Hi%habra_user%!
Flexコンパイラに関する一連の記事を続けて、アプリケーションのアセンブリ中にコンパイラ内でどのようなプロセスが発生するかについて、この作成者による優れた記事を翻訳することにしました。 2008年にさかのぼりますが、ロシア語圏のコミュニティ(特に他のコミュニティ)では見られませんでした。 そして、近い将来、大部分のFlashプロジェクトのアセンブリに関連するのはこのコンパイラーであるため、その拡張に関する一連の記事を続けることにしました。
いつものように、この行を読むことにうんざりしていない人はみんな-カットをお願いします!
第一に、私はこのサイクルの他の記事へのリンクを提供することが適切だと考えています。
- コンストラクターパラメーターをMXML Flexコンパイラーに追加する
- MXMLコンパイラ。 パート2.非文字列パラメーター初期化子
- MXMLコンパイラ。 パート3. Flexコンパイラーを理解する
第二に、ブランチコード4.6への実際のリンク(FlexからApacheへの転送に関連する)を見つけるためにかなりグーグルで検索する必要がありまし
opensource.adobe.com/svn//opensource/flex/sdk/branches/4.y
なぜこの特定のバージョンを使用しているのですか?
答えはビルドプロセスにあります。ソースをダウンロードしてantを実行するだけでAdobeのバージョンをそのまま使用できる場合は、Apacheバージョンでは依存関係のためにかなり一生懸命コンパイルする必要があります。 そして、それらの違いはまだ最小限です(どちらもアセンブリ用のMavenをサポートしていません:))
私は(元の記事の著者のように)記事をよりよく理解するためにソースをダウンロードすることを強くお勧めします。 この記事の内容は、両方の(ApacheおよびAdobe)バージョンのコンパイラーに関連しています。
言語コンパイラ
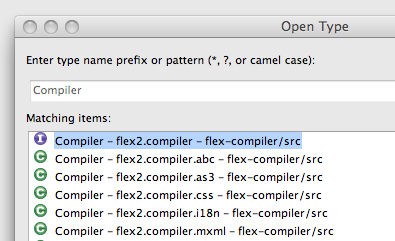
一般に、Flexコンパイラはさまざまなプログラミング言語をサポートしています。 これらは、言語固有のコンパイラのセットによってコンパイルされます。 コンパイラと呼ばれるプロジェクトクラスのリストを見ると、それらのいくつかを見ることができます。
ただし、すべての言語を1つのステップでコンパイルできると主張することはできません。 たとえば、MXMLコンパイラはAS3で記述された依存関係を使用する場合があります。 したがって、MXMLコンポーネントをバイトコードにコンパイルする前に、コンパイラは必要なAS3クラスを判別し、MXMLから呼び出されたAS3コードが正しいことを確認する必要があります。
また、異なるコンパイラが異なるステップ数を必要とすると仮定することは合理的です。 たとえば、MXMLコンパイラには、AS3の2倍の手順が必要です。
flex2.compiler.SubCompiler
Flexでは、すべての言語コンパイラーが同じインターフェイスflex2.compiler.SubCompilerを実装します。
public interface SubCompiler { String getName(); boolean isSupported(String mimeType); String[] getSupportedMimeTypes(); Source preprocess(Source source); CompilationUnit parse1(Source source, SymbolTable symbolTable); void parse2(CompilationUnit unit, SymbolTable symbolTable); void analyze1(CompilationUnit unit, SymbolTable symbolTable); void analyze2(CompilationUnit unit, SymbolTable symbolTable); void analyze3(CompilationUnit unit, SymbolTable symbolTable); void analyze4(CompilationUnit unit, SymbolTable symbolTable); void generate(CompilationUnit unit, SymbolTable symbolTable); void postprocess(CompilationUnit unit, SymbolTable symbolTable); void initBenchmarks(); PerformanceData[] getBenchmarks(); PerformanceData[] getEmbeddedBenchmarks(); void logBenchmarks(Logger logger); }
コンパイルプロセスに関係のないメソッドの中で、以下を区別できます。
String getName() -名前が示すように、メソッドはコンパイラーの名前を返します。
isSupportedおよびgetSupportedMimeTypes-このコンパイラーがリバースできるファイルのタイプを決定するために使用されます。
コンパイルパフォーマンスの測定に関連するベンチマークメソッド。
コンパイル手順
お気づきかもしれませんが、コンパイルプロセスは9つのステージで構成されています。 メインのFlexコンパイラはコーディネーターとして機能し、次のようなものを期待するコンパイラのインスタンスを呼び出す役割を果たします。
- 前処理(1回)
- parse1(1回)
- parse2(1回)
- analyze1(1回)
- analyze2(1回)
- analyze3(1回)
- analyze4(1回)
- 生成(1回)
- 後処理(インスタンスの停止が必要になるまで繰り返し)
これらのメソッドの呼び出しに加えて、メインのFlexコンパイラはいくつかのことを行います。
- ソースファイルのタイプに基づいて適切なコンパイラインスタンスを選択します。
- インスタンスから許可されていないタイプのリストを受け取り、プロジェクトのソースとライブラリの中からそれらを探します。
- 型情報をインスタンスに渡します。
- インスタンスの状態とリソースの一般的な状態に基づいて、実行するコンパイラを決定します。
すべてを管理するために、メインコンパイラはインスタンスを連携させます。 基本的に、特定のルールセットに従う必要があります。
- 構文ツリーは 、 parse2の終わりまでにアクセスできる必要があります。
- analyze1には、スーパークラスの名前に関する情報が必要です。
- analyze2は、すべての依存関係について知る必要があります。
- analyze4は完全な型情報を提供する必要があります。
コンパイルプロセスは次の時点まで続きます。
- 解決する依存関係はありません。
- コンパイラインスタンスはエラーをスローします。
呼び出しアルゴリズム
前述のように、コンパイルプロセスはこれらの9つのメソッドの呼び出しで構成されます。 しかし、これらのメソッドの呼び出し順序は非常に正確に決定されているという事実にもかかわらず、メインコンパイラは依然としてさまざまな方法でそれらを呼び出すことができます。 実際、2つのアルゴリズムがあります。1つ( flex2.compiler.API.batch1() )構造化されたアルゴリズム、もう1つ( flex2.compiler.API.batch2() )条件付き病原性。 それらを別々に考えてみましょう:
API.batch1()は、保守的でより構造化されたアルゴリズムです。 その本質は、別のフェーズに進む前に、各ファイルの1つのフェーズの開始を保証することです。 たとえば、 analyze2()に進む前に、すべてのファイルに対してanalyze1()が呼び出されます。
API.batch2()は条件付き病原性アルゴリズムであり、その主な目標はメモリ消費を最小限にすることです。 API.batch1()とは異なり、依存関係の少ないソースファイルは、依存関係の多いファイルがanalyze3()フェーズに到達するよりもはるかに早く生成ステップに到達できます。 アイデアは、ファイルがバイトコードにコンパイルされると、ファイルに割り当てられたリソースをすぐに解放できるということです。
おわりに
さて、これでFlexコンパイラの内部動作についてもっとよく知ることができました! 要約しましょう:
- メインのFlexコンパイラは、2つのアルゴリズムのうち、batch1またはbatch2のいずれかのみを使用してコンパイルします。
- コンパイルアルゴリズムは、2つの異なる戦略を使用して、アプリケーションを構築する9つの段階を呼び出します。
- コンパイル中、コンパイラーのインスタンスは協力し、各段階の最後にメインコンパイラーに型情報を提供する必要があります。
- メインコンパイラは、すべての汚い作業(ソースファイル/ライブラリの検索、エラーロギングの管理など)を実行します。つまり、言語コンパイラはこれを心配する必要がありません。
上記は、Flexフレームワークに含まれるユーティリティのすべてのバージョン(mxmlc、compc、asdoc)に関連しています。
翻訳者から:
半透明のコメントが増えないように、見つかった文法上の誤りや不正確な点を個人的なメッセージで送信してください。
PS一般に、アイデアは元々Flex Compiler Extensionに関する記事を書くことでした。これにより、コードを変更せずにコンパイラを拡張できます(jarとしてflex-config.xmlを介して接続します)が、考え直した後、最初に全体を説明するこの記事を作成することにしましたインとアウト。
PSS ASC2.0の開発のペースを考えると、Flexコンパイラは少なくともあと1年、またはそれ以上に関連すると信じています。特にこれは貴重な体験であるため、それを勉強して選ぶことを恐れないでください。
PSSSはい、はい、死んでいます。 はい、アドビはプレーヤーを放棄しました。 はい、彼らはApacheを与えました。 何とか何とか...