
私たちの業界は、検索の品質に常に対処しなければならないように設計されています。 第1に、検索会社は互いに競合しており、改善があるとすぐに各市場シェアが変化します 。 第二に、検索エンジンオプティマイザーは、アルゴリズムの弱点を見つけて、検索結果内の人々のニーズとの関連性が低いサイトでさえ上げようとします。 第三に、ユーザーの習慣が変化しています。 たとえば、過去数年間で、平均検索クエリの長さは1.5ワードから3ワードに増加しました。
検索品質は複雑な概念です。 ランキング、 スニペット 、検索ベースの完全性、セキュリティなど、多くの相互接続された要素で構成されています。 この一連の記事では、品質の1つの側面、つまりランキングのみを考慮します。 多くの人が既に知っているように、それはユーザーに見つけた情報を提供するための手順に責任があります。
それを改善できる最も単純なアイデアでさえ、同僚間の議論から既成のソリューションの立ち上げまで、長く複雑な方法で進むべきです。 そして、このパスがより自動化されている(したがって、開発者にとって迅速で簡単な)ほど、ユーザーはより速くこの改善を活用でき、Yandexはより頻繁にそのようなイノベーションを開始できます。
まだ別のMapReduce(YAMR)分散コンピューティングプラットフォーム、 Matrixnet機械学習ライブラリ、および基本ランキング式学習アルゴリズムについて読んだことがあるかもしれません。 ここで、 FMLフレームワーク (フレンドリーな機械学習-「人間の顔をした機械学習」)について話すことにしました。 これは、同僚の作業を自動化および簡素化する次のステップでした。彼は、機械学習を使用して作業をフローに配置しました。 FMLとMatrixnetは、Yandex機械学習テクノロジーという1つのソリューションの一部です。
FMLについて話すことは非常に困難ですが、これを詳細に行いたいと思います。 したがって、ストーリーをいくつかの投稿に分割します。
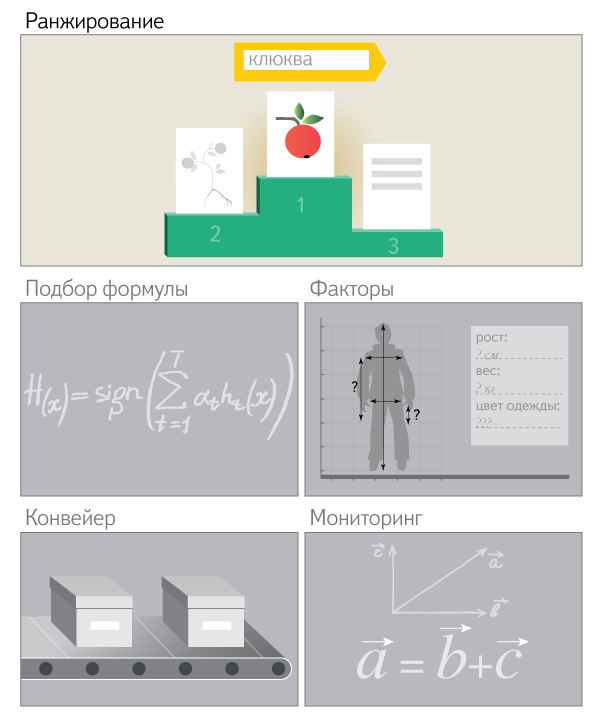
- ランキングとは何ですか、またどのタスクを解決しますか? ここでは、ランキングの問題と、この分野で発生する主な問題について説明します。 このトピックを扱ったことがない場合でも、この入門書はその後のすべての資料を理解するのに十分です。 また、ランキングにすでに精通している人は、使用されている用語を確認することができます。
- ランキング式の選択 。 FMLが数式を選択するためのコンベヤーになった方法について学習します(はい、たくさんあります!)。人間の関与を最小限に抑えながら、大量の評価者と新しい要因をすばやく考慮するためです。 また、Yandex GPUプロセッサで作成されたクラスターについても説明します。これは、世界で最も強力な数百のスーパーコンピューターに入る可能性があります。
新しい要因の開発とその有効性の評価 。 原則として、機械学習の分野の出版物は、式を選択するまさにそのプロセスに焦点を合わせ、新しい要因の開発をバイパスします。 しかし、機械学習テクノロジーがどれほど素晴らしいものであっても、良い要因がなければ機能しません。 Yandexには、作成に専念する開発者のグループもあります。 ここでは、テクノロジーサイクルの構成要素、新しい要因の結果、およびFMLが実装の利点とそれぞれのコストを評価するのにどのように役立つかについて説明します。
- すでに実装されている要素の品質を監視する 。 インターネットは常に変化しています。 そして、数年前に品質を改善するのに多くの助けをしていた要素が、今では価値を失い、コンピューティングリソースを浪費していることは完全に可能です。 したがって、FMLがどのように弱い要因が消滅し、強い要因に取って代わるという絶え間ない進化を維持するかについて説明します。
分散コンピューティングパイプライン 機械学習は、FMLがうまく解決するタスクの1つにすぎません。 時間とともに変化する大規模なデータアレイで数千台のサーバーのクラスターでの分散コンピューティングの作業を簡素化するために、より広く使用されています。 現在、Yandex.Searchの開発における計算の約70%はFMLによって管理されています。
スコープとアナログとの比較 。 FMLはYandexで、多くのコマンドを使用した機械学習や検索から遠く離れたタスクの解決に使用されます。 私たちの開発は、機械学習タスクを扱う業界の同僚にとって、そして単に大量のデータの計算に役立つと信じています。 Yandex以外でFMLが役立つ可能性のあるタスクの範囲を概説し、市場で入手可能な類似物と比較します。 また、FMLをCERNに適用することで、ノーベル賞への道を開く方法についても説明します。
ランキングとは何ですか、またどの問題を解決しますか

検索エンジンがユーザーのリクエストを受け入れ、関連するすべてのページを見つけたら、リクエストに最も関連性のある原則に従ってそれらを配置する必要があります。 この作業を実行するアルゴリズムは、ランキング関数と呼ばれます(メディアでは、関連性式と呼ばれることもあります)。 発見されたページの中で最も重要なものを選び出し、それらの発行の「正しい」順序を決定するためであり、ランク付けタスクがあります。 その改善は、FMLとMatrixNetが使用される最初で最も重要な場所です。
かつてYandexでは、ランキング関数は1つの式で表現され、厳選されていました。 そのサイズは指数関数的に増加します(グラフでは、Yスケールは対数です)。

時間が経つにつれて、式は制御できないサイズに達すると脅かされたという事実に加えて、手動選択から機械学習への移行には他の理由がありました。 たとえば、ある時点で、ユーザーの地域に応じて同じリクエストが異なる方法で処理されるように、同時にいくつかの式を用意する必要がありました 。
正式には、ランキングでは、教師との機械学習タスクのように、エキスパートデータに最適な機能を構築する必要があります。 ランキングでは、専門家が特定のリクエストに対してドキュメントを表示する順序を決定します。 そのようなリクエストは数万件あります。 そして、専門家の評価の観点からすると、式によって形成されたドキュメントの順序が良いほど、より良いランキングが得られました。 これらのデータは推定値と呼ばれ 、多くの人が知っているように、個々の専門家- 評価者によって準備されます。 各リクエストに対して、特定のドキュメントがどの程度適切に応答するかを評価します。
トレーニング中の関数の入力データは、それによって他の要求のドキュメントの順序を決定する必要があり、いわゆるファクター -さまざまなページ属性です。 これらの兆候は、要求に応じて(たとえば、ページのテキストに含まれる単語の数を考慮する)、またはそうでない(たとえば、サイトの開始ページを内部から区別する)場合があります。 トレーニングに使用される要因の中には、リクエスト自体の兆候もあります。これは、すべてのページに共通です。たとえば、リクエストの言語、リクエストに含まれる単語数、ユーザーがリクエストする頻度などです。
機械学習では、トレーニングセットを使用して、人による評価から得られたクエリのページの順序とこれらのページの属性との関係を確立します。 結果の関数は、専門家の評価の可用性に関係なく、すべてのクエリをランク付けするために使用されます。
適切なランキング式を作成するには、関連性の推定値を取得するだけでなく、それらが正しく選択されるクエリを選択することも重要です。 したがって、ユーザーの関心を最もよく表すようなサブセットを採用します。
評価者の評価を取得するための技術はいくつかあり、それぞれが独自のタイプの判断を下します。 現在、Yandexの査定者は、文書と文書の関連性を5段階で評価しています。 この方法は、 Cranfield II方法論に基づいています。 他のタスクでは、他のタイプのエキスパートデータを使用します。たとえば、分類器でバイナリ推定を使用できます。
標準的な手法がランキングに適用されない理由
ただし、十分な数の評価を収集し、各ペア(クエリ+ドキュメント)の一連の要因を計算した後でも、標準の最適化方法を使用してランキング関数を作成するのはそれほど簡単ではありません。 主な困難は、 ターゲットのランキングメトリック (nDCG、pFoundなど)の区分的に一定の性質のために発生します 。 このプロパティでは、たとえば、最適化する関数の微分可能性を必要とする既知の勾配法を使用できません。
ランキング指標とその最適化に特化した別の科学分野があります- ランク付けの学習 。 また、Yandexには、このかなり狭いが、最適化問題のクラスを見つけるために非常に重要な問題を解決するためのさまざまな方法の実装と改善に取り組んでいる特別なグループがあります。
ランキング指標とその最適化に特化した別の科学分野があります- ランク付けの学習 。 また、Yandexには、このかなり狭いが、最適化問題のクラスを見つけるために非常に重要な問題を解決するためのさまざまな方法の実装と改善に取り組んでいる特別なグループがあります。
したがって、ランキング機能は、一連の要因と専門家によって準備されたトレーニングデータに基づいて構築されます。 MatrixnetライブラリであるYandexの場合、機械学習もその構築に従事しています。 次の投稿では、検索要素の由来と、それがFMLとどのように関連するかについて説明します。