 すべての人に挨拶!
すべての人に挨拶!
この投稿では、「C ++ Tasks Marathon」から探し出したいくつかの問題の解決策について説明します(リンクは検索エンジンで簡単に見つけることができると思います)。 いいえ、私は間違いなくサイトとは何の関係もありませんが、ハブからそれについて学びました:私のプロフィールに誰かがいたか、コメントにリンクがありましたが、これは地元の陰謀理論の信者が簡単にトピックを無視するのを防ぐとは思いませんが。 私は息を吐きました...それで、解決策が考慮される問題を決定しましょう(問題は9つしかありませんが、これらは私にとって興味深いようでした)。
- 掛け方を忘れました。 助けて!
乗算演算を使用せずに数値に7を乗算します。
- ツーインワン。
ある賢い人がエレベーターのボタンを交換しました。 1階の代わりに2階を置き、2階の代わりに1階を置きます。 正直なところ、私はボタンを選ぶのが面倒です。 むしろエレベーターを再プログラムしたいです。 しかし、私はプログラムするのが面倒です。 あなたのすべての希望。 入力2の場合は1、入力1の場合は2を返すスイッチ関数を作成してください。
準備する
通常、私はそのような「面白い」(そしておそらく、認知的な)種類の問題を解決するためにまったく描かれていません(描かれていません)が、今回は窓の外の美しい天気、またはスムーズに流れるオンオフ彼らの仕事をし、私は決めました。 すでに説明したように、C ++でのタスクの特定のマラソンについての記事(3つの記事のサイクルを書く方が正しい)に出会いました。 好奇心が勝ち、解決策を概説することにしました。しかし、いつものように頭ではなく、紙の上に。 そして、ご想像のとおり、最初の取り消し線の後、私はこの妄想のレッスン(紙に書く)を終えて、このように決めました:単純なテキストエディター(gedit)のみを使用し、極端な場合はgoogleを使用します。
行こう
タスク回数:
掛け方を忘れました。 助けて! 乗算演算を使用せずに数値に7を乗算します。シングルスレッド実行モデルのソリューションは、それ自体を提案します。
- 引数として7で乗算される数値を受け取る関数は、7つの連続した加算を実行し、その後結果(ランタイム)を返します。
// typedef unsigned long long TCurrentCalculateType; inline TCurrentCalculateType mulby7(TCurrentCalculateType value) { return value + value + value + value + value + value + value; } // , assert() // #include <assert.h> #ifdef DEGUB assert(mulby7(1) == 7); assert(mulby7(7) == 49); #endif //DEBUG
- Nで乗算される数値を引数として受け取り、ループでN連続加算を実行し、結果(実行時)を返す反復関数:
// // typedef unsigned long long TCurrentCalculateType; inline TCurrentCalculateType mulbyN(unsigned long long times, TCurrentCalculateType value) { TCurrentCalculateType result = 0; for(unsigned long long i = 0; i < times; ++i) result += value; return result; } // , assert() // #include <assert.h> #ifdef DEGUB assert(mulbyN(7, 1) == mulbyN(1, 7)); assert(mulbyN(7, 7) == 49); #endif //DEBUG
- Nを引数として乗算する数値を受け取るパラメーター化されたクラスは、テンプレートを再帰的にインスタンス化して、Nの順次加算を実行します。その後、クラスの静的constメンバーで結果が使用可能になります (compiletime)。
// // typedef unsigned long long TCurrentCalculateType; // : , , : , ... // N + 1 ( ) template <typename T, T value, int step> struct mulStep { static const T partSumm = value + mulStep<T, value, step - 1>::partSumm; }; // , template <typename T, T value> struct mulStep<T, value, 0> { static const T partSumm = 0; }; template <unsigned long long times, TCurrentCalculateType value> struct mulbyNct { static const TCurrentCalculateType result = mulStep<TCurrentCalculateType, value, times>::partSumm; }; static_assert(mulbyNct<7, 7>::result == 49, "Imposible!"); static_assert(mulbyNct<10, 10>::result == 100, "Imposible!");
はい、3番目のオプションは「オンザフライ」で書かれていませんでした。記憶にある要因計算の例をリフレッシュしなければなりませんでした。 私は何をすべきかを見ました。 しかし、実際には、私は元々次のコードを書きました。使用中のコードは、上記で提案したものよりもオーガニックに見えますが、いくつかの(論理)制限のために収集されません。
template <int times, typename T> inline T mulbyNct(T value) { return mulStep<T, value, times>::partSumm; } // ... // std::cout << mulbyNct<7>(calcMeDigit) << std::endl; // . :(
「うそをつく、男」、注意深い読者は言うでしょう。 パンくずリストを最適化できることに同意します。valueに等しい初期値で
result
初期化すると、サイクルの1ステップを節約できます。 取得するもの:
// // typedef unsigned long long TCurrentCalculateType; inline TCurrentCalculateType mulbyNlittleFast(unsigned long long times, TCurrentCalculateType value) { TCurrentCalculateType result = value; // for(unsigned long long i = 1; i < times; ++i) // result += value; return result; } // // , #undef mulbyN #define mulbyN mulbyNlittleFast // , assert() // #include <assert.h> #ifdef DEGUB assert(mulbyN(7, 1) == mulbyN(1, 7)); assert(mulbyN(7, 7) == 49); #endif //DEBUG
「まだいくつかの選択肢があります」と私は考え、 このWebサイトを開いてファンクターを見て、4番目の選択肢に気付きました。
- この4番目のオプション:
// // typedef unsigned long long TCurrentCalculateType; inline TCurrentCalculateType mulbyNSTL(unsigned long long times, TCurrentCalculateType value) { TCurrentCalculateType result = value; std::binder1st<std::plus<TCurrentCalculateType> > plus1st(std::plus<TCurrentCalculateType>(), value); for(unsigned long long i = 1; i < times; ++i) result = plus1st(result); return result; } // , assert() // #include <assert.h> #ifdef DEGUB assert(mulbyNSTL(7, 1) == mulbyNSTL(1, 7)); assert(mulbyNSTL(7, 7) == 49); #endif //DEBUG
私は結婚する必要があり、そのようなモンスターを発明する必要はないことを知っています...しかし、今ではそうではありません。 どのソリューションが「優れている」かを説明するには、まず比較のメトリックを決定する必要があります。 良い-使用されるメモリとランタイムの最小積のメトリック:
algo_diff = used_mem * calc_time;
algo_winner = min(algo_diff(1, 2, 3, ..., N))
天気がいいので、実行時間を最小限に抑えることに専念することにしました。速いほど良いです。
戦う準備をする
私自身が書きたくなかったものから始めましょう。実行時間の「タイマー」です。 測定には、インターネットで一度見つかったクラスを使用します。 クラスは小さくてシンプルですが、彼でさえRAIIの原則の類似性を使用しています(はい、再びGoogleヘルプ)。 これをスタックと出来上がりに置きます:
#include <stdio.h> #include <string> #include <sys/time.h> #include <sys/timeb.h> class StackPrinter { public: explicit StackPrinter(const char* msg) : msMsg(msg) { fprintf(stdout, "%s: --begin\n", msMsg.c_str()); mfStartTime = getTime(); } ~StackPrinter() { double fEndTime = getTime(); fprintf(stdout, "%s: --end (duration: %.10f sec)\n", msMsg.c_str(), (fEndTime-mfStartTime)); } void printTime(int line) const { double fEndTime = getTime(); fprintf(stdout, "%s: --(%d) (duration: %.10f sec)\n", msMsg.c_str(), line, (fEndTime-mfStartTime)); } private: double getTime() const { timeval tv; gettimeofday(&tv, NULL); return tv.tv_sec + tv.tv_usec / 1000000.0; } ::std::string msMsg; double mfStartTime; }; // Use case // //{ // StackPrinter("Time to sleep") sp; // sleep(5000); //}
しかし、この「プリンター」はコンソールへの出力に適しており、LabPlot( LabPlot sourceforge )を使用したその後の分析のためにより便利な出力が必要です。 ここでは、私が悪意を持ってDRYに違反しているので、流血の涙で泣くことができます(これを見ていた人から流血の涙が注がれることがあります。
StackPrinterTiny
class StackPrinterTiny { public: explicit StackPrinterTiny(const char* msg) { mfStartTime = getTime(); } ~StackPrinterTiny() { double fEndTime = getTime(); fprintf(stdout, "%g\n", (fEndTime-mfStartTime)); } void printTime(int line) const { double fEndTime = getTime(); fprintf(stdout, "(%d) %g\n", line, (fEndTime-mfStartTime)); } private: double getTime() const { timeval tv; gettimeofday(&tv, NULL); return tv.tv_sec + tv.tv_usec / 1000000.0; } double mfStartTime; }; #ifdef OutToAnalyze typedef StackPrinterTiny usedStackPrinter; #else typedef StackPrinter usedStackPrinter; #endif // Use case // //{ // usedStackPrinter("Time to sleep") sp; // sleep(5000); //}
フィニッシュラインで
さて、クラフトを組み立てるには、少し「バインディング」コードが必要です-コンパイラを尊重しましょう:
#include <iostream> #include <functional> #include <stdio.h> #include <string> #include <sys/time.h> #include <sys/timeb.h> #include <climits> typedef unsigned long long TCurrentCalculateType; // Closured: result, fiMax // loop, loooop, loooooooop #define LOOP_LOOP(what) \ for(unsigned long long fi = 0; fi < fiMax; ++fi) \ for(unsigned long long fi2 = 0; fi2 < fiMax; ++fi2) \ for(unsigned long long fi3 = 0; fi3 < fiMax; ++fi3) \ result = what int main() { // mulbyNct<> const TCurrentCalculateType calcMeDigit = 9000000; const unsigned long long fiMax = ULLONG_MAX; #ifndef OutToAnalyze std::cout << "Calculate: " << calcMeDigit << " with fiMax = " << fiMax << std::endl; #endif currentCalculateType result = 0; #ifdef CALCULATE_IN_COMPILE_TIME std::cout << "compile time " << calcMeDigit << " * " << calcMeDigit << " = " << mulbyNct<calcMeDigit, calcMeDigit>::result << std::endl; #endif { usedStackPrinter sp("1"); // on image - mulby7 LOOP_LOOP(mulby7(calcMeDigit)); #ifndef OutToAnalyze std::cout << "by x7 = " << result << std::endl; #else std::cout << "=" << result << std::endl; #endif } { usedStackPrinter sp("2"); // on image - mulbyN LOOP_LOOP(mulbyN(calcMeDigit, calcMeDigit)); #ifndef OutToAnalyze std::cout << "x*x where x is " << calcMeDigit << " = " << result << std::endl; #else std::cout << "=" << result << std::endl; #endif } { usedStackPrinter sp("3"); // on image - mulbyNSTL LOOP_LOOP(mulbyNSTL(calcMeDigit, calcMeDigit)); #ifndef OutToAnalyze std::cout << "STL x*x where x is " << calcMeDigit << " = " << result << std::endl; #else std::cout << "=" << result << std::endl; #endif } return 0; } // Compile with // // clear && g++ main.1.cpp -O3 -std=c++0x -o main.1 // PS -Ofast. - .
アセンブリを成功させ、結果を得るために必要なものはすべて揃っています。 収集されている場合(およびそうあるべき)-続行します。
コアが疲れていると思った
ちなみに、私はまだ忘れていません。 コンパイル時に 、498 * 498以上をカウントできませんでした 。つまり、
#if defined(CALCULATE_IN_COMPILE_TIME)
CalcMeDigit = 499(またはそれ以上)を設定すると
#if defined(CALCULATE_IN_COMPILE_TIME)
、コンパイルエラーが発生しました:スタックオーバーフローしませんでしたテンプレートを展開するとき? 私は悔い改め、理解しなかった。 したがって、 実行時にテストに戻ります。数字を与えることは無意味です。 それらはあなたのマシンでは異なります:しかし、額縁で視覚化するために-それはします。 うーん、あなたは流血の涙で泣く方法を忘れ始めました-私は喜んであなたに思い出させます。 以下は、LabPlot'eで詳細な分析と写真の作成のためにファイル内の数値を収集するのに役立つスクリプトです(警告しました)。
main.1.to.out.sh
#/ bin / sh
./main.1> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
#何を期待していましたか? }:->
./main.1> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
./main.1 >> out.txt
#何を期待していましたか? }:->
私のマシンでの結果(Intel®Core(TM)i5 CPU @ 2.8 GHz CPU、8 GiBメモリ):
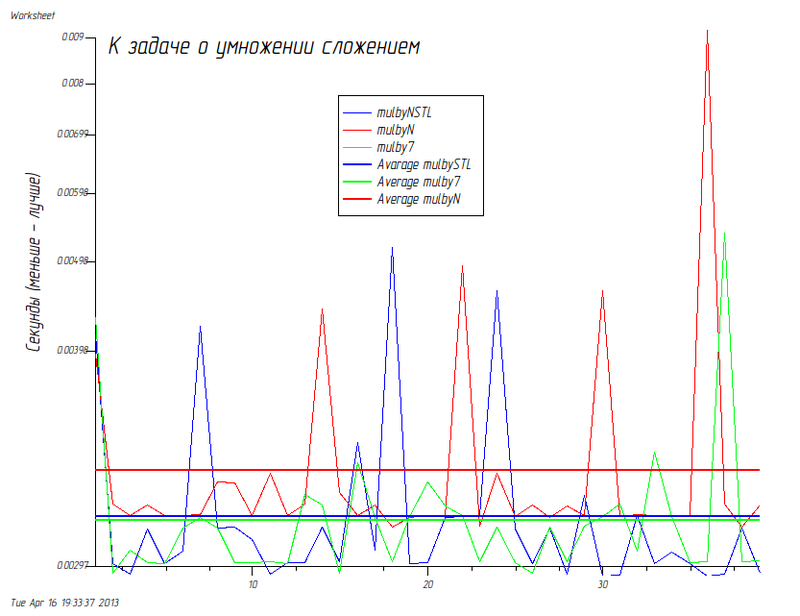
Scott Meyersのヒント43は、「ループの代わりにアルゴリズムを使用する」と述べています。 より広い意味では、アドバイスは、標準のアルゴリズム、コレクション、およびオブジェクトを使用して、より読みやすく、保守しやすく、安全で、時には生産性の高いコードを取得するものとして理解できます。
mulbyNSTL
...ドジャー、あなたは尋ねます(私はすでにこの質問をするのを止めました)、
mulbyNSTL
バリアントの平均時間はその親
mulbyN
よりも
mulbyN
です。 私はまったく真っ直ぐではない手で罪を犯します...しかし、それは何ですか。
最初に私は2番目です
タスク番号2:
ツーインワン。 ある賢い人がエレベーターのボタンを交換しました。 1階の代わりに2階を置き、2階の代わりに1階を置きます。 正直なところ、私はボタンを選ぶのが面倒です。 むしろエレベーターを再プログラムしたいです。 しかし、私はプログラムするのが面倒です。 あなたのすべての希望。 入力2の場合は1、入力1の場合は2を返すスイッチ関数を作成してください。それを熟考して、私はたった1つのソリューションオプションを思いつきました:
- 引数としてフロア番号を受け取る関数は、2を法とするビット単位の加算を実行し、結果を返します。
int worker1(unsigned int n) { return (n xor 3); } // , assert() // #include <assert.h> #ifdef DEGUB assert(worker1(2) == 1); assert(worker1(1) == 2); #endif //DEBUG
int worker2(unsigned int n) { return (n & 1) + 1; } // , assert() // #include <assert.h> #ifdef DEGUB assert(worker2(2) == 1); assert(worker2(1) == 2); #endif //DEBUG
そして、残念なことに、私はこの問題に対するエレガントな答えを見ました(それを生成したもののバージョンによる)。3からフロア番号を引いた結果を返します。
int worker3(unsigned int n) { return 3 - n; } // , assert() // #include <assert.h> #ifdef DEGUB assert(worker3(2) == 1); assert(worker3(1) == 2); #endif //DEBUG
次に、よく知られているスクリプトを使用してデータを収集し(血の涙を忘れることはできません)、これらの小さな関数(worker1、worker2、worker3)の速度をテストするプログラムを作成します。 あなたはすでに私にパターンに対する不健康な渇望を疑っているようです-私はあなたを怒らせるために急いで、これは真実ではありません。 そして、ここに私たちが持っているものはありますか? これは、
std::generate
アルゴリズムでジェネレーターを使用するためのヘルパークラスです。
// Like binder1st // require #include <numeric>, #include <random> template <class Operation, class TRandomEngine> class binderRandom: public std::unary_function <void, typename Operation::result_type> { protected: Operation op; TRandomEngine& y; public: binderRandom ( const Operation& x, TRandomEngine& y) : op (x), y (y) {} typename Operation::result_type operator()() { return op(y); } };
考え方はC ++の世界と同じくらい古いものです。乱数(床数、つまり[1、2])のベクトルを構築し、シーケンスの各要素に対して提案された機能を実行します...合計:
#include <iostream> #include <functional> #include <stdio.h> #include <string> #include <sys/time.h> #include <sys/timeb.h> #include <climits> #include <vector> #include <algorithm> #include <numeric> #include <random> #include <iterator> int main() { static std::mt19937 _randomNumbersEngine; std::vector<unsigned int> _vectorNumbers(50000000); // ? std::uniform_int<unsigned int> uiRandomNumber(1, 2); std::generate(_vectorNumbers.begin(), _vectorNumbers.end(), binderRandom<std::uniform_int<unsigned int>, std::mt19937>(uiRandomNumber, _randomNumbersEngine)); // - // // { usedStackPrinter sp("1"); std::transform(_vectorNumbers.begin(), _vectorNumbers.end(), _vectorNumbers.begin(), worker1); } { usedStackPrinter sp("2"); std::transform(_vectorNumbers.begin(), _vectorNumbers.end(), _vectorNumbers.begin(), worker2); } { usedStackPrinter sp("3"); std::transform(_vectorNumbers.begin(), _vectorNumbers.end(), _vectorNumbers.begin(), worker3); } return 0; }
私のマシンでの結果(Intel®Core(TM)i5 CPU @ 2.8 GHz CPU、8 GiBメモリ):
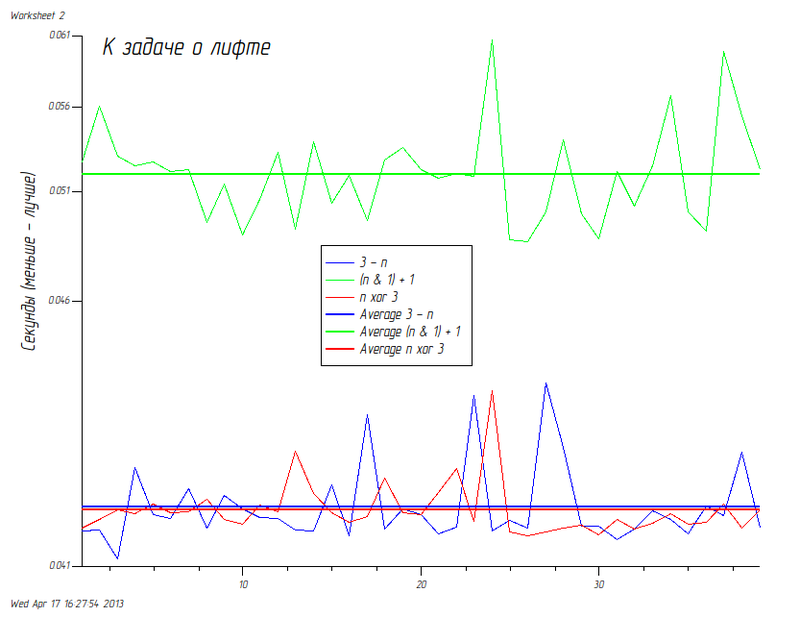
この場合、結果は適切です。両方の(通常の)バージョンが同時に実行されます(差異を測定エラーとしてスローします)。 興味深いことに、生成されたコードを見ると、似ているのでしょうか? これは別の議論のトピックであるため、読者が宿題をすることは残ります。
いずれにせよ、私はこのゴミを扱うのが好きでした。つまり、時間が無駄に費やされていませんでした(個人的な価値判断)。
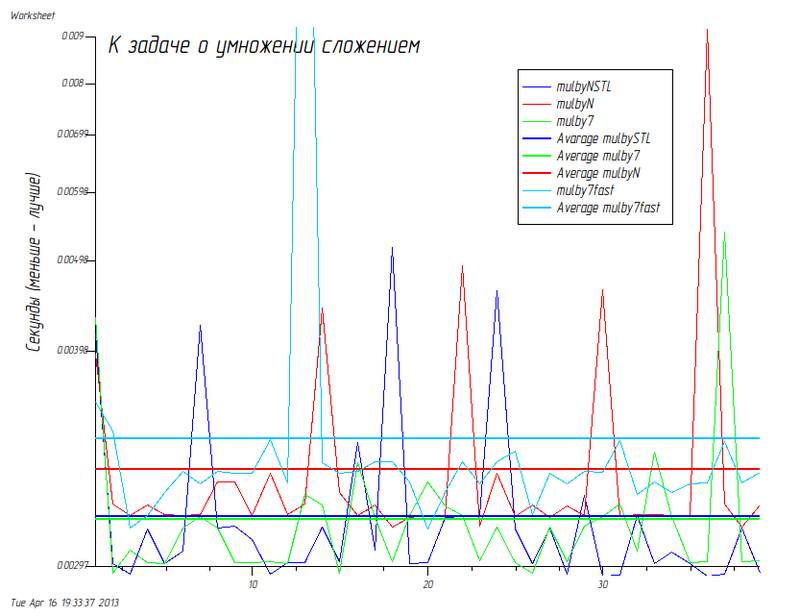
更新:
追加:
inline TCurrentCalculateType mulby7fast(TCurrentCalculateType value) { return (value << 3) - value; }
マシンの結果を更新しました(Intel®Core(TM)i5 CPU @ 2.8 GHz CPU、8 GiBメモリ):
マシンの結果を更新しました(Intel®Core(TM)i5 CPU @ 2.8 GHz CPU、8 GiBメモリ):
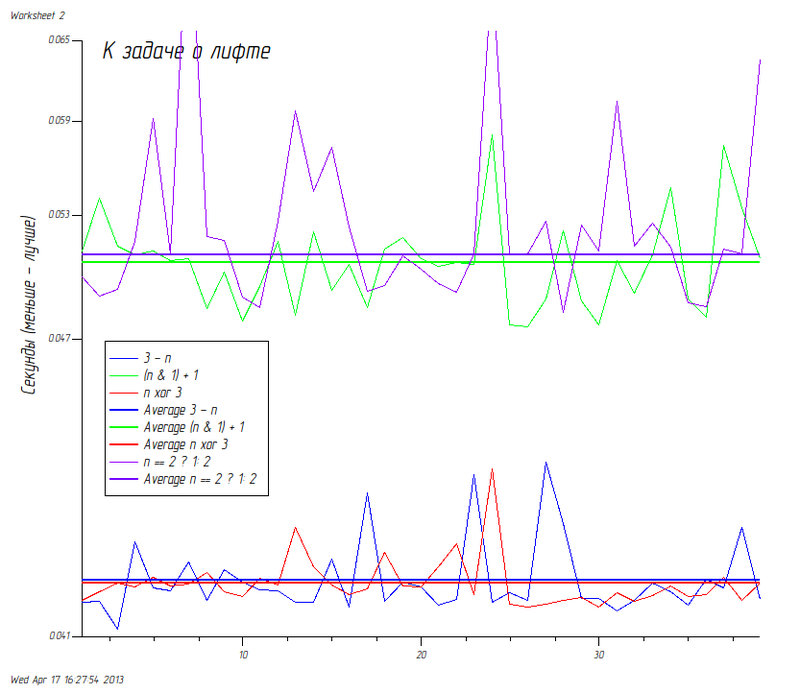
アップデート#2
マイナスとプラスの素晴らしい分布:
- 誰かがどのコンパイラでこれをアセンブルするか知っている場合:
inline float mulby7fast(float value) { return (value << 3) - value; }
- はい、知りませんでした(そして、そのようなものを思い付くことができません):
任意の数による乗算は、ユニティの乗数の位置のシフトの合計として行われます
Googleを使用して学習する-見つけるのではなく、覗き見する。 - 静かな短所-非常に心強い
おわりに
- あらゆる種類のオートコンプリート(Whole TomatoのVisual Assist Xなど)を使用したIDEなしでの書き込みはそれほど難しくありません(明らかに200行以上と単純なロジック)。 はい、巧妙なアライメント、ペアブラケット、引用符がありますが、そこには何かがあります...私に伝えるもの:正しい便利なIDEはクールです!
- バージョンgcc 4.4.5なので、ラムダを使用しませんでしたが、「workerN」の場合はとてもクールに見えます
std::transform(_vectorNumbers.begin(), _vectorNumbers.end(), _vectorNumbers.begin(), [](int n) { return n xor 3; } );
そのようなこと。 ご清聴ありがとうございました!
PSエラーまたはタイプミス。PMにご記入ください。