
比較に興味がある場合は、最後になりますが、ここでは、Mongoでテキストインデックスを作成する方法と、それで何ができるかを説明します。
以前は、mongでテキストを検索するために、正規表現を使用するか、自分で作成した単語付きの配列を使用できました。 正規表現検索の主な欠点は、すべてのクエリでインデックスを効果的に使用できず、重要な正規表現を書くのが難しいことです。 インデックスは、正規表現から行の先頭や他のいくつかのケースで何かを見つけるように指示されたときによく使用されました。 文を分割した後に得られた単語の配列から作成されたインデックスを持つ別のオプションは、この欠点を回避しましたが、便利ではありませんでした。
これで、迅速なテキスト検索を行うために何もする必要はまったくありません。 テキストインデックスを作成し、リクエストを行うと、システム自体がワードストップを削除し、トークンを作成し、結果の関連性を示す数値特性をスタンプし、付加します。 ステミングには、ポーターステマーが使用されます。 ストップワードのリストはgithubで表示できます- たとえば、ロシア語の場合 。
サポートされている言語のリスト:
デンマーク人
オランダ人
英語
フィンランド語
フランス人
ドイツ人
ハンガリー人
イタリア人
ノルウェー人
ポルトガル語
ルーマニア人
ロシア人
スペイン語
スウェーデン人
トルコ人
オランダ人
英語
フィンランド語
フランス人
ドイツ人
ハンガリー人
イタリア人
ノルウェー人
ポルトガル語
ルーマニア人
ロシア人
スペイン語
スウェーデン人
トルコ人
あなたが得ることができる結果から始めましょう:
db.text.runCommand( "text" , { search: "",project:{text:1,_id:0},limit: 3 } )
結果
{ "queryDebugString" : "||||||", "language" : "russian", "results" : [ { "score" : 1, "obj" : { "text" : " ; " } }, { "score" : 0.85, "obj" : { "text" : " ; " } }, { "score" : 0.8333333333333334, "obj" : { "text" : " , , - , , " } } ], "stats" : { "nscanned" : 168, "nscannedObjects" : 0, "n" : 3, "nfound" : 3, "timeMicros" : 320 }, "ok" : 1 }
ご覧のとおり、Mongoは単語「sword」が最も頻繁に見つかった文と、単語「sword」の末尾が変更された文を見つけました。
テキスト検索を接続する
テキスト検索はテストモードのままなので、起動時に対応するmongodオプションを明示的に指定する必要があります。
mongod --setParameter textSearchEnabled=true
テキストインデックスを作成する
インデックスを作成するメインコマンド:
db.collection.ensureIndex( {subject: "text", content: "text"} )
その後、選択したコレクションの件名およびコンテンツフィールドのすべてのテキストにインデックスが付けられます
デフォルトでは、英語のインデックスが作成されます。これを変更するには、default_languageオプションを設定する必要があります。
db.collection.ensureIndex( { content : "text" }, { default_language: "russian" })
ドキュメントの指定されたフィールドで指定された言語を各ドキュメントに適用するインデックスを作成することも可能です- ドキュメント
ドキュメント内のすべてのフィールドを検索するインデックスを作成することもできます。
作成時に指定されたフィールドの重みに応じて結果の重みを計算するインデックスを作成するコマンド:
db.blog.ensureIndex( {content: "text",keywords: "text", about: "text"}, {weights: { content: 10,keywords: 5, },name: "TextIndex" })
インデックスの作成の詳細をご覧ください。
検索クエリの実行
テキスト検索を実行できる新しいコマンド「text」が追加されました。
db.collection.runCommand( "text", { search: "" } )
「テキスト」はコマンド、「剣」は検索語
検索のためにスペースを使用して複数の単語を指定した場合、それらは論理OR演算子(論理ANDなしのオプション)によって結合されます
特定の単語または表現と完全に一致するものを見つけるには、それを引用する必要があります。
db.quotes.runCommand( "text", { search: "\" \"" } )
結果から特定の単語を含むテキストを除外する必要がある場合は、クエリでこの単語の前に「-」を置くだけで十分です。次に例を示します。
db.quotes.runCommand( "text" , { search: " -" } )
結果の数の制限は、制限オプションによって設定されます。
db.quotes.runCommand( "text", { search: "tomorrow", limit: 2 } )
返されるフィールドは、プロジェクトオプションで指定されます。
db.quotes.runCommand( "text", { search: "tomorrow", project: { "src": 1 } } )
特定のフィールドを持つドキュメントを検索するには、フィルターオプションを設定する必要があります。
db.quotes.runCommand( "text", { search: "tomorrow", filter: { speaker : "macbeth" } } )
詳細
結果の解析
検索結果を考慮してください。
ブラケットの一部が切り取られています
{ "queryDebugString" : "||||||||", "language" : "russian", "results" : "score" : 1.25, "obj" : { "text" : "- " "score" : 0.9166666666666667, "obj" : { "text" : " , " "score" : 0.8863636363636365, "obj" : { "text" : " … - " "stats" : { "nscanned" : 145, "nscannedObjects" : 0, "n" : 3, "nfound" : 3, "timeMicros" : 155 }, "ok" : 1 }
ここに:
queryDebugString-ドキュメントはそれが何であるかを述べていませんが、おそらくこれらはステミング後の単語です
language-検索に使用された言語
結果-結果のリスト
スコア-要求が結果とどの程度正確に一致するかを示す特性
統計辞書-追加情報
nscanned-インデックスを使用して見つかったドキュメントの数
nscannedObjects-インデックスを使用せずにスキャンされたドキュメント(このパラメーターは小さいほど良い)
nは返された結果の数です
nfound-一致の数
timeMicros-検索期間とマイクロ秒
詳細
テキスト検索vs $正規表現+インデックス
db.text.runCommand( "text" , { search: "",project:{text:1,_id:0}} ).stats { "nscanned" : 77, "nscannedObjects" : 0, "n" : 77, "nfound" : 77, "timeMicros" : 153 } db.text2.find( { text: { $regex: ''} }).explain(); { "cursor" : "BtreeCursor text_1 multi", "n" : 5, "nscannedObjects" : 5, "nscanned" : 15821, "nscannedObjectsAllPlans" : 5, "nscannedAllPlans" : 15821, "indexOnly" : false, "millis" : 31, "indexBounds" : { "text" : [["",{}], [ //, // ] ] }, }
textテーブルとtext2テーブルは同じです:
彼らの統計
> db.text.stats()
{
「Ns」:「text_test.text」、
「カウント」:15821、
「サイズ」:3889044、
「AvgObjSize」:245.8153087668289、
「StorageSize」:6983680、
「NumExtents」:5
「インデックス」:2
「LastExtentSize」:5242880、
「PaddingFactor」:1
「SystemFlags」:0、
「UserFlags」:1
「TotalIndexSize」:7358400、
「IndexSizes」:{
「_id_」:523264、
「Text_text」:6835136
}、
「OK」:1
}
> db.text2.stats()
{
「Ns」:「text_test.text2」、
「カウント」:15821、
「サイズ」:2735244、
「AvgObjSize」:172.8869224448518、
「StorageSize」:5591040、
「NumExtents」:6
「インデックス」:2
「LastExtentSize」:4194304、
「PaddingFactor」:1
「SystemFlags」:0、
「UserFlags」:0、
「TotalIndexSize」:3008768、
「IndexSizes」:{
「_id_」:523264、
「Text_1」:2485504
}、
「OK」:1
}
違いは異なるインデックスによるもので、データはまったく同じです
{
「Ns」:「text_test.text」、
「カウント」:15821、
「サイズ」:3889044、
「AvgObjSize」:245.8153087668289、
「StorageSize」:6983680、
「NumExtents」:5
「インデックス」:2
「LastExtentSize」:5242880、
「PaddingFactor」:1
「SystemFlags」:0、
「UserFlags」:1
「TotalIndexSize」:7358400、
「IndexSizes」:{
「_id_」:523264、
「Text_text」:6835136
}、
「OK」:1
}
> db.text2.stats()
{
「Ns」:「text_test.text2」、
「カウント」:15821、
「サイズ」:2735244、
「AvgObjSize」:172.8869224448518、
「StorageSize」:5591040、
「NumExtents」:6
「インデックス」:2
「LastExtentSize」:4194304、
「PaddingFactor」:1
「SystemFlags」:0、
「UserFlags」:0、
「TotalIndexSize」:3008768、
「IndexSizes」:{
「_id_」:523264、
「Text_1」:2485504
}、
「OK」:1
}
違いは異なるインデックスによるもので、データはまったく同じです
結果からわかるように、正規表現検索は31ミリ秒で完了し、テキストインデックス検索は151マイクロ秒で完了しました。これは200倍少ないです。
MongoDB対Sphinx
比較は、Ubuntu 12.10 OS(Core i5、8GB RAM、ハードドライブ(RAIDなし))で実行されました。 候補:MongoDM 2.4.1およびSphinx 2.0.6。 MongとMysqlでは、フォームid、テキストのテーブルが作成されました。 テーブルは同一で、1600万件のレコードが含まれていました。 Mongでテキストインデックスが作成されました。 テキスト検索のインデックスもスフィンクスで構成され、ストップワードシートとステミングアルゴリズムを使用するためのオプションが追加で含まれました。 競技者とやり取りするために、Pythonクライアントが使用されました-sphinxapiとpymongo。
テストは、テーブル内で千の単語を見つけることでした。 それは「ウォーミングアップ」といくつかの繰り返し実行を実行しました。 スフィンクスでは、ステミング、ストップワード、および利用可能なメモリの増加を除いて、追加の設定は含まれていません。 プログラムのメモリ使用量はほぼ同じで、2.2 GBはSphinxを使用し、2.5 GBはMongoを使用しました。
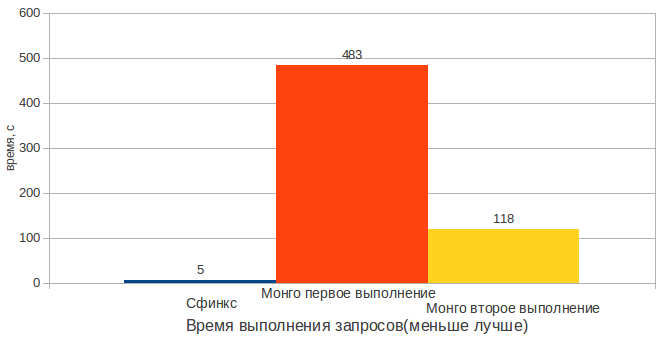
結果からわかるように、Mongoは負けています。 OPの特定の作業により、Mongoは最初の検索よりも2回目の検索を高速化します。 これは、Mongoが要求されたデータのみをメモリに保存するためです。 最初のテスト実行では、インデックスはまだメモリにロードされていません。 ただし、インデックスが忙しい場合でも、Mongoは20倍以上遅くなります。
小さなテーブルを検索する場合、ギャップは狭くなりますが、それでもSphinxの10倍の利点があります。
また、Mongのテキストインデックスは、インデックス付きデータの約2倍のメモリを使用して自身を保存することにも注意してください。
おわりに
テキストの検索に大きなマージンがあり、Sphinxが勝ちます。
Mongoの防衛では、次のように言えます。
- mongoには、テキスト検索以外にも多くの機能があります
- 生産性を向上させながら、水平方向に簡単にスケーリングできます
- テストモードのままのテキスト検索
- Mongoのテキスト検索はSphinxの場合よりも簡単で、勉強するのに数時間もかかりません
新しいMongoDB機能は、データストレージの分野で電力のバランスを大きく変えることはありません。