だから、まず患者の診断。 クライアントアプリケーションを備えたITシステムが開発されています。 システムは、AmazonクラウドでEC2サービスとしてホストされているサーバーです。 このサーバーは、RDS(リレーショナルデータベースサービス)サービスと同じ地域(米国西部)にあるMySQLデータベースと対話します。 モバイルアプリケーションはサーバーと対話し、サーバーはサーバーを介して登録し、データをダウンロードします。 このアプリケーションの動作中に、通信エラーが頻繁に観察されます。アプリケーションは、接続エラーという単語を含むポップアップを表示します。 同時に、ユーザーはアプリケーションの動作が遅いことを訴えます。 この状況は、米国とロシアの両方のユーザーで発生します。
システム全体を独立したホスティング(最も一般的で安価なもの)に転送すると、アプリケーションの動作が著しく速くなり、Amazon RDSの遅延が発生しなくなりました。 さまざまなフォーラムでの検索では、この動作の理由に関する回答は得られませんでした。
アプリケーションとサーバーおよびデータベース間の対話プロセスの時間特性を収集するために、MySQLデータベースに10回連続でクエリを実行するスクリプトが作成されました。 クエリキャッシングの状況を排除するために、SQL_NO_CACHEステートメントがクエリに追加されました。 ただし、データベースはそのようなSELECTクエリをキャッシュしません。 要求とその継続時間の測定は、ネットワーク遅延を考慮してトランザクションの継続時間を測定する次の機能によって実行されます。
function query_execute ($link) { $time = microtime (true); $res = mysqli_query ($link, «SELECT SQL_NO_CACHE ui.* FROM `user_item_id` ui INNER JOIN `users` u ON u.`user_id`=ui.`user_id` WHERE u.`username`='any@user.com';»); return array («rows» => mysqli_num_rows ($res), «time» => sprintf («%4f», microtime (true) — $time)); }
このスクリプトはロシアのホスティングにアップロードされ、起動されました。 結果は次のとおりです(スクリプト-ロシア、DBMS-Amazon RDS、カリフォルニア)。
AWSメジャーの開始時間
行:10、期間:2.659313
行:10、期間:0.594934
行:10、期間:0.595982
行:10、期間:0.594558
行:10、期間:0.397052
行:10、期間:0.399988
行:10、期間:0.399615
行:10、期間:0.396856
行:10、期間:0.399138
行:10、期間:0.396113
-平均所要時間:0.6833549
比較のために-同じことですが、異なるホスティングサイトから-フランスで(スクリプト-フランス、DBMS-Amazon RDS、カリフォルニア)。
AWSメジャーの開始時間
行:14、期間:1.980444
行:14、期間:0.472865
行:14、期間:0.318233
行:14、期間:0.417172
行:14、期間:0.342588
行:14、期間:0.303614
行:14、期間:0.908241
行:14、期間:1.809397
行:14、期間:0.497458
行:14、期間:0.316923
-平均期間:0.7366935
この状況は非常に驚くべきものであり、SQLクエリのキャッシュに関する参照情報を詳しく調べました。 しかし、すべての研究は一つのことを言った-スクリプトが正しく書かれていた。 状況は興味深いです。 すべてが理解できるように思えますが、非常に小さなことは明確ではありません。a)何が起こっているのか、b)少なくともサポートのリクエストを作成する方法は?
いいね 次の実験は、カリフォルニアの同じAmazonデータセンターのサーバーでこのスクリプトをローカルで実行することです。 確かにサーバーは物理的に近くにあり、すべてが非常に迅速に発生するはずです。 試します(スクリプトとDBMS-Amazon AWS、カリフォルニア)。
AWSメジャーの開始時間
行:10、期間:0.024818
行:10、期間:0.009796
行:10、期間:0.006747
行:10、期間:0.005163
行:10、期間:0.007998
行:10、期間:0.006088
行:10、期間:0.009614
行:10、期間:0.007938
行:10、期間:0.008052
行:10、期間:0.007804
-平均期間:0.0094018
遅延は大幅に減少しましたが、全体像は同じです-最初の要求は次の要求よりも何倍も長く実行されます。 そして、これが最終アプリケーションのすべての問題の理由だと思います。 結局、アプリケーションは「1回の要求で」サーバーと情報を交換します。これはまさにこの最長の操作です。 したがって、アプリケーションの「禁止」全体を決定するのはこの操作です。
干渉しているものを確認するために、データベースはAmazon RDSから別のホスティング(最も安価な)に移行されました。 そして、ここでちょっとした驚きが待っていました-最初のトランザクションと後続のトランザクションの速度が同じです(スクリプト-ロシア、DBMS-米国での低コストホスティング)。
リノード測定の開始時間
行:10、期間:0.018506
行:10、期間:0.017285
行:10、期間:0.011917
行:10、期間:0.011928
行:10、期間:0.027923
行:10、期間:0.011141
行:10、期間:0.072708
行:10、期間:0.011934
行:10、期間:0.007816
行:10、期間:0.008045
-平均期間:0.0199203
私は少し気が散っています-最良の状況は、一般的にサーバー自体がこの弱いホスティングにインストールされたときでした(スクリプトとDBMSは、米国で同じ安価なホスティングです)。
リノード測定の開始時間
行:10、期間:0.008159
行:10、期間:0.000344
行:10、期間:0.000317
行:10、期間:0.000309
行:10、期間:0.000269
行:10、期間:0.000282
行:10、期間:0.000260
行:10、期間:0.000263
行:10、期間:0.000303
行:10、期間:0.000297
-平均期間:0.0010803
ここでも同様の状況を見ることができますが、ミリ秒単位で、ネットワークではなくOSの遅延がすでに有効になっています。 したがって、これに注意を払うべきではありません。
しかし、私たちの状況に戻りましょう。 実験の純度を高めるために、彼らは別のテストを行いました。AmazonRDSでこの安価なホスティングからスクリプトを起動しました。 その結果、やはり最初のトランザクションが長くなります(スクリプト-米国ホスティング、DBMS-Amazon RDS、カリフォルニア)。
AWSメジャーの開始時間
行:10、期間:0.098134
行:10、期間:0.016168
行:10、期間:0.011697
行:10、期間:0.007868
行:10、期間:0.008148
行:10、期間:0.010468
行:10、期間:0.033403
行:10、期間:0.011947
行:10、期間:0.012217
行:10、期間:0.008185
-平均期間:0.0218235
私もインターネットの開発者も、そのような奇妙なものに類似するものを見つけることができませんでした。 しかし、その間、これらの数字を見て、状況がITシステムの設定ではなく、Amazonデータセンターを接続するIPトランスポートネットワークのデータ転送の特性に起因しているという漠然とした疑念を抱き始めました。
以下の考慮事項は単なる私の仮定であり、上記のタイミングは非常に論理的です。 しかし、私はこれに完全な自信を持っておらず、多分大きな遅延の理由は異なっていて、それらは浮いているように見えます。 別の意見を聞くのは面白いでしょう。
したがって、電気通信の世界では、すべての通信ネットワークの基礎は、IPプロトコルによって形成されるトランスポート層です。 多くの中間ルーターを介してIPパケットを送信するには、一般にルーティングとスイッチングの2つの方法が使用されます。
ルーティングとは何ですか? 4つのネットワークノードがあるとします。 最初から2番目に、IPパケットが送信されます。 ノード3または4にどこに転送するかを決定する方法は? ノード2はルーティングテーブル内を検索し、宛先アドレス(イーサネットポート)を検索し、図のノード4(アドレス48.136.23.03)にパケットを送信します。
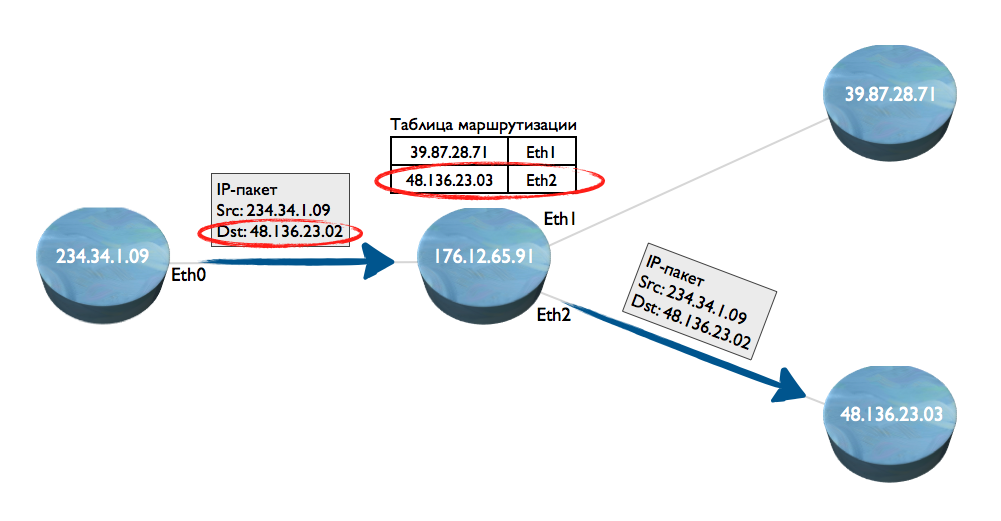
この方法の欠点は、次の理由によるパケットルーティング速度の低さです:a)数百万のIPパケットを解析してアドレスを抽出する必要がある、b)IPアドレスがイーサネットネットワークインターフェース番号に対応するデータベース(ルーティングテーブル)で各パケットを実行する必要がある
Tier 1オペレータクラスの大規模ネットワークでは、これには信じられないほどのプロセッサリソースが必要ですが、それでも各ルーターには遅延が発生します。
これを避けるために、MPLS(マルチプロトコルラベルスイッチング)テクノロジーが発明されました。 一般的な用語では、パケット交換。 彼女はどのように働いていますか? 最初のパケットの送信が開始されたとしましょう。 ノード1で、IPアドレスを介して、ラベルがパケットに追加されました。 ラベルは、プロセッサによって簡単かつ迅速に処理される4バイトの整数です。 このようなパケットはノード2に到達しました。ノード2は、ルーティングテーブルを使用して、上記の方法でノード3に送信することを決定します。同時に、ノード2にテーブルが作成されます。
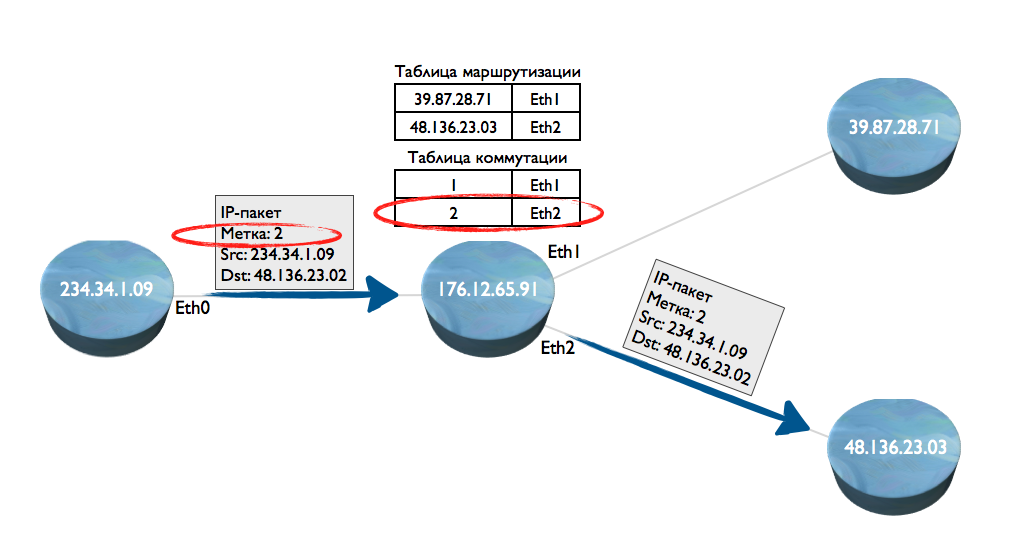
さらに、ノード1は2番目のIPパケットを送信し、最初のIPパケットに設定されたのと同じラベルを追加します。 このようなパケットがノード2に到着すると、ノードはIPアドレスを処理しなくなり、ルーティングテーブルで探します。 すぐにラベルを抽出し、そのための出力インターフェイスがあるかどうかを確認します。
実際、各中間ノードでのこのようなスイッチングテーブルの構築により、ルーティングテーブルを使用せずに、さらにデータ伝送が実行される「トンネル」が構築されます。
この方法の利点は、ネットワークの待ち時間が大幅に短縮されることです。
そして今、主なもの...
マイナス-最初のパケットはルーティング方式で送信され、その背後にラベルの「トンネル」を構築します。次のパケットのみがすでに迅速に送信されています。 上で観察しているのはこの写真です。 安価なホスティング事業者がMPLS機器を所有している可能性はほとんどありません。 その結果、最初のリクエストと後続のリクエストの期間が同じになります。 しかし、Amazonでは、MPLSプロトコルはそれ自体を明示しているように見えます-最初のリクエストの送信には、後続のリクエストよりも3〜5倍時間がかかります。
これがまさにアプリケーションとデータベースとの不安定で長時間の相互作用の理由だと思います。 ただし、データベースとのやり取りがより激しい場合は、おそらく3〜4回のリクエストの後、Amazonが安価なホスティングを追い越します。 私の特定のケースでは、データ転送を大幅に高速化するように設計された技術がシステム全体の不安定な動作につながることは皮肉です。
このバージョンを実際のバージョンと見なすと、疑問が生じます。他のバージョンはどうですか? 結局のところ、大規模な顧客であるソーシャルネットワークはAmazonで機能し、そのような問題は発生しません。 公正な質問。正確な答えはありません。 ただし、いくつかの考慮事項があります。
- 私が書いているアプリケーションは現在バージョン1.0です。 ほとんどの場合、そして確かに、今では次善のデータベースクエリ構造があります。 将来的には最適化され、これにより速度が向上します。 しかし、今では、一方が他方と重なっているようです。
- 大規模なソーシャルネットワークがAmazonに基づいていると仮定すると、まだ奇妙です。 ほとんどの場合、このようなシステムのアーキテクチャは地理的に分散しており、情報はAmazonデータセンターに非同期的にのみ集まります。 少なくとも、モスクワのFacebookからのトレースでは、アイルランドのサーバーがエンドポイント、Twitter(独自のサイト、Pinterest)がTeliaネットワークなどにあることが示されています。
- ソーシャルネットワークの大規模なノード間には、静的ルートが事前にインストールされている可能性があります。
いずれにせよ、私は状況について他の説明はありません。
しかし、解決策があります。 3週間前、システムはOVHホスティングプロバイダーのカナダの専用サーバーに移行されました。 この問題は解決されました。すべてが著しく高速に動作し、接続エラーは他の誰にも見られませんでした。