101」の形式で表す場合、3回の比較を実行するだけで済みます。
1.数字と数字
2.シンボルとシンボル
3.再び番号と番号
このような比較の結果は正確であり、lstrcmpがこのことを知らせてくれたので、2行目は実際には1行目ではなく2行目になるはずです。
ここで、TKからこのアルゴリズムの実装を考えます。
それは明らかです:
1.比較のために渡された行の1つが空の場合-最初の行より上に移動する必要があります。
2.両方の行が空の場合、それらは同一です。
3.行の大文字小文字は、比較する際に考慮されません。
4.行を分析するには、各行の現在解析されている文字のアドレスを含むカーソルを使用します。
5.いずれかの行のカーソルに数字が含まれ、他の行のカーソルに文字が含まれている場合、最初の行は2番目の行よりも高くなります。
6.行カーソルが文字を指す場合-比較はlstrcmpに似ています
7.ラインカーソルが数値を指している場合は、両方の数値を抽出して互いに比較します。
7.1両方の数値がゼロ(たとえば、「00」と「0000」)の場合、ゼロの少ない数値が配置されます。
8.分析中にいずれかの行のカーソルが終端のゼロを見つけた場合-この行は上になります。
8.1同時に2番目の行のカーソルも終端のゼロにある場合-行は同一です。
アルゴリズムを実装するには、このTKで十分です。
実際に実装します:
// // CompareStringOrdinal , .. // " (3)" < " (103)" // // // -1 - // 0 - // 1 - // ============================================================================= function CompareStringOrdinal(const S1, S2: string): Integer; // CharInSet Delphi 2009, // function CharInSet(AChar: Char; ASet: TSysCharSet): Boolean; begin Result := AChar in ASet; end; var S1IsInt, S2IsInt: Boolean; S1Cursor, S2Cursor: PChar; S1Int, S2Int, Counter, S1IntCount, S2IntCount: Integer; SingleByte: Byte; begin // if S1 = '' then if S2 = '' then begin Result := 0; Exit; end else begin Result := -1; Exit; end; if S2 = '' then begin Result := 1; Exit; end; S1Cursor := @AnsiLowerCase(S1)[1]; S2Cursor := @AnsiLowerCase(S2)[1]; while True do begin // if S1Cursor^ = #0 then if S2Cursor^ = #0 then begin Result := 0; Exit; end else begin Result := -1; Exit; end; // if S2Cursor^ = #0 then begin Result := 1; Exit; end; // S1IsInt := CharInSet(S1Cursor^, ['0'..'9']); S2IsInt := CharInSet(S2Cursor^, ['0'..'9']); if S1IsInt and not S2IsInt then begin Result := -1; Exit; end; if not S1IsInt and S2IsInt then begin Result := 1; Exit; end; // if not (S1IsInt and S2IsInt) then begin if S1Cursor^ = S2Cursor^ then begin Inc(S1Cursor); Inc(S2Cursor); Continue; end; if S1Cursor^ < S2Cursor^ then begin Result := -1; Exit; end else begin Result := 1; Exit; end; end; // S1Int := 0; Counter := 1; S1IntCount := 0; repeat Inc(S1IntCount); SingleByte := Byte(S1Cursor^) - Byte('0'); S1Int := S1Int * Counter + SingleByte; Inc(S1Cursor); Counter := 10; until not CharInSet(S1Cursor^, ['0'..'9']); S2Int := 0; Counter := 1; S2IntCount := 0; repeat SingleByte := Byte(S2Cursor^) - Byte('0'); Inc(S2IntCount); S2Int := S2Int * Counter + SingleByte; Inc(S2Cursor); Counter := 10; until not CharInSet(S2Cursor^, ['0'..'9']); if S1Int = S2Int then begin if S1Int = 0 then begin if S1IntCount < S2IntCount then begin Result := -1; Exit; end; if S1IntCount > S2IntCount then begin Result := 1; Exit; end; end; Continue; end; if S1Int < S2Int then begin Result := -1; Exit; end else begin Result := 1; Exit; end; end; end;
このアルゴリズムの結果を見ます。
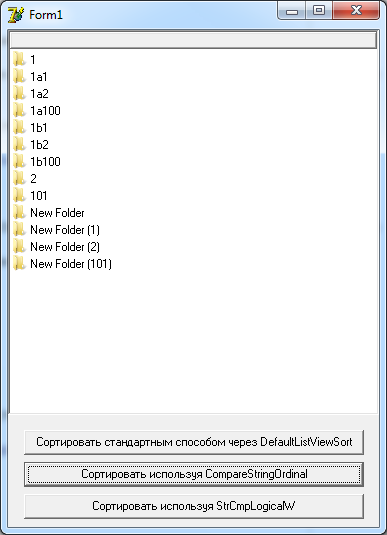
実際、予想どおり。
次の「デコレーター」の準備ができました。
確かにこれは自転車であり、StrCmpLogicalWを使用する必要があると言うことができます。
msdn.microsoft.com/en-us/library/windows/desktop/bb759947
さて、試してみてください-3番目のボタンはそのようなソートを担当します。
ソート後、リストの最初の5つの要素に注意してください。
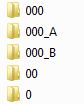
それらは導体が表示するものに似ていますが、完全に真実ではありません。 さて、「0」という名前の要素は、「00」などの要素の下に配置しないでください。
デモのソースコードは、 このリンクから取得できます。