 多くの人が素晴らしく恐ろしい高速フーリエ変換(FFT / FFT)を聞いたことがありますが、 JPEG / MPEG圧縮と音の周波数分解(イコライザーなど)以外の実際的な問題を解決するためにどのように使用できるかは、しばしば不明な問題のままです。 。
多くの人が素晴らしく恐ろしい高速フーリエ変換(FFT / FFT)を聞いたことがありますが、 JPEG / MPEG圧縮と音の周波数分解(イコライザーなど)以外の実際的な問題を解決するためにどのように使用できるかは、しばしば不明な問題のままです。 。
最近、高速フーリエ変換を使用するConwayのLifeゲームの興味深い実装に出会いました。非常に予期しない場所でこのアルゴリズムの適用性を理解するのに役立つことを願っています。
ルール
古典的な「生命」のルールを思い出してみましょう-正方形のセルがある正方形では、隣接するセルが3個以上または2個未満の場合、生きているセルは死にます。 したがって、アルゴリズムを効果的に実装するには、セルの周囲の近隣の数を迅速にカウントする必要があります。これにはたくさんのアルゴリズムがあります(私のJS実装を含む)。 しかし、この問題には数学的な解決策があり、密に埋められたフィールドに優れた速度を提供し、ルールの複雑さの増加と合計の面積/体積のギャップにすばやく入ります-たとえば、Smoothlife-like( 1、2 )、および3Dバージョン
FFTの実装
アルゴリズムの考え方は次のとおりです。- 合計マトリックス(フィルター)を作成します。ここで、1はセルにあり、その合計を取得する必要があります(8ユニット、残りのゼロ)。 行列に対して直接フーリエ変換を実行します(これは1回だけ実行する必要があります)。
- プレイフィールドのコンテンツを使用して、マトリックスに対して直接フーリエ変換を実行します。
- 結果の各要素に、段落1の「合計」のマトリックスの対応する要素を乗算します。
- 逆フーリエ変換を実行し、必要な各セルの近傍数の合計を含む行列を取得します。
C ++実装
//Author: Mark VandeWettering http://brainwagon.org/2012/10/11/crazy-programming-experiment-of-the-evening/ #include <stdio.h> #include <stdlib.h> #include <math.h> #include <complex.h> #include <unistd.h> #include <fftw3.h> #define SIZE (512) #define SHIFT (18) fftw_complex *filter ; fftw_complex *state ; fftw_complex *tmp ; fftw_complex *sum ; int main(int argc, char *argv[]) { fftw_plan fwd, rev, flt ; fftw_complex *ip, *jp ; int x, y, g ; srand48(getpid()) ; filter = (fftw_complex *) fftw_malloc(SIZE * SIZE * sizeof(fftw_complex)) ; state = (fftw_complex *) fftw_malloc(SIZE * SIZE * sizeof(fftw_complex)) ; tmp = (fftw_complex *) fftw_malloc(SIZE * SIZE * sizeof(fftw_complex)) ; sum = (fftw_complex *) fftw_malloc(SIZE * SIZE * sizeof(fftw_complex)) ; flt = fftw_plan_dft_2d(SIZE, SIZE, filter, filter, FFTW_FORWARD, FFTW_ESTIMATE) ; fwd = fftw_plan_dft_2d(SIZE, SIZE, state, tmp, FFTW_FORWARD, FFTW_ESTIMATE) ; rev = fftw_plan_dft_2d(SIZE, SIZE, tmp, sum, FFTW_BACKWARD, FFTW_ESTIMATE) ; /* initialize the state */ for (y=0, ip=state; y<SIZE; y++) { for (x=0; x<SIZE; x++, ip++) { *ip = (fftw_complex) (lrand48() % 2) ; } } /* initialize and compute the filter */ for (y=0, ip=filter; y<SIZE; y++, ip++) { for (x=0; x<SIZE; x++) { *ip = 0. ; } } #define IDX(x, y) (((x + SIZE) % SIZE) + ((y+SIZE) % SIZE) * SIZE) filter[IDX(-1, -1)] = 1. ; filter[IDX( 0, -1)] = 1. ; filter[IDX( 1, -1)] = 1. ; filter[IDX(-1, 0)] = 1. ; filter[IDX( 1, 0)] = 1. ; filter[IDX(-1, 1)] = 1. ; filter[IDX( 0, 1)] = 1. ; filter[IDX( 1, 1)] = 1. ; fftw_execute(flt) ; for (g = 0; g < 1000; g++) { fprintf(stderr, "generation %03d\r", g) ; fftw_execute(fwd) ; /* convolve */ for (y=0, ip=tmp, jp=filter; y<SIZE; y++) { for (x=0; x<SIZE; x++, ip++, jp++) { *ip *= *jp ; } } /* go back to the sums */ fftw_execute(rev) ; for (y=0, ip=state, jp=sum; y<SIZE; y++) { for (x=0; x<SIZE; x++, ip++, jp++) { int s = (int) round(creal(*ip)) ; int t = ((int) round(creal(*jp))) >> SHIFT ; if (s) *ip = (t == 2 || t == 3) ; else *ip = (t == 3) ; } } /* that's it! dump the frame! */ char fname[80] ; sprintf(fname, "frame.%04d.pgm", g) ; FILE *fp = fopen(fname, "wb") ; fprintf(fp, "P5\n%d %d\n%d\n", SIZE, SIZE, 255) ; for (y=0, ip=state; y<SIZE; y++) { for (x=0; x<SIZE; x++, ip++) { int s = ((int) creal(*ip)) ; fputc(255*s, fp) ; } } fclose(fp) ; } fprintf(stderr, "\n") ; return 0 ; }
ビルドするには、 FFTWライブラリが必要です。 gccで構築するキー:
gcc life.cpp -lfftw3 -lm -lstdc ++Visual Studioでは、複素数の処理に変更が必要です。
実行時の画像:
初期フィルター行列(原点は左上隅、フィールドは「ループ」):

直接FFT後のフィルターの実数部:
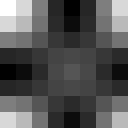
初期フィールドは1グライダーです。
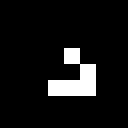
ソースフィールド、実数部と虚数部のFFT:


フィルター行列を掛けた後:


逆FFTの後、量を取得します。

結果は非常に期待されています。
フィールドの「ループ」は、FFTにより自動的に取得されます。
FFTバン
- 任意の係数で任意の数の要素を合計できます-そして、動作時間は固定されたまま 、N 2 logNです。 つまり 古典的な生活の場合-満たされたフィールドでの従来のアルゴリズムは依然として非常に高速であり、面積/合計の体積が増加すると-それらは遅くなり、FFTの速度は固定されたままです。
- FFT-プロセッサのすべての機能(sse、sse2、avx、altivec、およびneon)を使用して、すでに作成、デバッグ、および完全に最適化されています。
- 既製のマルチプロセッサとCUDA / OpenCL FFT実装を採用することにより、すべてのプロセッサとビデオカードを簡単に使用できます。 繰り返しますが、FFTの最適化を気にする必要はありません。 ところで、FFTWはマルチプロセッサの実行をサポートしています(ビルド中の--enable-openmp)。フィールドが大きいほど、同期の損失が少なくなります。
- 同じアプローチが3D空間にも適用されます。
「単純な」実装と速度を比較する
FFTWは単精度モードでアセンブルされます(--enable-float、約1.5倍の速度向上)。 プロセッサー-Core2Duo E8600。 gcc 4.7.2 -O3 素朴な実装のソースコード
for (int i=8; i<1000; i++) { delta[i][0] = (lrand48() % 21)-10; delta[i][1] = (lrand48() % 21)-10; } #define NUMDELTA 18 for(int frame=0;frame<10;frame++) { double start = ticks(); for (y=0; y<SIZE; y++) for (x=0; x<SIZE; x++) { int sum=0; for(int i=0;i<NUMDELTA;i++) sum+=array[readpage][(SIZE+y+delta[i][0]) % SIZE][(SIZE+x+delta[i][1]) % SIZE]; if(array[readpage][y][x]) array[1-readpage][y][x] = (sum>3 || sum<2)?0:1;else array[1-readpage][y][x] = (sum==3)?1:0; } readpage = 1-readpage; printf("NaiveDelta: %10.10f\n", ticks()-start); }
| テスト構成 | 要約するセルの数について、FFTと単純な実現の速度は |
| 1コア、512x512 | 29日 |
| 2コア、512x512 | 18 |
| 1コア、4096x4096 | 88 |
| 2コア、4096x4096 | 65 |
更新:
結局のところ、FFTWは、FFTW_ESTIMATEフラグを指定するときに、最適なFFT計算プランとはほど遠いものを使用します。 FFTW_MEASUREを指定すると、速度が大幅に向上し、状況はすでに満足しています(合計が18セル未満の場合、単純な実装はここですべてが18に依存するため、3倍速くなります)。
| テスト構成 | 要約するセルの数について、FFTと単純な実現の速度は |
| 1コア、512x512 | 18 |
| 2コア、512x512 | 18 |
| 1コア、4096x4096 | 28 |
| 2コア、4096x4096 | 19 |
彼らが何と言っても、プログラミングの数学は、最も予期しない場所で役に立つことがあります。
そして、FFTの力があなたにありますように!