私は5年以上にわたって時系列予測を行ってきました。 昨年、 「 最大類似度サンプルの時系列予測モデル 」というトピックに関する論文を擁護しましたが、弁護後には適切な質問がありました。 その1つが、予測方法とモデルの一般的な分類です 。
通常、国内および英語圏の著者の作品では、予測方法とモデルの分類については尋ねず、単にそれらをリストします。 しかし、今日、この領域は非常に大きく拡大しているため、最も一般的でも分類が必要です。 以下は、私自身の一般分類のバージョンです。
メソッドと予測モデルの違いは何ですか?
予測方法は、予測モデルを取得するために実行する必要がある一連のアクションです。 料理と同様に、方法は料理を準備する一連のアクションです。つまり、予測が行われます。
予測モデルは、調査中のプロセスを適切に説明する機能的表現であり、将来の値を取得するための基礎となります。 同じ料理の例えで、モデルには成分とその比率のリストがあり、これは私たちの料理-予測に必要です。
メソッドとモデルの全体が完全なレシピを形成します!
現在、モデルとメソッドの両方の名前に英語の略語を使用するのが習慣です。 たとえば、自動回帰統合移動平均拡張(ARIMAX)の有名な予測モデルがあります。 このモデルとそれに対応するメソッドは、通常ARIMAXと呼ばれ、著者の名前によるBox-Jenkinsモデル(メソッド)と呼ばれることもあります。
まず、メソッドを分類します
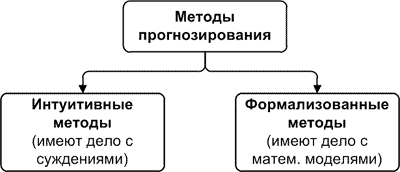
よく見ると、「 予測方法 」の概念が「 予測モデル 」の概念よりもはるかに広いことがすぐに明らかになります。 この点に関して、分類の最初の段階では、メソッドは通常2つのグループに分けられます:直感的で形式化された[1]。
料理の類推を思い出せば、すべてのレシピを正式なレシピに分けることができます。つまり、成分の数と準備の方法によって記録され、直感的です。つまり、どこにも記録されず、料理人の経験から得られます。 いつレシピを使用しないのですか? 料理が非常に簡単な場合:ポテトフライまたはor子を調理する-レシピは必要ありません。 他にいつレシピを使用しないのですか? 何か新しいものを発明したいとき!
直感的な予測方法は 、専門家の判断と判断を扱います。 行動を予測する必要があるシステムは非常に複雑で数学的記述に反するか、非常に単純でそのような記述を必要としないため、今日ではマーケティング、経済学、政治でよく使用されます。 そのような方法の詳細は、[2]にあります。
形式化された方法は、文献に記載されている予測方法であり、その結果として予測モデルが構築されます。つまり、プロセスの将来価値を計算する、つまり予測を行うことができるような数学的依存性を決定します。
これで、私の意見では予測方法の一般的な分類を完了することができます。
次に、モデルの一般的な分類を行います
ここで、予測モデルの分類に進む必要があります。 最初の段階では、モデルはドメインモデルと時系列モデルの2つのグループに分割する必要があります。
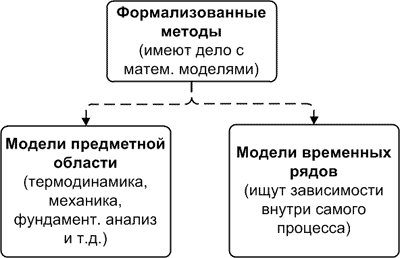
ドメインモデルは予測の数学的モデルであり、その構築にはドメインの法則が使用されます。 たとえば、天気予報を作成するモデルには、流体力学と熱力学の方程式が含まれています。 人口開発の予測は、微分方程式に基づいて作成されたモデルで行われます。 糖尿病患者の血糖値の予測は、微分方程式系に基づいて行われます。 つまり、特定のサブジェクト領域に固有の依存関係がこのようなモデルで使用されます。 このようなモデルは、開発に対する個々のアプローチによって特徴付けられます。
時系列モデルは数学的予測モデルであり、プロセス自体の中で過去の将来価値の依存性を見つけ、この依存性に依存して予測を計算しようとします。 これらのモデルは、さまざまなサブジェクト領域に共通です。つまり、時系列の性質に応じて一般的な外観は変わりません。 ニューラルネットワークを使用して気温を予測し、その後、ニューラルネットワークに同様のモデルを適用して株価指数を予測できます。 これらは、沸騰したお湯のような一般化されたモデルで、製品を投げると、その性質に関係なく沸騰します。
時系列モデルを分類します
ドメインモデルの一般的な分類を作成することは不可能であるように思えます。領域がいくつ、モデルが非常に多いのでしょうか。 ただし、時系列モデルは簡単な除算に簡単に対応できます[3]。 時系列モデルは、統計と構造の2つのグループに分類できます。
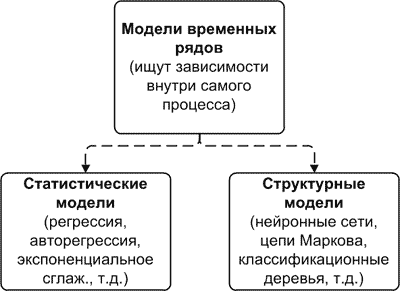
統計モデルでは 、過去の将来価値の依存性は、何らかの方程式の形で与えられます。 これらには以下が含まれます。
- 回帰モデル(線形回帰、非線形回帰);
- 自己回帰モデル(ARIMAX、GARCH、ARDLM);
- 指数平滑化モデル。
- 最大類似モデル;
- など
構造モデルでは 、過去の将来価値の依存性は、特定の構造とそれに沿った遷移の規則の形式で指定されます。 これらには以下が含まれます。
- ニューラルネットワークモデル;
- マルコフ連鎖に基づくモデル。
- 分類および回帰ツリーに基づくモデル。
- など
両方のグループについて、メイン、つまり最も一般的で詳細な予測モデルを示しました。 しかし、今日では膨大な数の時系列予測モデルがあり、予測を行うために、たとえば、SVM(サポートベクターマシン)モデル、GA(遺伝的アルゴリズム)モデル、その他多くのモデルを使用し始めました。
一般分類
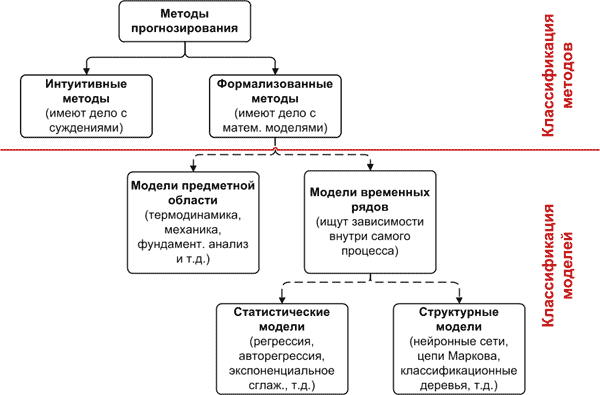
したがって、 モデルと予測方法の次の分類を得ました。
参照資料
- ティホノフE.E. 市況の予測。 ネビンノミスク、2006.221秒
- Armstrong JS Forecasting for Marketing //マーケティングの定量的手法。 ロンドン:International Thompson Business Press、1999。P。92-119。
- Jingfei Yang M. Sc。 電力システムの短期負荷予測:博士号の学位。 ドイツ、ダルムシュタット、電子技術および情報技術大学、2006年。139p。
UPD。 2016年11月15日。
紳士、それは狂気に達しました! 最近、このエントリを参照して、VAKエディションの記事をレビューのために送信しました。 卒業証書や記事でブログを参照することはできませんが、学位論文ではブログを参照することはできません 。 リンクが必要な場合は、これを使用してください: I. Chuchueva 最大の類似性、論文などを選択するための時系列を予測するためのモデル... それら。 科学/モスクワ州立工科大学。 N.E. バウマン。 モスクワ、2012年。