
数週間前、私はこの記事でShazamの仕組みを知りました
Shazamのようなプログラムがどのように機能するのか疑問に思った...さらに重要なことは、Javaで似たようなものを書くのはどれほど難しいかということです。
Shazamについて
誰かが知らない場合、Shazamは音楽を分析/選択できるアプリケーションです。 スマートフォンにインストールして、マイクを音楽ソースに20〜30秒間保持すると、アプリケーションはどのような種類の歌なのかを判断します。
最初の使用では、魔法のような感覚がありました。 「どうしてこれをやったの!?」そして今日でも、何度も使ったとき、この気持ちは私を去りません。
同じ気持ちを引き起こすような何かを自分で書くことができたらクールではないでしょうか? それが先週末の私の目標でした。
注意深く聞いてください..!
まず、分析のために音楽のサンプルを取得する前に、Javaアプリケーションを介してマイクを聴く必要があります...! これは当時Javaで実装する必要がなかったものなので、それがどれほど難しいかさえ想像できませんでした。
しかし、それは非常に簡単であることが判明しました。

これで、通常のInputStreamストリームからのようにTargetDataLineからデータを読み取ることができます。

この方法により、マイクを開いてすべての音を簡単に録音できます! この場合、次のAudioFormatを使用します。

それで、ByteArrayOutputStreamクラスに記録されたデータができました。 第1段階が完了しました。
マイクデータ
次のテストはデータ解析です。出力では、受信したデータはバイト配列の形式で、次のような長い数字のリストでした。

うーん...はい。 それは音ですか?
データを視覚化できるかどうかを確認するために、Open Officeにドロップして折れ線グラフに変換しました。

はい! 今では「音」のように聞こえます。 たとえば、Windowsサウンドレコーダーを使用しているように見えます。
このタイプのデータは時間領域として知られています 。 しかし、この段階では、これらの数値は役に立たない... Shazamの仕組みに関する上記の記事を読むと、連続時間領域データの代わりにスペクトル分析 (スペクトル分析)を使用していることがわかります。
したがって、次の重要な質問は、「データをスペクトル分析形式に変換するにはどうすればよいか」です。
離散フーリエ変換
データを適切なものに変換するには、いわゆる離散フーリエ変換 (離散フーリエ変換)を適用する必要があります。 これにより、時間領域のデータを周波数間隔に変換できます。
ただし、これは1つの問題にすぎません。データを周波数間隔に変換すると、一時データに関するすべての情報が失われます。 したがって、各振動の大きさはわかりますが、いつ発生するかについては少しでもわかりません。
この問題を解決するには、スライディングウィンドウプロトコルを使用します。 データの一部(私の場合は4096バイトのデータ)を取得し、このビットの情報のみを変換します。 その後、これらの4096バイトの間に発生するすべての変動の大きさがわかります。
申込み
フーリエ変換について考える代わりに、私は少しグーグルで検索して、いわゆるFFT(高速フーリエ変換)のコードを見つけました。 私はこのコードを呼び出します-データパケットを含むコード:

これで、すべてのデータのパックを含む2つの行(Complex [])ができました。 これらのシリーズには、すべての周波数のデータが含まれています。 このデータを視覚化するために、フルスペクトルアナライザーを使用することにしました(計算が正しいことを確認してください)。
データを表示するために、それらをまとめます。

入力、Aphex Twin
これは少し外れたトピックですが、エレクトリックミュージシャンのAphex Twin(Richard David James)についてお話ししたいと思います。 彼はクレイジーな電子音楽を書きました...しかし、彼の歌のいくつかは興味深い特徴を持っています。 たとえば、彼の最大のヒットはWindowlickerで 、これには画像(スペクトログラム)が含まれています。
曲をスペクトル画像として見ると、美しいらせんが見えます。 別の曲、数学方程式は、ツインの顔を示しています! 詳細はこちら-Bastwood-Aphex Twinの顔 。
この曲をスペクトルアナライザーで実行すると、次の結果が得られました。
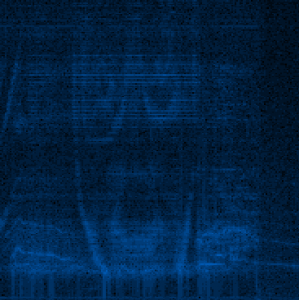
もちろん完璧ではありませんが、それはツインの顔でなければなりません!
主要な音楽ポイントを特定する
Shazamアプリケーションアルゴリズムの次のステップは、曲のいくつかのキーポイントを特定し、それらをキャラクターとして保存し、800万を超える曲データベースから適切な曲を見つけることです。 これは非常に迅速に行われ、記号の検索は-O(1)の速度で行われます。 シャザムがこれほど優れた機能を発揮する理由が明らかになりました!
1週末後にすべてが機能するようにしたかったので(残念なことに、これは1つのことに集中するための最大期間であり、新しいプロジェクトを見つける必要があります)、アルゴリズムをできるだけ単純化するようにしました。 そして、驚いたことに、うまくいきました。
スペクトル分析の各ラインについて、特定の範囲で、最大の大きさのポイントを選択しました。 私の場合:40-80、80-120、120-180、180-300。
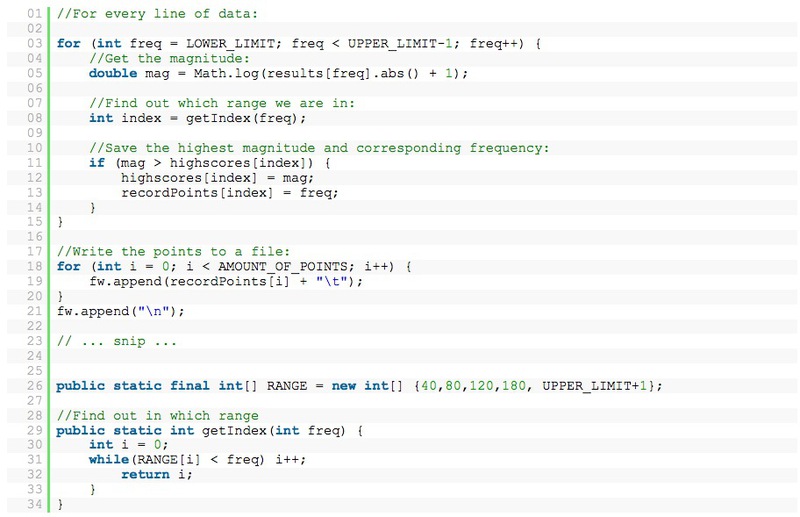
歌を録音すると、次のような数字のリストが表示されます。

歌を録音して視覚化すると、次のようになります。

(すべての赤い点は「キーポイント」です)
自分の音楽のインデックス作成
動作するアルゴリズムを手に入れて、3000曲すべてのインデックスを作成することにしました。 マイクの代わりに、mp3ファイルを開いて目的の形式に変換し、AudioInputStreamを使用してマイクを使用する場合と同じ方法でそれらを読み取ることができます。 ステレオ録音をモノモードに変換することは、思ったよりも複雑であることがわかりました。 例はインターネットで見つけることができます(ここに投稿するにはもう少しエンコードが必要です)。例を少し変更する必要があります。
選択プロセス
アプリケーションの最も重要な部分は、選択プロセスです。 Shazamのマニュアルから、彼らがサインを使ってマッチを見つけてから、どの曲が最適かを判断することは明らかです。
複雑なポイントの時間グループを使用する代わりに、データの行(たとえば、33、47、94、137)を1文字として決定しました:1370944733
(テスト中、3または4ポイントが最良の選択肢です。微調整するのはより困難です。毎回mp3のインデックスを再作成する必要があります!)
1行に4ポイントを使用した文字エンコードの例:

次に、2つのデータ配列を作成します。
-曲のリスト、リスト(リストインデックスはSong-ID、文字列はsongname)
-データ記号のベース:マップ<ロング、リスト>
文字データベース内の長い文字自体は、DataPointsセグメントを含みます。
DataPointsは次のとおりです。

これで、検索を開始するために必要なものがすべて揃いました。 最初は、すべての曲を読み、各データポイントのサインを生成しました。 これはキャラクターデータベースに保存されます。
2番目のステップは、特定したい曲のデータを読み取ることです。 これらの文字が取得され、データベースで一致が検索されます。
これは1つの問題にすぎません。各キャラクターにはいくつかのヒットがありますが、どの曲が同じであるかをどのように判断しますか? マッチの数で? いいえ、うまくいきません...
最も重要なことは時間です。 時間をかけなければならない...! しかし、歌のどの部分にいるのかわからない場合、どうすればよいでしょうか? 同じ成功を収めて、曲の最後のコードを録音することができました。
データを調べてみると、次のデータがあるため、面白いことがわかりました。
-記録マーク
-可能性のあるオプションの兆候の一致
-可能性のあるオプションの曲ID
-私たち自身の記録のタイムストリーム
-可能性のあるオプションの時間標識
これで、レコードの現在の時間(たとえば、行34)にサインの時間(たとえば、行1352)をサインインできます。 この違いは、曲IDとともに保存されます。 この対照、この違いは、私たちが歌のどこにいることができるかを教えてくれます。
レコードのすべてのサインを終えると、たくさんの曲のIDとコントラストが残ります。 秘Theは、選択したコントラストの付いた標識がたくさんある場合、曲を見つけたことです。
まとめ
たとえば、最初の20秒間、The Kooks-Match Boxをリッスンすると、アプリケーションで次のデータが取得されます。

動作します!!!
20秒を聞いた後、私が持っているほぼすべての曲を識別できます。 そして、エディターのこのライブ録音でさえ、40秒のリスニング後に決定できます!
そして再び、この魔法の感覚!
現時点では、コードは完全とは見なされず、完全に機能しません。 私はある週末にそれを盲目にしました。それは理論の証明/アルゴリズムの学習のようなものです。
おそらく十分な数の人々がこれについて尋ねるなら、私はそれを思い浮かべてどこかにそれをレイアウトします。
追加
Shazamの特許弁護士は、コードの発行を停止してこのトピックを削除するように求めるメールを私に送信します 。詳細については、 こちらをお読みください 。
翻訳者から
小さな発表:2013年の夏、Yandexは、スタートアップの作成と立ち上げの方法を学びたい人向けの実験的なワークショップであるトルストイサマーキャンプを開きます。 2か月のコースの一環として、Yandexは参加者が価値のあるチームを編成し、概念を正しく策定し、適切な専門家からフィードバックを得て、プロトタイププロジェクトを開発するのを支援します。 さまざまなセミナーやワークショップにより、必要なスキルを身に付けることができます。 また、スタートアップトピックに関する興味深い翻訳記事を定期的に発行します。 何かおもしろいものに出会ったら、個人的なものを入れてください! Kst、Yandexが音楽を認識する方法を学んだハブに関する記事 。
申し込み(残り2日間!!) また、 habrの発表でも。 リーン方式、顧客開発、MVPについて説明します。 一緒に来て!