まず、この研究の重要性を示すいくつかの統計。 システムのユーザーの約50%がvkontakte(VK)およびfacebook(FB)ソーシャルネットワークアカウントに登録されています。 さらに、ソーシャルネットワークを通じて登録された人の71%がVKを占め、29%がFBを占めています。
API FBおよびAPI VKを使用すると、ユーザーの興味や好みに関するデータを抽出できます。 しかし、すべてが見た目ほど単純ではありません。 ユーザーデータを取得するには、特別な権利を取得する必要があります。この権利は、システムに登録するときにユーザー自身が同意します。 ここで微妙な瞬間が生じます。 一方では、ユーザーに関する可能な限り多くの情報を取得します。 一方、あまりにも多くの権利を要求することは、ユーザーを怖がらせることができる大胆さです。 妥協点を見つける必要があります-推奨事項を改善するために取得したデータの有用性と、個人データを取得することに同意するユーザーからの信用の「量」との微妙なバランス。
私たち自身の長い試行錯誤を通して、このような妥協案を見つけましたが、多くのシステム固有の長所と短所が考慮されるため、このタスクは各プロジェクトごとに純粋に個別です。
この記事では、ゲーム、書籍、音楽、映画、テレビのカテゴリのユーザータグを使用する方法について説明します。 このフィールドの選択は、タグが純粋な形式で保存され、これらの各フィールドを対応するSurfingbirdカテゴリにバインドできるという事実によるものです。 おそらく近い将来、言語(ユーザーが話す言語)、デバイス(ユーザーが使用するハードウェアとソフトウェア)、教育(場所と教育レベル)など、それほど明白ではない他のフィールドをどのように処理できるかについても説明します。 bioまたはabout(自分に関する情報)、feeds(ユーザー投稿)。
すぐに予約したいのは、最初に遭遇する問題は強力なスパースデータだということです。 現在、ゲーム、書籍、音楽、映画、テレビなどの分野の情報は、ユーザーの約15%が利用できます。 しかし、ここでは、最初に、ユーザータグを取得する方法はFBおよびVK APIに限定されないということができます。 たとえば、将来的には、登録中にそれらを示し、プロファイルで調整する機会を与えることもできます。 第二に、自分の興味を正直に示した少数の人々に対して、最初のショーから「愉快に驚きます」という勧告を与えることができても、これはシステムに対する全体的な忠誠心を高め、それは私たちの努力が無駄にならないことを意味します。
FB APIとVK APIによって返されるデータ構造にはいくつかの違いがあります。 FBデータはより構造化されています。 たとえば、各アーティストまたは映画は別々のフィールドに保存されます。 VKでは、これらは任意のテキストフィールドに書き込まれるため、タグを選択するのが難しくなります。
FBからのJSONの例:
{ "books" : { "data" : [ { "category" : "Book", "created_time" : "2013-02-17T17:41:14+0000", "id" : "110451202473491", "name" : "« » " }, { "category" : "Book", "created_time" : "2013-02-04T20:40:10+0000", "id" : "165134073508051", "name" : " . \" \"" }, ... "television" : { "data" : [ { "category" : "Tv show", "created_time" : "2012-06-12T04:52:42+0000", "id" : "184917701541356", "name" : "- " } ], ... } ... }
JSONのVKの例:
{ "books" : " , \" , \", \" \", \" \", \" \", \" \", \" \", \" \", \"\", \" \"", "games" : "Sims 1, 2, 3, 2 ", "movies" : " , , , , , , icarli, , 3, , Sponge Bob, , , , , 2, 3, , !!!!!", ... }
多少の努力の後、非構造化VKデータからタグを取得できます。 最も人気のあるタグのリストのヒントを次に示します。
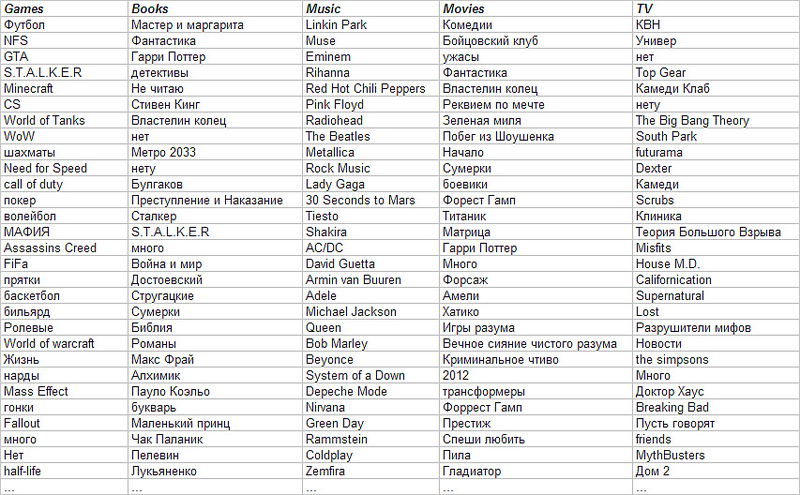
次に、3回以上出現するタグから、タグ辞書が作成されます。 ここで、辞書の各タグに関連するページを見つける方法を学ぶ必要があります。 最も自然な方法は、ページのテキストコンテンツ内のタグの出現回数をカウントする方法を学習することです。 ただし、タグには「すべて」、「読まない」、「ゲームが好きではない」などの単語がよく見られるため、出現頻度のみを推奨するのは正しくありません。 この問題を解決するために、 TF-IDFのエンドツーエンドの計算ではプロファイル内のテキスト情報の量の不均衡がまったく考慮されないため、 TF-IDFの重みはタグに対して、さらに複数のユーザーおよびWebページのテキスト本文に対して個別に計算されますユーザーとWebページのテキスト。
TF-IDFの重みを計算した結果、各ユーザーおよび各Webページで認識されている辞書からすべてのタグの重みベクトルを取得します。 ユーザーまたはページのコンテンツにタグが見つからない場合、重みはゼロと見なされます。
ユーザーの関心とWebページコンテンツの類似性を評価するには、対応するTF-IDF重みベクトルのスカラー積を計算するだけで十分です。 別のより怠laなオプションは、使用するDBMSに組み込まれている全文検索機能を使用することです。 たとえば、PostgreSQLは、ユーザータグで関連するテキストを検索するタスクにうまく対処し、類似性を数値的に評価することで、ランク付けの問題を解決できます。 実際、全文検索エンジンは、わずかに異なる方法を使用するだけで、上記で説明したものと同じアクションをすべて実行します。 このアプローチの欠点は、すべてのコンテンツに対してデータベースにフルテキストインデックスを作成する必要があることです。 このタスクでの全文検索の利点は、タグ辞書を作成し、テキスト内のタグの出現を再カウントする必要がないことです。
以下は、ゲームカテゴリ内の次のタグを使用したユーザー推奨の例です。 暗殺者の信条、質量効果、ドラゴンエイジ:オリジンズ、ヘビーレイン 。
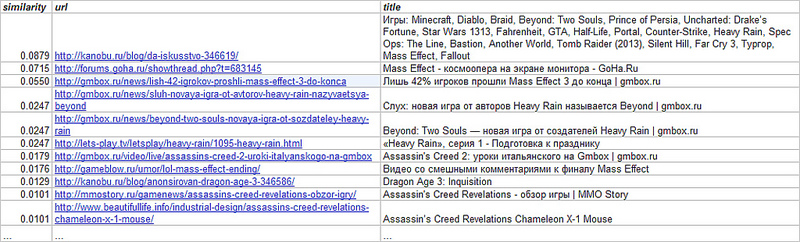
そのため、ユーザー(タグに基づく)とWebページ(コンテンツに基づく)の類似性を評価することを学びました。 これは、推奨事項を作成するために必要なメインブリックです。 しかし、これはすべてとは程遠いものです。 ここではウェブページの評価については考慮していません。 結局のところ、非常に人気のないページは、たとえコンテンツに適しているとしてもお勧めしたくありません。 次に、結果のアルゴリズムをシステムで既に動作しているアルゴリズムと正しく組み合わせる必要がありますが、それについては次のシリーズでさらに詳しく説明します...