優先度の反転 -優先度の低いプロセスが優先度の高いプロセスをブロックまたは減速させる可能性がある状況。 通常、これは、優先度の低いコードに対する優先度の高いコードのカーネルでの実行へのアクセスのシーケンスを指します。 OSのカーネルがこれをうまく処理するはずです。 ただし、アフィニティとMSI-Xを介して簡単に配布できる処理コアに加えて、プロセッサにはすべてのタスクに共通のリソース(メモリコントローラー、QPI、一般的な3次キャッシュ、PCIeデバイス)があります。 PCIeの質問には入りません。なぜなら、 私はこのトピックの専門家ではありません。 長い間、メモリアクセスとQPIに基づく優先度の反転を見ていません-原則として、最新のマルチチャネルコントローラーの帯域幅は、高優先度タスクと低優先度タスクの両方に十分です。 キャッシュについて説明します。
第3世代Core i7アーキテクチャプロセッサのキャッシュを含む図を検討してください。 ただし、どの世代でも関係ありません。

このかなり高いレベルの抽象化では、Nehalem、Westmere、Sandy Bridge、Ivy Bridge、Haswellの違いは目立ちません。 ところで、Sandy Bridge内でどのように機能するかについての最も詳細な説明は、 Hennesseyの記事 (はい、その1つ)にあります。
最大レベルの3次キャッシュ(LLC)がすべてのコア(「缶を引く」コア)と優先度の低いプロセス、および可能な限り必要な外部デバイスまたはローカルAPICタイマーからの割り込みを受け取るコアを同時に処理することがわかります。処理と結果の生成を高速化します。 最終レベルキャッシュのエビクションポリシーは、 LRUの一種の近似です。 したがって、特定のコアがキャッシュを使用する頻度が増えるほど、LLCのより多くの部分がキャッシュを取得します。 優先事項は? 優先事項は何ですか?? ちなみに、あまり重要ではないタスクは、優先度の高いタスクほどきちんとプログラムされないことが多く、したがって、特に大量のメモリとキャッシュが必要です。 優先度の高いタスクは外部イベントを予期することがよくありますが、そのデータとコードはLLCから強制的に除外されます。 私はすでにこれについて何らかの形で書いていますが、その投稿へのコメントで、L1 / L2キャッシュの排他性に関する質問に誤って答えました。
上記の図を見ると、各コアには少なくとも256キロバイトのサイズの独自のキャッシュがあるようです。 .textおよび.dataの多くのリアルタイムタスクには十分です。 さて、少なくとも32 kbのデータ+ 32 kbのコードをキャッシュに保存し、数クロックサイクルの応答時間を常に計算できますか? これは簡単に確認できます。
ハイパートレッドと電源管理を無効にします。 次のマイクロベンチマークを起動します。
ヘルパー関数
#define POOL_SIZE_L1D_LINES 512 #define POOL_SIZE_L2_LINES 8192 // This can differ on your CPU. Check with CPUID or some system diagnostics tool #define POOL_SIZE_LLC_LINES 6*1024*1024/64 // Yes, I waste 3/4 of space for the sake of test simplicity // 1 cache line == 1 linked list item. // Pointer length is hard coded to 8 bytes (Intel 64) struct list_item { unsigned long long int tick; list_item *next; unsigned char padding[48]; }; // Build a linked list of size N with pseudo-random pattern void build_list(list_item *head, int N, int A, int B) { int C = B; list_item *current = head; for (int i = 0; i < N - 1; i++) { current->tick = 0; C = (A*C + B) % N; current->next = (list_item*)&(head[C]); current = current->next; } } // Touch first N elements in a linked list void warmup_list(list_item* current, int N) { bool write = (N > POOL_SIZE_L2_LINES) ? true : false; for(int i = 0; i < N - 1; i++) { current = current->next; //No write is needed to keep a line in L1,but looks like it is needed to keep it in L2! if (write) current->tick++; // FIXME AK: to check on HSW } }
build_listはリストを初期化し、プリフェッチャーが通常のアクセスパターンを見つけられないようにします。 同時に、リスト全体がキャッシュにあり、そのレベルに適合します。
次に、2番目のカーネルでリストトラバーサルを開始し、各反復に必要な平均時間を測定します。
リンクリストの横断速度の測定
void measure(list_item* head, int N) { unsigned __int64 i1, i2, avg = 0; for (int j = 0; j < 50; j++) { list_item* current = head; #if WARMUP_ON while(in_copy) warmup_list(head, N); #else while(in_copy) spin_sleep(1); #endif i1 = __rdtsc(); for(int i = 0; i < N; i++) { current->tick++; current = current->next; } i2 = __rdtsc(); avg += (i2-i1)/50; in_copy = true; } printf("%i\n", avg/N); }
さまざまなサイズのリストを通過する時間を測定するストリームのコードは次のようになります。
異なるリンクリストサイズの測定
// We initialize the linked list only once, and make it big enough to make sure // we do not observe effects of spatial locality but only effects of temporal locality // Magic numbers 509, 509 <= Hull-Dobell Theorem criteria build_list(head, POOL_SIZE_LLC_LINES*2, 509, 509); for (int i = 10; i < POOL_SIZE_L1D_LINES; i+=5) { warmup(head, i); measure(head, i); }; for (int i = POOL_SIZE_L1D_LINES; i < POOL_SIZE_L2_LINES; i+=50) { warmup(head, i); measure(head, i); }; for (int i = POOL_SIZE_L2_LINES; i < POOL_SIZE_LLC_LINES*2; i+=1000) { warmup(head, i); measure(head, i); };
3番目のレベルでキャッシュを詰まらせる2番目のストリームを追加します。コア番号3でスピンさせ、18 MBのデータを前後にコピーします。 18MB-必ずLLCを獲得してください。 最初のスレッドと同期させて、ほとんどすべての時点でそのうちの1つだけがアクティブにキャッシュを操作するようにします。 (スピンロックの実装は正しくなく、非効率的であり、すべてが適切なタイミングのおかげでのみ機能することを認識しています。)
別のコアで実行され、LLCを消費するスレッド
list_item *area1 = (list_item *)malloc(POOL_SIZE_LLC_LINES*64*2); list_item *area2 = (list_item *)malloc(POOL_SIZE_LLC_LINES*64*2); while (true) { while(!in_copy) spin_sleep(1); #if DISRUPT_ON memcpy(area1, area2, POOL_SIZE_LLC_LINES*64*3); memcpy(area2, area1, POOL_SIZE_LLC_LINES*64*3); #else spin_sleep(10); #endif in_copy = false; };
3つのタイプの測定を実行します。
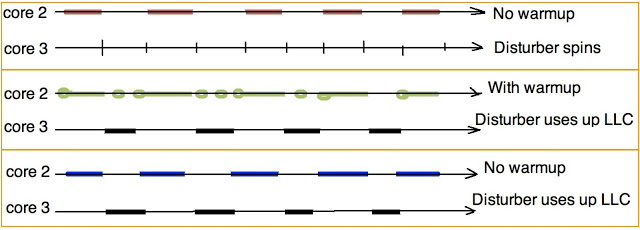
- 「赤」テストであるベースラインは、良好な条件下でリストをクロールする速度を示します-2番目のスレッドはキャッシュを使用しません。
- 悪いオプションである「ブルー」テストは、最初のスレッドがスピンロックでハングしている間に2番目のスレッドが自分自身でLLCボリューム全体を取得した場合に何が起こるかを示しています。
- 最後に、「グリーン」テストは、待機中に最初のスレッドが定期的にデータを読み取るとどうなるかを示しています。
制御のために、害虫フローのデータがその「独自の」L2に適合するテストも実行しました。 予想どおり、この場合、最初のスレッドによるリストのクロール速度に影響はありませんでした。 (理論的には、コンフリクトミスは見られますが、私はそれらを観察しませんでした)
測定結果は次のとおりです。
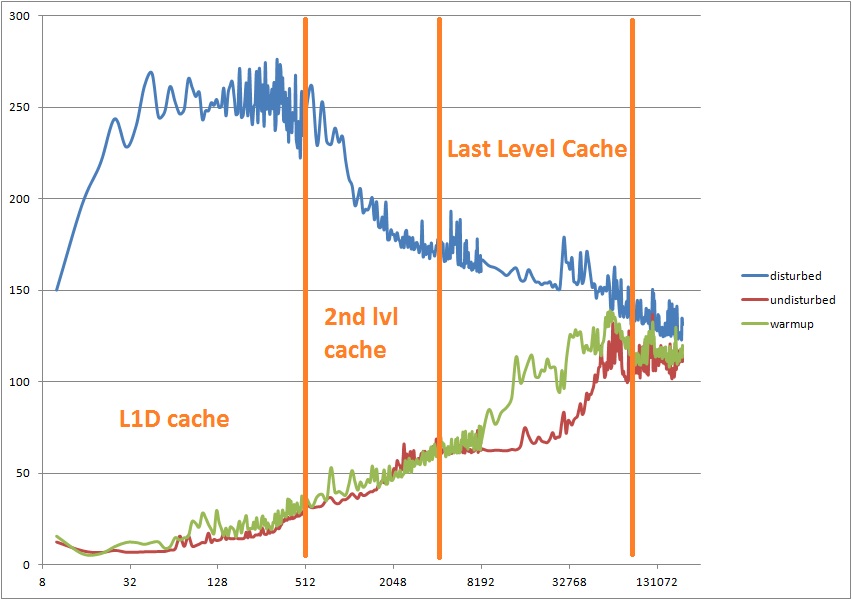
水平-リスト内のアイテムの数。 垂直-1つの要素の通過に費やされたCPUサイクル。 興味深いことに、「ステップ」(キャッシュの境界が表示されるグラフ)を取得するには、ベンチマークをわずかに変更し、空間的な局所性を少し追加するだけです。
比較のために、このテストを実行したコンピューターでのメモリ階層の要素へのアクセス時間は次のとおりです。
- L1Dヒット= 4サイクル、
- L2ヒット= 11サイクル、
- LLCヒット= 31サイクル、
- DRAMヒット=〜100サイクル、
リストを1回クリックするのにかかる時間は比例します
L1D_hit * P(L1D_hit)+ L2_hit * P(L2_hit)+ LLC_hit * P(LLC_hit)+ DRAM_hit * P(DRAM_hit)、Pはこのキャッシュレベルで次のリストアイテムを見つける確率です。 つまり
P(L1D_hit)+ P(L2_hit)+ P(LLC_hit)+ P(DRAM_hit)= 1
特定の確率分布は、キャッシュに対するリストのサイズに依存し、Vtune、oprofile、またはLinux perfを使用して測定できます。 たとえば、16,384アイテム(512キロバイト)の固定リスト長のVtune確率測定は次のとおりです。
| 邪魔されない | 乱れた | ウォームアップ | |
| L1ヒット率 | 0.08 | 0 | 63 |
| L2ヒット率 | 72 | 0.07 | 0.1 |
| LLCヒット% | 25 | 2.6 | 22 |
| DRAMヒット率 | 3 | 97 | 15 |
| DTLB miss% | 21 | 66 | 37 |
最初のスレッドが中断時に目覚めた場合、「青」バージョンでは、IDTとISRコードでさえも、すでにL1I、L2、およびLLCから絞り出されているため、メモリからドラッグする必要があります。 残念なことに、Core i7アーキテクチャの最新のプロセッサには、特定のコアで排他的に使用されるLLCの一部を「ロックアップ」する機能がありません。 したがって、重要なデータをLLCから削除し、結果としてL2およびL1から削除するのを避ける唯一の方法は、それらが現時点で必要でない場合でも定期的に更新することです。
この投稿では、Core i7のアーキテクチャに何らかの問題が見つかったとは言いたくありません。 一般的なケース(デスクトップ、ほとんどのサーバー負荷)でのこのキャッシュの編成(より多くのリソースがより多くを必要とする人に届きます)は、パフォーマンスを改善します。 上記の優先順位の逆転のケースは、通常リアルタイムシステムに関連する狭いクラスのタスクで発生する可能性があります。 また、プリフェッチャーが通常役立ちます。 ポインタを擬似ランダムアドレスに配置したからといって、このテストで失敗します。
わあ! 大きなテキストを書いたばかりで、そのエッセンスをツイートに載せることができたようです。「キャッシュラインが1つのコアによってLLCから追い出されると、同じキャッシュラインがそれを所有するコアのL1および/またはL2から追い出されます。 したがって、キャッシュをウォームアップすると便利です。 」