最も興味深いものから始めましょう-オプティマイザー拡張機能
インデックス条件プッシュダウン(ICP) -複合インデックスを使用してテーブル内のデータにアクセスする場合、この最適化が実行されます。 キーの最初の部分の条件を明示的に適用でき、キーの残りの部分の条件を明示的に適用できない場合、たとえば:
-
keypart1 = 1
述語にアクセスし、keypart2 like '%value%'
述語のフィルタリング、 - または、範囲キーの両方の部分に課すには、
keypart1 between a and b
のkeypart1 between a and b
条件はアクセス述語でkeypart2 between c and d
はフィルター述語です(アクセス述語としてのこのタイプのクエリのインデックスは、MySQL
まだ実装されていません)、
その後、
MySQL
サーバーはアクセス述語を適用した後、ストレージエンジンに切り替え、テーブル行を読み取った後、2番目の条件を適用します。 このオプションを使用すると、もちろん、ストレージエンジン自体が
ICP
サポートし、現時点で
MyISAM
および
InnoDB
である場合、この切り替えは行われず、フィルター述語はインデックスデータに基づいて排他的に適用されます。 計画は、
Using index condition
。
テストによると、キャッシュからデータを要求するときのパフォーマンスは約30〜50%であり、入力/出力サブシステムを操作している間、最大100倍の加速が可能です。
マルチレンジリード(MRR) -セカンダリキーを使用して
Range Scan
を実行する場合、任意のディスクリードの回数を減らすために、最初にインデックスから必要なデータをすべて読み取り、次に
ROWID
でソートしてから、プライマリキーでのみデータを読み取ります。 間違いなく素晴らしいという点では、
Using MRR
です。 この操作はビームです。 つまり 二次キーによってアクセス述語を適用し、利用可能なバッファを埋め、その後のみデータをソートして読み取ります。 ここで、幸運とデータが互いに近いかどうか。 分散テーブルの場合、状況はさらに良くなりますが、これはこの記事の範囲外です。 純粋な形式では、このアルゴリズムは1つのテーブルでクエリを実行するときに適用できます。 また、 バッチキーアクセス(BKA)と組み合わせることで、結合操作を高速化することもできます。 デフォルトでは、
BKA
フラグはオフになっており、その値は、オプティマイザーフラグの値と同様に、
SELECT @@optimizer_switch
要求を実行することで表示できます。 BKAが有効になっている場合、
join_buffer_size
パラメーターの異なる値でリクエストを確認する必要があります。このパラメーターは最大バッファーサイズの計算に使用されるためです。 この素晴らしいアルゴリズムをクエリの観点から適用すると、
Using join buffer (Batched Key Access)
ます。 トピックの詳細はこちらをご覧ください 。 テスト結果によると、この最適化は、入力が出力されディスクで動作する場合にのみ、大幅な加速を実現できます。 この場合、
MRR
のみ10倍の加速を得ることができます。
MRR
と
BKA
併用により、他の多くの合成テストで最大280倍の加速が得られました。 メモリのみで作業する場合、この操作は入力と出力を排他的に最適化するように設計されているため、非常に論理的な加速は得られません。
ファイルの並べ替えの最適化 -インデックス化されていない列による並べ替えは、特定の条件のもとではるかに生産的になりました。 以前は、このタイプのソートを実行する場合、可能な唯一のオプションはマージソートでした。 大まかに言うと、リクエストの結果として取得されたデータは一時テーブルに保存されていました。 その後、このテーブルに対してソートが実行され、
LIMIT
条件を満たすレコードが返されました。 ご覧のとおり、このアルゴリズムはあまり生産的ではありません。特に、少数の行を返すクエリが多数ある場合はそうです。 入力を最適化するために、出力アルゴリズムが次のように変更されました。 クエリの結果として受信したレコードの数が
sort_buffer_size
に完全に配置されている場合、テーブルのスキャン時にキューが作成されます。 このキューは順序付けられ、クエリ結果の次の行が受信されるとすぐにいっぱいになります。 キューサイズは
N
(または
LIMIT M, N
構成が使用される場合は
M + N
)です。 キューがいっぱいになると、最後から余分なデータがスローされます。 したがって、並べ替えの終了はクエリ結果の終了と同時に実行され、一時テーブルへの呼び出しはありません。 オプティマイザーは、ソートの戦略を個別に選択します。 キューは、プロセッサをさらにロードする必要があるときに使用され、入力/出力システムが利用可能なときにソートをマージします。
模擬試験を実施すると、4倍の加速が得られました。 ただし、この最適化により、出力入力サブシステムの負荷を軽減できることも理解しておく必要があります。これにより、インスタンス全体の作業にプラスの影響があります。
サブクエリの最適化
postpone materialization
化の
postpone materialization
-主にクエリプランの構築の高速化に関連します。 以前は、
EXPLAIN
コマンドを実行すると、
FROM
セクションで使用されるサブクエリが具体化されて、それらの統計が取得されていました。 つまり 実際、これらのクエリはデータベースで実行されました。 現在、この操作は実行されず、DBインスタンスをロードせずにクエリプランを取得することが可能になりました。 ただし、たとえば、
FROM
セクションに2つの実体化可能な表現があり、最初のレコードが単一のレコードを返さない場合、2番目のレコードは実行されないなど、クエリの実行時間も短縮できます。 また、クエリの実行中に、MySQLは必要に応じて、結果のマテリアライズテーブルに個別にインデックスを付けることができます。
semi-join transformation
-
semi-join transformation
は、すべてのデータベースの別のテーブルのデータに基づいて、1つのテーブルのみからデータを取得するために使用できます。典型的な例は
EXISTS
コンストラクトです。 この最適化の使用は、以前は非常にうまく機能しなかった
IN
デザインで可能になりました。 この最適化を可能にするためには、サブクエリが以下の条件を満たす必要があります:
UNION
、
GROUP BY
および
HAVING
、
LIMIT
制約付きの
ORDER BY
なし(これらの構造は別々に使用できます)。 また、サブクエリの数が
JOIN
に許可されるテーブルの最大数を超えないようにする必要があります。そうしないと、
MySQL
はこのクエリを書き換えることができません。 最適化は、
SEMI JOIN
リクエストを書き直すか、
FROM
構文でサブクエリを
VIEW
として提示し、上記の
postpone materialization
化の最適化を使用することで
postpone materialization
されます。 最終結果からの重複エントリは、次の方法で削除されます。
- 最終クエリの一意の結果を一時テーブルに配置することにより(
Start temporary
Extra
計画」列のStart temporary
およびStart temporary
にEnd temporary
」) - サブクエリからテーブルをスキャンする段階で「最初に見つかった」基準を使用する
FirstMatch(tbl_name)
Extra
plan列のFirstMatch(tbl_name)
) - 最適化を使用するLoose Index Scan (
LooseScan(m..n)
ここで、mおよびnはこの最適化に使用される重要な部分です)
サブクエリを実体化してからインデックスを作成するとき、
MATERIALIZED
はクエリプランの
select_type
列にあります。 要求がどのように書き換えられたかを正確に理解するには、標準の
EXPLAIN EXTENDED
コマンドを使用できます。 これにより、リクエストがどのように書き換えられたか、および最適化が適用されたかどうかを常に理解できます。
ご存知のように、 曲がって書かれたクエリを書き直すと (このようなクエリに手を出さなかったので、今では許されなくなっています)、パフォーマンスが大幅に向上する可能性があるため、
table pullout
テストを実行することはほとんど意味がありません(
FROM
WHERE
からサブクエリを削除し
table pullout
)、生産性が1000倍に増加しても制限はありませんが、すべてのクエリが正しく記述されていれば、このタイプの最適化から異常な何かを待つことはできません。
InnoDB
静的統計
最後に、それは起こりました。
Google
、
Percona
または
Oracle
自体のどこからかはわかりませんが、
MySQL
、クエリプランの構築から動的サンプリングを除外する
MySQL
が可能になりました。 現在、テーブルとインデックスの統計は永続テーブルに保存されます。 この統計収集方法はデフォルトで有効になっています。 テーブル内のデータの10%以上を更新すると、その統計は自動的に再構築されます(もちろん、これは変更できます)。 また、統計の収集は、
ANALYSE
コマンドを使用して強制的に開始できます。 オプティマイザーが前例のないほど愚かであるときに統計を強制的にリセットするには、
FLUSH TABLE
コマンドを呼び出します。 正確に何が行われるかは、新しいテーブル
mysql.innodb_index_stats
、
mysql.innodb_table_stats
で明確に見ることができます。 これは確かにOracleの高度なヒストグラムではなく、実際の進捗状況です。 現在、計画はより安定しており、一方で、DBAには新しいエンターテイメントがあります:テーブルの統計が無関係になったときに送信し、ダウンタイムを見つけ、サンプリングの量を推測して再計算します。特に開発者ブログからのとおり、統計はハンドルによって変更できます、直接更新による。 また、テストの実行時に、バックグラウンドスレッドで動作していると思われる統計情報コレクターがデータを処理できなかったことにも注意してください。 分析を手動で開始するまで、長い間統計は空のままでした。 特定のパーティションに対して統計分析を実行することは不可能であるため、パーティション化されたテーブル全体を分析する必要がありましたが、もちろんあまり便利ではありません。 アクティブなDMLを実行してベースを停止した場合も、同じ状況が発生します。 データは-統計なしになります。 しかし、これらは例外的な状況であり、データベースの通常の操作を妨げることはないと思います。
オプティマイザーに関する結論として、Maria DB 5.5オプティマイザーは専門家によればより洗練されているが、MySQL 5.6では同様の最適化が多数行われているため、パフォーマンスが向上していることに注目する価値があります。
より良いミューテックスと異なるミューテックス
誰もがよく知っているように、MySQLは、同時に実行される多数のトランザクションを備えた多数のプロセッサに対して十分に拡張できません。 この理由は、内部ロック、特に
kernel mutex
、およびマルチコアアーキテクチャでメモリを操作する際の基本的な問題です。 アクティブなトランザクションのリストをコピーするために保持される
Kernel mutex
、非ブロッキングおよびブロッキングトランザクション、ロック、ロック待機などのためにいくつかのミューテックスに分割されました。
false sharing
の問題も解決されました.1つのコアが必要な不変データをロードし、そのために必要なもう1つのコアが1つの
cacheline
で変更されたため、最初のコアのデータは常にキャッシュから洗い流されました。 現在、多くの重要なオブジェクトに64バイトのアライメントが導入されています。
開発者のブログによると、
MySQL
は
read only
トランザクションで最大50%向上してい
read only
。 また、アクティブセッション数の増加によるパフォーマンスの向上は、以前のバージョンと比較して最大600%でした。 独立した負荷テストを実行する場合、最大16の同時セッション-速度は変わらず、より高速-混合読み取り/書き込みトランザクションで最大100%、読み取り専用トランザクションで最大300%。
UNDOリセットの最適化
UNDOを並行してリセットできるようになりました。 これを行うには、
innodb_purge_threads
パラメーターを1より大きい値に設定します。産業用データベースでこのパラメーターを
innodb_purge_threads
は、パーティションテーブルから大量のデータを並列で削除する場合にのみ妥当です。 データをリセットするときに
dict_index_t::lock
ハングするため、パーティションを使用しない人、またはパラレルDML以外の理由でパーティションを使用する人(たとえば、DML操作が1つのパーティションのみで実行されるアーカイブ)のパフォーマンスの改善は行われません。 これらの場合、以前と同様に、メインストリームとは別のデータダンプを単純に割り当てることをお勧めします。
ダーティブロックの最適化
ご存じのように、メモリからダーティブロックをダンプすることは、バージョン管理されたデータベースにとって最も問題のある場所の1つです。 ブロックの必要な部分をディスクにリセットするには、メインの
InnoDB Master Thread
で行い、全員が待機するか、基本的にバックグラウンドスレッドとして特定のセッションがリセットコマンドを送信し、このセッションが無期限にハングし、残りはセッションはブロックされません。 最初と2番目の両方の問題を回避するために、
page_cleaner
と呼ばれる別のスレッドが作成されました。 このストリームのビジー状態の詳細については、 こちらをご覧ください。
select name, comment from information_schema.innodb_metrics where name like 'buffer_flush_%';
これで、ブロックリセットが実際に非同期的に実行され始めました。 ブロックのリセットパラメーターを使用することにした場合は、新しい
LRU flush
最適化パラメーターにも注意を払うことをお勧めします。これらのパラメーターは、
MySQL
開発者の結論によると、互いに間接的に影響を与える可能性があるためです。
ブロックリセットはSSDドライブに適合しました。 このあいまいなフレーズは、次のことを示しています。 知っているように、ブロックキャッシュはページで発生します。 エクステントは64ページです。 同じエクステント内でこれらの同じ連続ページを呼び出すネイバーフッド。 以前は、ページを変更する際、
InnoDB
はエクステント全体を収集してデータをディスクにフラッシュして出力を最適化しようとしました。HDDの場合、1メガバイトが最適なサイズであり、ディスクへの1回の呼び出しで操作を実行できるためです。 SSDの場合、ダンプサイズは4キロバイトしかないため、何かを入力しても意味がありません。 さらに、変更されていないページをダンプすることも無意味です。 だから、newfangled鉄の所有者は、 パラメーターで遊ぶことができます 。
結論として、 このテストの結果に気付くのは場違いではありません。


グラフからわかるように、キャッシュを操作するとき、最適化されたリセットを使用した新しいバージョンは、少数のセッションで
MySQL 4.0.30
失い
MySQL 4.0.30
(非常に多くの古代バージョンを選択する理由は不明です)が、スケーリングすると1桁優れた結果を示します。

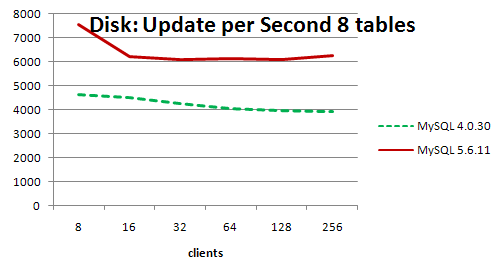
ファイルシステムで作業する場合、結果はそれほど印象的ではなく、両方のバージョンが真っ向から向かい、MySQL 5.6でも場所を失います。 しかし、著者の結論によると、リリース
5.6.12
、この欠点は解消され、生産性は3倍に跳ね上がります。 つまり 大規模な入出力とバッファのディスクへのアクティブなフラッシュに問題がある場合は、次のバージョンがリリースされるのを待つ価値があります。
InnoDB:ALTER TABLE ...オンライン
この技術のすべての称賛は、2つの言葉で平易に宣伝できます。 開発者によると、このチームは完全に書き直されましたが、
InnoDB-engine
チームは
InnoDB-engine
大きな利点を得られませんでした。
online
では、限られた数の非常にまれな操作のみが実行され、制限があります。 操作が
online
ことを理解するの
online
非常に簡単です。 リクエストの結果として、あなたは受け取るでしょう
Query OK, 0 rows affected
そして、何ができるのか:
-
CREATE INDEX, DROP INDEX
これらのコマンドの実行はテーブルを完全にはコピーしないという事実に慣れていますが、テーブル内のデータの更新はブロックします。 これは、インデックスの構築が以前にテーブル上で直接実行され、ソートおよびマージの時点で完全なデータのセットがあったため、最もバランスの取れたインデックスツリーを作成できるためです。 これで、インデックスの作成時に、読み取り専用ロックがテーブルでハングします。 テーブルに到着する、またはテーブルから消える新しいデータは、change buffer
構造との類推によって作成される特別なログファイルに分類され、ファイルサイズは変数innodb-online-alter-log-max-size
によって規制されinnodb-online-alter-log-max-size
。 ソートとマージ(ソートバッファーのサイズはinnodb-sort-buffer-size
変数によって調整されます)後、新しいインデックスのデータはビームでREDO
ログにフラッシュされ、その後、登録済みの変更がロールアップされます。 出来上がりとインデックスは使用可能です。 一方では、これはテーブルをブロックしませんが、他方では、作成されたインデックスの構造は最初の場合ほど理想的ではなく、アクティブなDML
テーブルの場合の作成には長い時間がかかる可能性がありますが、これはもちろん些細なことです。 - テーブルの
auto-increment
値の変更は、主キー値に基づいてインスタンスごとにデータを分離する自己記述シャーディングを使用するユーザーにとって間違いなく便利です。 -
DROP FOREIGN KEY
削除のみ、定数の追加はまだマスターされていませんが、ボーナスとして、定数とそれに関連付けられたインデックスを1つのコマンドで削除できました。ALTER TABLE table DROP FOREIGN KEY constraint, DROP INDEX index;
MySQLサポートチームメンバーsvetasmirnovaからの公正なコメント:「foreign_key_checks
オフになっている場合にのみ追加することもできます」。この場合、テーブルはコピーされません。 - 列の名前を変更する-
online
は、データ型が変更されていない場合にのみ可能です。 辞書データのみが変更されます。 繰り返しになりますが、ボーナスとして、外部キーの一部であるコロスの名前を変更することができました。
まあ、それがすべてです。 可能性の説明からわかるように、 私たちに提供される機会は非常に少なく 、将来的に状況が改善し、タンバリンと踊ることなく大きなテーブルへの変更を実行できることを願っています。これは、実行中のテーブルの完全なコピーに関連付けられています(
MySQL 5.6
5 )
DDL
コマンド。
パーティショニング
パーティションエンジンは大幅に再設計されました。 現在、処理のためのパーティションの選択は、テーブルを開いてロックを設定するよりも早く実行されます。 パーティションキーに対する単純なクエリの入力入力の分析を次に示します。
select count(1) from part_table where partition_key = 190110; +----------+ | count(1) | +----------+ | 500 | +----------+ 1 row in set (0.50 sec)
入出力とバッファプール
select count(distinct file_name) file_name_count, sum(sum_number_of_bytes_read) sum_number_of_bytes_read, min(substring_index(file_name, '/', -1)) min_file_name, max(substring_index(file_name, '/', -1)) max_file_name from performance_schema.file_summary_by_instance where file_name like '%part_table%.ibd' and count_read + count_write > 0 order by 1; -- Server version: 5.5 +-----------------+--------------------------+------------------------------------+------------------------------------+ | file_name_count | sum_number_of_bytes_read | min_file_name | max_file_name | +-----------------+--------------------------+------------------------------------+------------------------------------+ | 1024 | 107692032 | part_table#P#part_table_184609.ibd | part_table#P#part_table_190110.ibd | +-----------------+--------------------------+------------------------------------+------------------------------------+ -- Server version: 5.6 +-----------------+--------------------------+------------------------------------+------------------------------------+ | 1 | 98304 | part_table#P#part_table_190110.ibd | part_table#P#part_table_190110.ibd | +-----------------+--------------------------+------------------------------------+------------------------------------+ select min(table_name) min_table_name, max(table_name) max_table_name, count(distinct table_name) file_name_count, sum(data_size) pool_size from information_schema.innodb_buffer_page where table_name like '%part_table%'; -- Server version: 5.5 +--------------------------------------+--------------------------------------+-----------------+-----------+ | min_table_name | max_table_name | file_name_count | pool_size | +--------------------------------------+--------------------------------------+-----------------+-----------+ | test/part_table#P#part_table_184609 | test/part_table#P#part_table_190110 | 1024 | 26567424 | +--------------------------------------+--------------------------------------+-----------------+-----------+ -- Server version: 5.6 +--------------------------------------+--------------------------------------+-----------------+-----------+ | Partition `part_table_190110` | Partition `part_table_190110` | 1 | 32048 | +--------------------------------------+--------------------------------------+-----------------+-----------+
ご覧のとおり、バージョン5.5とは対照的に、指定されたテーブルのすべてのパーティションではなく、条件に対応するパーティションの統計のみが分析されます。残りのパーティションをバッファプールにロードすることを除外します。
ロックについては、何もまだ明確ではありません。解析してリクエストの完了を待つアルゴリズムが大幅に変更されているため、
wait/synch/mutex/mysys/THR_LOCK::mutex
以前は各パーティションでブロックされていた最もホットなミューテックスはあまり一般的ではなくなりました。 1つのパーティションを照会する場合、このテーブル内の合計パーティション数に2を掛けた回数はそれほど多くブロックされず、1つだけがブロックされます。これは間違いなく大きなプラスです。私は、同様の攻撃的な振る舞いを持つ他のロックをまだ見つけることができませんでした。どうやらポストに示されているエンジンの問題削除されました(独立して維持せずにパーティションのリストを取得するには、テーブルを使用できます。
mysql.innodb_table_stats
パーティションが作成されたときにエントリが追加され、実際の統計が後で表示されます)。また、快適なことから、1つのテーブルのパーティションの最大可能数の制限の増加に注意することができます。私は個人的にエンジンに関する苦情はないので、パーティションが並列処理用に作成されることに注意する価値があり
hint parallel(n)
ます。パーティションテーブルを待っています。
バックアップと復元
新しいバージョンでは、InnoDBの2つの非常に期待される機能が一度に追加されました。
EXCHANGE PARTITION
ALTER TABLE part_table EXCHANGE PARTITION p1 WITH TABLE non_part_table;
すべてが標準です。テーブルは、インデックスを含む完全に同一の構造を持っている必要があります。また、
storage engine
パーティション化されていないテーブルのデータは、交換されたパーティションの境界を超えないようにする必要があります。
Transportable Tablespaces
ご存知のように、
.ibd
ファイルを変更してデータがあることを期待するだけでは機能しません。
REDO
ログ、データディクショナリ、システムカラム、テーブルスペースメタデータなどを考慮する必要があります。 :このような操作は、ここ一連のコマンドによって提供されるため
、エクスポートDB
-
FLUSH TABLES table_one, table_two FOR EXPORT;
-コピー
.ibd
データベースディレクトリから生成された設定ファイル
データベースをインポートする
-類似した構造の空のテーブルを作成する
-
ALTER TABLE table_one DISCARD TABLESPACE;
-コピー
.ibd
データベースディレクトリに生成された構成ファイル
-
ALTER TABLE table_one IMPORT TABLESPACE;
操作はデータディクショナリを通じて実行されます。
パフォーマンススキーマ
パフォーマンス診断回路が大幅に改善されました。まず、彼女の仕事は3倍速くなりました。現在オンになっているときのパフォーマンスの低下は10%ではなく、3.5%に過ぎないため、デフォルトでオンにできます。これに加えて、図には以前のように17個のテーブルはありませんが、52個あります。理解できるように多くの変更があります。それらすべてを説明する必要がある場合は、別の記事が必要です。
- リクエストを直接トレースできるようになりました
show tables like '%statements%'; +----------------------------------------------------+ | Tables_in_performance_schema (%statements%) | +----------------------------------------------------+ | events_statements_current | | events_statements_history | | events_statements_history_long | | events_statements_summary_by_account_by_event_name | | events_statements_summary_by_digest | | events_statements_summary_by_host_by_event_name | | events_statements_summary_by_thread_by_event_name | | events_statements_summary_by_user_by_event_name | | events_statements_summary_global_by_event_name | +----------------------------------------------------+ 9 rows in set (0.01 sec)
- (
object_type= 'TEMPORARY TABLE'
, - , )
select digest_text, sum_rows_affected, sum_rows_sent, sum_rows_examined from events_statements_summary_by_digest; +---------------------------------------+-------------------+---------------+-------------------+ | digest_text | sum_rows_affected | sum_rows_sent | sum_rows_examined | +---------------------------------------+-------------------+---------------+-------------------+ | SHOW VARIABLES | 0 | 4410 | 4410 | ... | SET NAMES utf8 | 0 | 0 | 0 | +---------------------------------------+-------------------+---------------+-------------------+ 48 rows in set (0.00 sec)
-
show tables like '%by_thread%'; +---------------------------------------------------+ | Tables_in_performance_schema (%by_thread%) | +---------------------------------------------------+ | events_stages_summary_by_thread_by_event_name | | events_statements_summary_by_thread_by_event_name | | events_waits_summary_by_thread_by_event_name | +---------------------------------------------------+ 3 rows in set (0.00 sec)
- , , ,
select digest_text, sum_created_tmp_disk_tables, sum_created_tmp_tables from events_statements_summary_by_digest; +--------------------------------------------------------+-----------------------------+------------------------+ | digest_text | sum_created_tmp_disk_tables | sum_created_tmp_tables | +--------------------------------------------------------+-----------------------------+------------------------+ | SHOW VARIABLES | 0 | 10 | ... | SELECT `routine_schema` , `specific_name` FROM INF... | 2 | 2 | ... | SHOW TABLE STATUS FROM `performance_schema` LIKE | 0 | 52 | +--------------------------------------------------------+-----------------------------+------------------------+ 49 rows in set (0.00 sec)
- , ,
show tables like 'table%waits%sum%'; +-------------------------------------------------+ | Tables_in_performance_schema (table%waits%sum%) | +-------------------------------------------------+ | table_io_waits_summary_by_index_usage | | table_io_waits_summary_by_table | | table_lock_waits_summary_by_table | +-------------------------------------------------+ 3 rows in set (0.01 sec)
私がお勧めすることができます興味のある人のためにここにされて、私はウェビナーは初心者のためにしているため非常に多くの変更のバージョン5.5で、このスキームに精通した者、の両方に有用であろうと思います。スキームはデフォルトで有効になっているため、設定は非常に控えめです。たとえば、5.5のメインテーブルには
events_waits_history_long
100エントリしかないため、これらのパラメーターはすべて静的であり、変更するにはインスタンスの再起動が必要なので、事前に設定を決定することをお勧めします。
おわりに
結論として、私は彼の最近の記事で表明されたピーター・ザイツェフの結論を引用することができます。模擬テストの結果によると、1スレッドの負荷で
MySQL 5.6
は以前のバージョンより
MySQL 5.5
7.5〜11%遅く、64スレッドの負荷では11〜26パーセント遅くなります。これは公式バージョンとは根本的に異なります。つまり誰もが最適に書き直しましたが、パフォーマンスを向上させることはできませんでした。上記で述べたすべての最適化により、結論は単純に驚くべきものになりますが、もちろん自分で環境を確認した方がよいでしょう。たとえば、私たちにとって重要な場所は手続きの呼び出しです。このために、私たちは自己記述型のオープンフレームワークを使用します; ハブの開発者にはesinev、jbdc-procがあります。オウムの測定は次のとおりです。
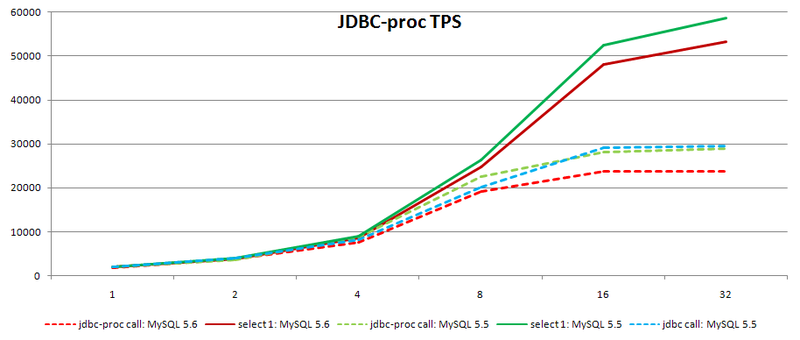
ご覧のように、サーバーのパフォーマンスは向上しませんが、逆に、オウムは20%に低下しますが、新しいバージョンをインストールすると、ボトルネックをより簡単に見つけることができる多数の診断ツールを入手できます。これに加えて、MySQLが正しい方向に進んでいることが明らかになりました。安定性を確認するためにいくつかのバージョンを待ってから、バージョンをアップグレードする予定です。