
たとえば、 Phil Rosenzweigの著書「The Halo Effect ...およびマネージャーを誤解させる他の8つの幻想」。異なる店舗での537から885ルーブルのコスト。 その違いは非常に重要です。
アイデアから結果までさらに...
書籍リクエストの例:
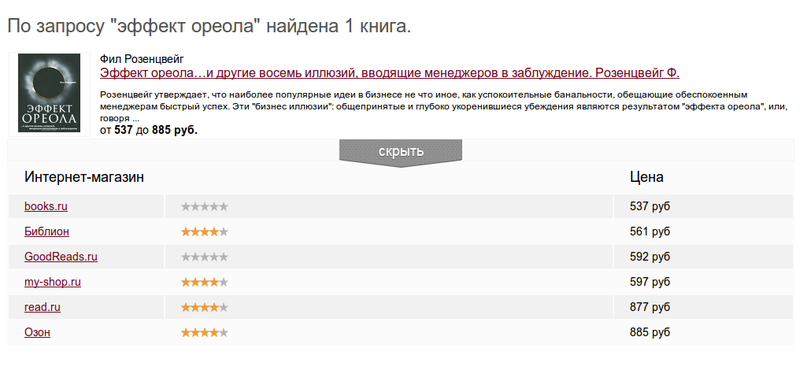
アイデア
私は本を読むのが好きで、よく買う。 正直に言うと、読む時間よりも頻繁に購入します。 私がそれらに着く前に、いくつかの本は私の棚に3年間横たわるかもしれません。 Kindle PaperwhiteとNook Simple Touchリーダーがあり、コンピューターであらゆる種類のpdfの本をたくさん読んでいます。 間違いなく、電子書籍には利点があります-暗闇の中ですぐに購入して読むことができますが、それでも紙のほうが好きです。
2012年11月中旬、オンラインコース「MongoDB for Developers」にサインアップしました。 開始から数週間が経過しました。 私はまだMongoDBのすべての機能を理解していませんでしたが、このテクノロジーはすでに気に入っていました。 実際に新しい知識を何らかの形で適用したいという要望がありました。 そして、本の検索サイトを作成するというアイデアを得ました。
その時点で私はすでにそのようなサイトを見ましたが、正直なところ、それはあまり便利ではなく、常に信頼できる結果を与えませんでした。 他のサイトを探す価値はあったかもしれませんが、その時点では私はしませんでした。 私は自分のサイトを立ち上げた後、他のサイトを見始めました。 彼らは私が予想していたよりもはるかに多いことが判明しました。 このようなサイトは12を超えています。 しかし、これはまったく気にしませんでした。 より便利な検索をユーザーに提供できます。将来的には、より正確で幅広い検索を希望します。 そして一般的にはアイデアの不足はありません)
実装
最初は、計画を達成するのに数日間の休みで十分であると決めましたが、よくあることですが、もっと時間がかかりました。 仕事では、私はDjangoを使用していますが、率直に言って、彼女と一緒に働いて数年の間、彼女は私を幾分退屈させました。 Djangoは素晴らしいフレームワークですが、私は何か新しいものが欲しかったので、Flaskでプロジェクトを行うことにしました。 なぜ正確にフラスコですか? ランダムな友人が、Flask + mongoDBのブログ作成チュートリアルへのリンクを投げ捨てて、彼のプロジェクトで長期間Flaskを使用していたと言いました。 試すのは面白かったです。

私は妻にデザインを描くように頼みました(Polinaこんにちは!)。デザインはできるだけシンプルで、影やグラデーションなしで必要であることを指定しました。 当時、これによりレイアウトの時間を節約でき、変更が簡単になりました。
1か月が経ちました...正直に言って、プログラミングに専念するために夕方と週末に非常に疲れており、私の熱意は急速に失われていました。 私は緊急に実在の人々からのフィードバックを必要としていました。 私は最小限の作業形式でプロジェクトを投稿しました。 このプロジェクトはすでに機能しており、店で本を探していましたが、多くの小さなバグや欠陥に悩まされました。 これはすべて、最初のバージョンの計算を高速化するために意図的に行われました。 エラー処理404や500などの基本的なものさえありませんでした。あらゆる種類の履歴APIは言うまでもありません。
同僚から肯定的な評価を受けた私は、仕事を続けたいと思いました。 次の月は、これらの非常に小さな妨害で、主にファイナライズに費やされました。
さらに、実際のデータは最初に準備していたものとは一致しないことが判明しました。 データベース内のドキュメントのレイアウトを変更し、コレクションを分離し、アルゴリズムを変更する必要がありました。
実際のデータでは、多くのジョークがあります。 たとえば、ISBNは書籍の一意の識別子になる可能性があると計算しました。 実際、そうではありませんでした。 1つの本に多くのISBNを含めることができます。 店内の誰がデータベースを埋めているのかわかりませんが、ISBNが無効になるだけでなく、ISBNの代わりに、任意の数字からロシア語の一部のフレーズまで何でも地獄に落ちる可能性があります。 数字のゼロの代わりに、記号「O」が詰まることがあり、英語の「Ex」の代わりにロシア語の「Ha」があります。
さらに、2つの完全に異なる本に1つのISBNが含まれている場合があります。 理論的には、これは不可能です。 出版社はいくつかの本をバンドルしています。 たとえば、2つの異なる本のISBNと2つの異なる本の著者が、そのような本に表示されます。
そして、パフォーマンスの問題に遭遇しました。 Pythonは、他の動的言語と同様に、私たちが望むほど速く動作しません。 Webアプリケーションの場合、原則としてこれは重要ではありません。 サイトの速度が低下すると、データベース、ディスク操作、またはネットワークの速度が低下します。 私は長い間コードのプロファイルを作成し、アルゴリズムを最適化しました。 アルゴリズムは正常であり、Pythonとデータベースの速度が低下するという結論に達しました。
プロジェクトのかなりの部分を、明らかに静的型付けを使用して、より高速な言語で書き直す必要がありました。 そのため、これまで未知のプログラミング言語であったScalaがプロジェクトに登場しました)
なぜScala自体ですか? C、C ++、Scalaから選択しました。 最初のセグメンテーションフォールトにより、このリストからCを削除する必要がありました。 Cは良い言語ですが、明らかにこのタスクには最適ではありません。 もちろん、言語のパフォーマンステストを見ましたが、正直なところ、Java / Scalaの速度がC ++の速度に近いとは信じていませんでした。 そこで、パフォーマンステストを作成しました。 パーサーの一部を取り、Python、Scala、およびC ++で実装を作成しました。
parsig 1.5 GBファイルの結果は次のとおりです。
CPython 4分12秒
PyPy 2分48秒
スカラ57秒
C ++ 47秒
アルゴリズムはどこでも同じで、解析には文字列操作のみが使用されます。 また、Scalaは標準のXMLパーサーを使用しようとしましたが、動作はずっと遅くなりました。
ご覧のとおり、Scalaの速度は非常に優れています。 また、Scalaの作成とデバッグが簡単になりました。 さらに、混乱が生じた場合に相談できる人がいました(Ivan hi!)。
Scalaでコードを書くとき、「このコードは間違っているように見えるので、正しく行う方法を理解する必要がある」と思うことがよくありました。 このような完全主義は、開発を著しく遅らせる可能性があります。 「おい、この言語を知らないので、すぐに書くことはできないので、それを機能させるために書いてください!」 「仕事をする」ことを自分に強制することは心理的に困難でした。私は「美しく」やりたいと思いました。 しかし、最終的に、私は自分自身をまとめて「仕事をする」と書きました。
TDD 最初から、すべてのパーサーはPythonおよびScalaのテストでカバーされていました。 これは、テストがすぐに開発を加速する場所です。 一方、まだ試用版はありません。
収益化
ローンチ後の最初の日、同僚が検索を有料にする時期を尋ねました。 そして、私はそれをするつもりはありませんでした。 収益化はシンプルで簡単です-店舗のアフィリエイトプログラム。 広告を掲載する予定はありません。
プレゼント
現在、スタートアップに存在する多くの欠点はすでに修正されていますが、まだかなりの量は存在しています。 直面しなければならない興味深いタスクの1つは、さまざまなソースからの本の接着です。 接着アルゴリズムはすでに非常にうまく機能していますが、それでも時々クラッシュします。 これに遭遇したら、私に手紙を書いてください。
フロントエンドはPython / Flaskで記述され、バックエンドはScalaで記述され、MongoDBがベースです。
今後の計画
多くのアイデアがありますが、近い将来、検索の品質と小さな欠陥の修正に取り組む予定です。 新機能はクールで、確かに登場しますが、少し後になります。 ところで、コメントは表示される順序に影響を与える可能性があります。
あなたが私のサービスを楽しんでくれたことを願っています、
アドバイス、批判、提案を大いに感謝します。
入ってきてください-www.bookradar.org !