私たちはどこに、私たちは誰で、パーサーはどこにいるのでしょうか?
この図は、検索サービスの構造を示しています。 システムが動作する部分はピンク色で強調表示されています。

図 1.検索における私たちの場所
フロントエンドは、リクエストを入力するためのフォームをユーザーに提供します。準備が整うと、リクエストはMetaSMに送信され、そこでQuery Parserに送られて、分析と分類が行われます。 次に、追加のパラメータで強化されたリクエストは、ツリーの形式でバックエンドに転送されます。このツリーに基づいて、リクエストに対応するデータがインデックスから抽出され、最終ランキング処理に転送されます。
リクエストが検索システムに送信される前に、さらに2つのコンポーネントによって処理されます。 1つ目はsajestです。これは、ほぼすべてのキーストロークに応答するサービスで、彼の意見では、リクエストを継続するためのオプションを提供します。 2番目はスペルチェッカーで、送信後にリクエストが送信されます。タイプミスのリクエストを分析します。
ナビゲーションベースは、機能に基づいて個別に描かれています。 実際、クエリパーサーに統合されていますが、それについては後で詳しく説明します。
クエリのクラスと種類
リクエストの分類と予備分析が必要なのはなぜですか? その理由は、クエリクラスごとに異なるデータ、異なるランキング式、結果の異なる視覚的表現が必要だからです。
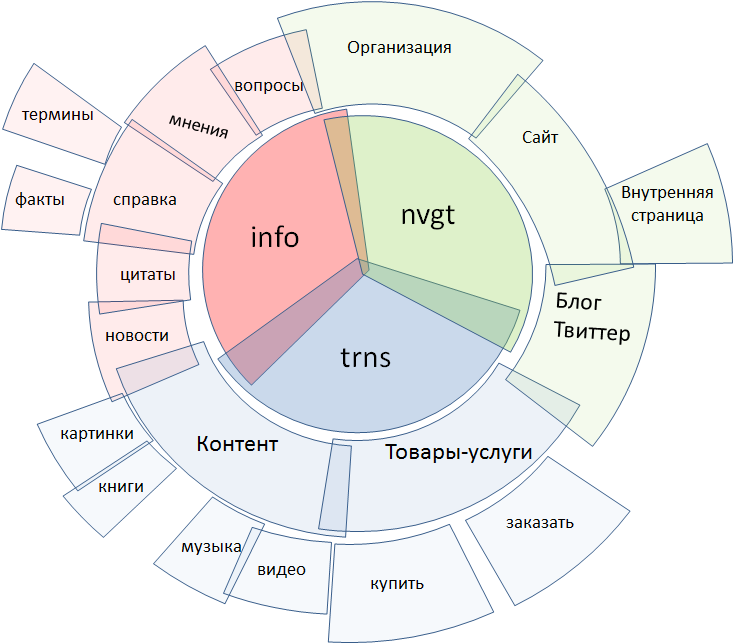
図 2.リクエストの種類
従来、すべての検索クエリは3つのクラスに分けられます。
●情報
●ナビゲーション
●トランザクション
それらはそれぞれ、さらに小さなクラスに分割されます。 この図は完全なふりをしているわけではありません。クエリのセット全体をセグメント化するプロセスは、実際にはフラクタルです。むしろ、忍耐とリソースの問題です。 ここには、最も基本的な要素のみがリストされています。
トランザクションリクエストには、インターネットに含まれるコンテンツの検索、オフラインのオブジェクト、つまり、さまざまな商品やサービスの検索が含まれます。 ナビゲーションクエリ-明示的に指定されたサイト、ブログ、マイクロブログ、個人ページ、組織を検索します。 情報提供は、意味の面で最も広範なクエリのクラスであり、他のすべてが適用されます。ニュース、事実と用語のヘルプクエリ、意見とレビューの検索、質問への回答など。
すぐに、1つのリクエストに複数のクラスの属性が一度に含まれることが多いことに注意してください。 したがって、分類とは、リクエストの一部が該当する各セルにツリー構造を作成することではなく、タグ付け、つまりリクエストに追加のプロパティを付与することです。
トピックの配布

図 3.さまざまな要求クラスの頻度分布
さまざまなクエリクラスのサイズを見積もると、少数のクラスにクエリストリームの大部分が含まれており、その後にクエリストリームフラグメントの減少する長いテールが続くことがわかります。 トピックが狭いほど、その要求は少なくなり、そのようなトピックは多くなります。
実用的な観点から、これは、すべてのリクエストを完全に分類しようとするのではなく、リクエストの一般的なストリームから最も重要なものをピンチオフしようとすることを意味します。 原則として、クラスを選択するための基準はその頻度ですが、それだけでなく、効率的に処理できる要求である可能性があり、結果を視覚化することなどが興味深いです。
パーサーのアーキテクチャ
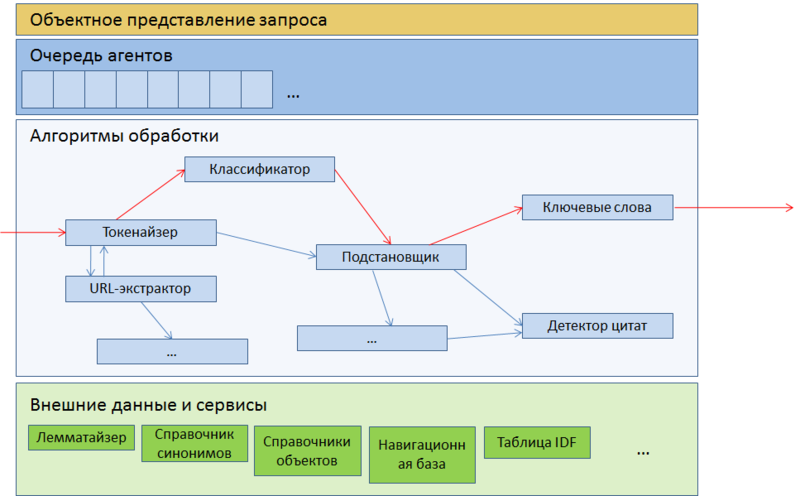
図 4.クエリパーサーアーキテクチャ
パーサーはエージェントのキューであり、各エージェントはリクエストに対して何らかのアトミックアクションを実行します。エージェントは、リクエストを単語やURLや電話番号などの他の通常のエンティティに分割し、引用検出器のような複雑な分類子で終了します。
エージェントが並んでいます。 各リクエストはこのキューを介して実行され、各エージェントの結果はリクエストのさらなる論理パスに影響します。たとえば、ナビゲーションとして分類されたリクエストは、クォート検出機能によって処理されません。 ここでは、リクエスト自体が一種の掲示板として提示され、各エージェントがメッセージを残したり、他のエージェントのメッセージを読んだり、必要に応じて変更またはキャンセルしたりできます。 完了すると、要求は追加のミキサーに送信され、最終的にバックエンドに送信されます。バックエンドでは、エージェントによって記録されたすべての追加パラメーターがランキングファクターとして使用されます。
辞書
クエリパーサーの主なデータプロバイダーは辞書です。 これらは、それぞれ特定の意味を持つ文字列のグループ化された配列を含む巨大なファイルです。

図 5.辞書:人生の例
この図は、辞書の1つのフラグメントを示しています。これには、「Films」クラスの照会で最も一般的な単語が含まれています。 これらの単語の各グループは、マーカーに関連付けることができます(図では、緑色の枠で囲まれています)。 そのようなフラグメントがリクエストで見つかった場合、リクエスト全体にフラグが立てられ、このリクエストの件名が映画であることを示します。
同じ辞書に、同義語が設定されています(図の赤枠)。 それらのおかげで、たとえば、クエリに「サウンドトラック」という単語が含まれている場合、クエリは「サウンドトラック」、「サウンドトラック」、および略語OSTのフレーズで展開されます。
そのような辞書は数十個あります。 それらのいくつかのサイズは、数十万、さらには数百万のそのような行です。 それらに基づいて、リクエストの主な処理である色付けが行われ、その後、より複雑なロジックが機能します。
マーカー
3つのクエリを見てみましょう。
●パイレーツオブカリビアン
●カリブ海の深さ
●カリブ海危機の結果
テキスト検索の観点からは、それらはすべて3つの単語を含む単なる文字列ですが、ユーザーの観点からは、それぞれがまったく異なる意味を持っています。 私たちの目標は、これらの違いについてできる限りシステムに伝えることです。
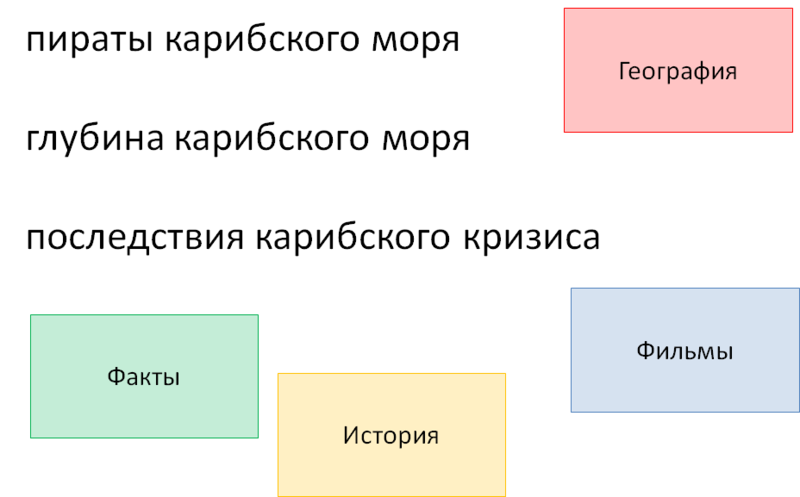
図 6.辞書とマーカー
図の4つの辞書は明確にするために選択されており、実際の辞書とは完全に一致していません。 これらの辞書には、ミキシングに適したファクト、歴史的出来事を含む辞書、映画を含む辞書、および地理的オブジェクトを含む辞書が含まれています。 クエリのすべての単語とフレーズはこれらの辞書を介して実行され、その結果、次のフラグメントが見つかります。
●パイレーツオブカリビアンは映画としてタグ付けされ、その中にはある種の地理があります
●カリブ海の深さは客観的な事実です
●カリブ海危機の余波には、「余波」という言葉や歴史的出来事であるカリブ海危機によって証明されるように、事実マーカーが含まれています。
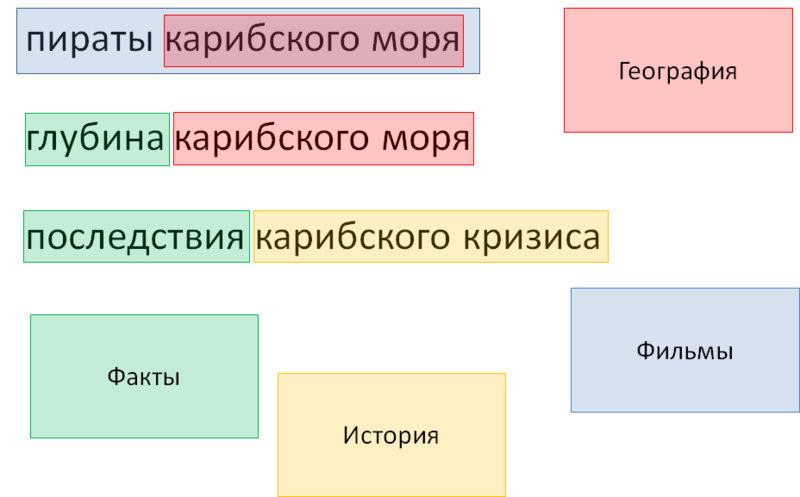
図 7.辞書とマーカー:中間結果
最後の手順は、ムービーに含まれる地理的特徴を削除して、選択を妨げないようにすることです。 そのような削除の必要性は、辞書の構文によっても構成されます。 これはマーカー欲と呼ばれます:原則として(常にではありませんが)、多数のマーカーと他のマーカーを含めることは、内部マーカーを無視する必要があることを意味します。
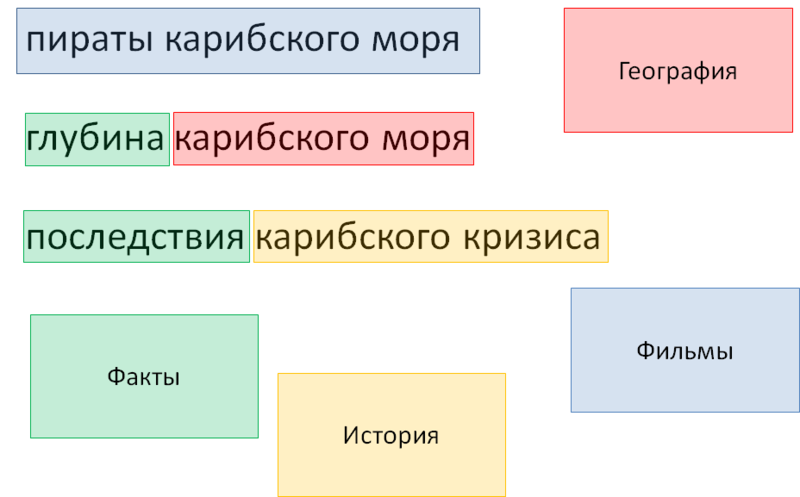
図 8.辞書とマーカー:合計
辞書の種類
辞書の内容は、2つの大きなクラスに分けられます。
●頻度表現-特定のトピックまたはユーザーの意図を特徴付けるマーカー。 このような辞書は手動でコンパイルされます。
●オブジェクト(映画、レシピ、料理、有名人、地名など)。
辞書を埋めるという観点から見ると、オブジェクトは最も興味深いものです。 いくつかのアプローチがあります。 1つ目は、手動で構成することです。 これは、データを取得する最高品質の方法ですが、最も時間がかかります。
オブジェクトの辞書の自動作成は別の投稿のトピックですが、簡単に説明すると、特定のタイプのオブジェクトの小さなトレーニングセットに基づいて、ログから同じタイプのオブジェクトを含むすべてのリクエストを選択し、これらの各リクエストを破壊する単純なアルゴリズムの複雑なセットですオブジェクトとそのコンテキスト。

クエリの多くはあいまいであることに注意してください。たとえば、「ホビットをダウンロード」というクエリの場合、ユーザーがダウンロードしたいもの(映画、映画、本、ゲーム)を言うことは完全に不可能です。
クエリパーサーの操作の最後のステップは、受信した情報をランキングに送信することです。 この前に、リクエストに関するデータと、インデックスからの構造およびデータの共通部分が発生します。 つまり、クエリワードごとにドキュメントのリストが逆インデックスから取得され、クエリツリーの構造で指定されたルールに従って交差します。 難しさは、すべての単語に異なる重みがあり、一部の単語はオプションと見なすことができる、単語の順序、クエリ内の形状、単語間の距離、その他のプロパティが重要であるという事実にあります。 受信したすべてのデータは、すべてのリクエストフラグとともにランキングに渡され、最終的な検索結果を決定する多数の要素の一部になります。

図 9.リクエストツリー:航空券モスクワテルアビブ
引用クエリ
引用は、より複雑な分類の例であり、辞書だけに基づいて定性的に行うことはできません。 最初に、引用符を処理するときに、クエリログが単純に分析されました。引用符の種類、それらの違いが明らかになりました。 引用リクエストの最も明白な主な兆候は、単語の長さ、文法の一貫性、大文字と句読点の存在です。 これらの特性に基づいて、最初のエージェントが実装されました。これは、手動で選択された係数とプリミティブif-then-elseロジックを使用して、リクエストが見積もりである確率を計算しました。
ただし、多くの要因があり、それらのそれぞれの影響を手動で評価することがすでに不可能であり、有害でさえある場合、マシン切り替えのためのさまざまなアルゴリズムが適用されます。 引用を識別する場合、ランキングで使用されるものと同じコードが使用されます。 引用リクエストへの応答は、ランキングに対するこの要因の影響だけでなく、同様のドキュメントの接着アルゴリズムの変更でもあります。 分類子が失敗し、その結果が全体として検索に失敗した場合、再要求を実行する必要があります。再要求では、要求は見積と見なされなくなります。 したがって、パーサーは検索アルゴリズム全体にも影響します。
図 10.引用
機械学習には、マルコフモデルに基づく決定木と方法が使用されます。 より洗練された方法は、リアルタイムでは法外に高価です。 したがって、クエリのクラスタリングまたはオブジェクトの選択は、その場で実行されるのではなく、予備処理に送信されます。
続く
ナビゲーションリクエストについては個別に説明します。今後数日間の継続をお待ちください。 さらに、次のエピソードでは、スペルチェッカーと賢者について説明します。
質問や有益な経験を共有したい場合は、コメントを歓迎します。
ミハイル・ドリニン、
検索クエリチームリーダー