はじめに
人を見ると、通常、性別を正確に判断します。 時には間違いを犯すこともありますが、そのような場合にはそれを行うのは本当に難しいことがよくあります。
多くの場合、何らかのコンテキストを使用します。 そのため、たとえば、この記事の著者にとって、衣服の色は、1〜2歳までの子供の性別を特定しようとするときに、最も重要な兆候であることがあります。
顔画像から性別を判断するタスクに移りましょう。 各顔画像を男性のクラスまたは女性のクラスのいずれかに割り当てます。 必要なのは、写真がどのクラスに属するかを決定するメカニズムです。 この設定では、問題は典型的な機械学習タスクのように見えます。MとGの2つのクラスのマークされた例のセットがあります。「マーク」は、各写真が描かれた人物の性別に関連付けられていることを意味します そのため、分類子が必要です。
しかし、何に基づいて、性別分類器は画像がどのクラスに属するかを決定しますか? いくつかの特性が必要です。 各画像は、あるサイズのマトリックスです。
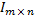
別のアプローチは、いくつかのピクセル比を使用することです。 膨大な数のこのような関係または機能が開発されています。 特定のタイプの特性の適用可能性の研究は、多くのコンピュータービジョンタスクの重要なステップです。
特徴
性別認識の問題を解決するために、記事「性別識別パフォーマンスの向上[1]」の著者は、以下で説明する一連の単純な機能を使用することを提案しています。
簡単にするために、画像内のすべてのピクセルに番号を付けます。
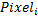 -シリアル番号を持つピクセルの輝度を意味します
-シリアル番号を持つピクセルの輝度を意味します 


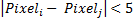


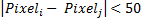
言い換えれば、画像内のすべての可能なピクセルのペアを構成し、それらの差を計算し、上記のルールを適用します。 各比較はバイナリ特性を提供します。 たとえば、

 私たちが持っている:
私たちが持っている:
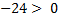 -偽(0)
-偽(0) 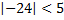 -偽(0)
-偽(0)  -偽(0)
-偽(0) 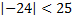 -真(1)
-真(1)  -真(1)
-真(1)
したがって、特性のベクトルがあります
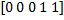 。 これらの5つの特性は、逆特性によって補完されます-
。 これらの5つの特性は、逆特性によって補完されます- 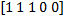 。 これらのベクトルを組み合わせて、次のバイナリ特性のセットを取得します
。 これらのベクトルを組み合わせて、次のバイナリ特性のセットを取得します 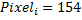 そして
そして 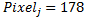 :
: 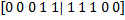 。 読者は論理的な質問を持っているかもしれません:トレーニングセットに既に入っているデータを否定することによって得られるデータを入力する理由は? なぜこの冗長性が必要なのですか? いい質問です! それに対する答えは、後で分類子を作成するときに明らかになります。
。 読者は論理的な質問を持っているかもしれません:トレーニングセットに既に入っているデータを否定することによって得られるデータを入力する理由は? なぜこの冗長性が必要なのですか? いい質問です! それに対する答えは、後で分類子を作成するときに明らかになります。
したがって、ピクセルの各ペアに対して、画像に対して10個の特性があります。
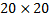 取得するピクセル
取得するピクセル 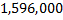 特性。 繰り返しになりますが、このコンテキストの特性は、上記のルールを適用したピクセルの違いにすぎません。
特性。 繰り返しになりますが、このコンテキストの特性は、上記のルールを適用したピクセルの違いにすぎません。
明らかに、性別の認識にすべての特性を使用する必要はありません。 さらに、そのような多数の数の処理は非効率的です。 確かにこの一連の特性の中には、性差を他のものよりもうまく符号化する特性のごく一部があります。 では、そのような特性を選択する方法は?
この問題は、AdaBoost [2] [3]アルゴリズムを使用して効果的に解決されます。その目的は、非常に大きな初期配列から貴重な特性の小さなセットを選択することです。
データ準備と分類子トレーニング
データの準備から始めましょう。 トレーニングとテストには、FERET個人データベース[4] [5]を使用します。 994人(男性591人、女性403人)のさまざまな写真が含まれており、さらに、各人物にはさまざまなポーズで撮影されたいくつかの写真があります。

それぞれの写真で目を見つけて、関心のある領域を切り取り、サイズに縮小する必要があります

幸いなことに、FERETの作成者は、顔の主要なポイントを手で確認し、その中に目がありました。 ただし、実際の認識システムでは、目は特別なアルゴリズムで配置されます。これは通常、手動配置よりも精度が低くなります。 したがって、性別認識トレーニングの段階で関心のある領域を切り出すために、認識システムと同じアイアライメントアルゴリズムを使用することをお勧めします。 この場合、分類器はアイアライメントアルゴリズムのエラーを考慮して「学習」します。
前処理の結果、2セットの写真があります。

明確にするために、上の図の各面には寸法があることに注意してください
 ピクセル、実際には、考慮されたアプローチでは、サイズの画像 ピクセル。 名前が示すとおり、トレーニングセットは分類器のトレーニングに使用されます。 テストサンプルは分類器にとって「不明」であるため、その助けを借りて客観的に精度を測定できます。
ピクセル、実際には、考慮されたアプローチでは、サイズの画像 ピクセル。 名前が示すとおり、トレーニングセットは分類器のトレーニングに使用されます。 テストサンプルは分類器にとって「不明」であるため、その助けを借りて客観的に精度を測定できます。
したがって必要
- 各写真について、以下を含むバイナリ特性(弱い分類器)のベクトルを作成します。
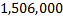 要素
要素 - すべての写真のこのようなベクトルを2つのマトリックスに「パック」します。
 そして
そして 
- 対応する出力データベクトルを作成します。
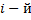 要素は、値1を取ります
要素は、値1を取ります 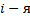 写真は男性のもので、それ以外の場合は0
写真は男性のもので、それ以外の場合は0
以下の図は、入力データと出力データのマトリックスを示しています。 このようなペアは、トレーニングセットとテストセットの両方で作成する必要があります。
それでは、学習アルゴリズムを「言葉で」理解してみましょう。 以下は、AdaBoostアルゴリズムの正式な図です。
クラスMとGを最適に分離できるような特性を選択することがタスクであることを思い出してください。すでに分析したと仮定します。
 そのような特性を順番に、分析に進みます
そのような特性を順番に、分析に進みます 

値
最初の3つのトレーニング例の特性  これらの例のラベルベクトル値
これらの例のラベルベクトル値 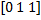 。 値を取る場合 性別予測としての特性、この場合の誤差ベクトルは
。 値を取る場合 性別予測としての特性、この場合の誤差ベクトルは 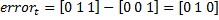 。 特性を考慮すると
。 特性を考慮すると 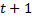 それから
それから 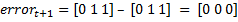 。 したがって、特性の選択
。 したがって、特性の選択 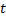 そして 優先されるべきです 以来
そして 優先されるべきです 以来 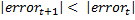 。 すべての特性を調べた後、分類に使用するT bestを見つけます。
。 すべての特性を調べた後、分類に使用するT bestを見つけます。
そして今、正式なトレーニング手順。
トレーニングの例:
 どこで
どこで 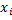 -画像
-画像 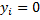 女性の場合
女性の場合 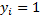 男性の場合。
男性の場合。
重みのベクトルを初期化します
 :
:
 i番目の写真が女性の場合
i番目の写真が女性の場合 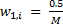 i番目の写真が男性の場合
i番目の写真が男性の場合
どこで
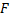 そして
そして 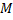 それぞれ女性と男性の例の数。
それぞれ女性と男性の例の数。
のために
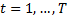 ( Tは選択する特性の数です)
( Tは選択する特性の数です)
- 重みを正規化して、
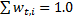 。
。 - すべての弱い分類器について、
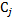 、重みを考慮した分類エラーを考慮します。
、重みを考慮した分類エラーを考慮します。 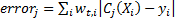 。 各例で、エラーは値が正しい分類の場合は0、または
。 各例で、エラーは値が正しい分類の場合は0、または 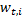 間違っている場合。 以来 それから
間違っている場合。 以来 それから 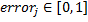 。
。 - 分類器を選択してください
 最小のエラーで
最小のエラーで 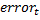 データの分類方法を確認します。
データの分類方法を確認します。 - 重みを更新します。
例が誤って分類されている場合(つまり、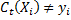 )、
)、
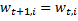 。
。
そうでなければ
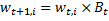 、
、
どこで
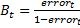 。
。
結果の分類子は次の式で表されます。
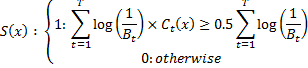
取り得る値の範囲を評価してみましょう
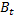 。 私たちはすでに注意しました
。 私たちはすでに注意しました 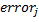 セグメントの値を取ります
セグメントの値を取ります 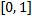 。 今、それを仮定します
。 今、それを仮定します  いくつかの分類器
いくつかの分類器 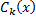 。 明らかに、この場合
。 明らかに、この場合 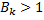 。 しかし、そのような分類器は上記のアルゴリズムによって選択されますか? 明らかに、それは起こりません。トレーニングサンプルには常にそのような分類器があるからです。
。 しかし、そのような分類器は上記のアルゴリズムによって選択されますか? 明らかに、それは起こりません。トレーニングサンプルには常にそのような分類器があるからです。 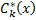 否定演算を使用して取得
否定演算を使用して取得  そのために
そのために 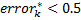 そして
そして  。 例が正しく分類された場合、次の値を乗算することでその重みが減少することがわかります。
。 例が正しく分類された場合、次の値を乗算することでその重みが減少することがわかります。  、したがって、誤って分類された例(複雑な例)はより重要になります。
、したがって、誤って分類された例(複雑な例)はより重要になります。
さて、以前に尋ねた冗長性の問題に戻ります。 否定によって得られた分類器のサンプル内の存在
限界 セグメント上  複雑な例の重みが大きくなります。
複雑な例の重みが大きくなります。
入力行列のサイズを考えると、標準のAdaBoostアルゴリズムによる最初の1000個の特性の選択には約10時間かかります(Intel Core i7)。 標準は、すべての特性を実行することを意味します。 セット全体のランダムな特性で動作するアルゴリズムのバージョンがありますが、その説明はこの記事の範囲外です。 10時間のトレーニング時間は、1回限りの操作であるため、このタスクでは許容できる結果です。
アルゴリズムの結果は、比較する必要があるピクセルインデックスのペア、5つの比較ルールの1つ、および値であることに注意してください。
ペアごとに。 実際、写真を分析するには、差異を計算し、選択したルールを適用し、次の式を使用して解決策を見つけるだけです。 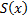 。 したがって、このアルゴリズムは完全にリソースを必要とし、使用される認識システムの速度を低下させることはありません。
。 したがって、このアルゴリズムは完全にリソースを必要とし、使用される認識システムの速度を低下させることはありません。
結果
楽しい部分になりました! AdaBoostはどのような特性を選択しましたか?! 以下は、AdaBoostが選択した最初の50個の機能です。 赤と白のピクセルそれ
そして 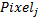 。 画像の端近くのピクセルを分析するとき、多くの人の顔はフレームに収まらないことに注意してください。 したがって、エッジピクセルは、何らかの方法で顔のサイズをエンコードできます。
。 画像の端近くのピクセルを分析するとき、多くの人の顔はフレームに収まらないことに注意してください。 したがって、エッジピクセルは、何らかの方法で顔のサイズをエンコードできます。

使用する特性の数に対する分類精度の依存性を考慮してください。

スケジュールは、トレーニング段階でAdaBoostが「見なかった」人のFERETデータベースのデータを使用して取得したことに注意してください。 911機能を使用すると、93.1%の最大精度が達成されます。 このアプローチの著者は、94.3%の精度を報告しています。これは、取得した指標に非常に近いものです。 トレーニングサンプルとテストサンプルの内訳が異なるため、1.2%の差が生じる場合があります。 また、この記事では、独自のアルゴリズムを使用して目を検索しましたが、その精度はFERETデータベースの人間の目の位置合わせの精度とは異なります。
しかし、分類器が訓練されたベースのみを認識することを学んだ場合はどうなりますか?! 同様の効果は、試験の準備をしている学生が本質を理解せずに、単に式、タスク、例を暗記する場合に発生します。 そのような学生は、すでに見た問題だけを解決することができ、新しい問題に知識を広げることはできません。 機械学習におけるこの効果は、過剰適合と呼ばれ、深刻な認識の問題です。 逆の効果は一般化と呼ばれます。
一般化する能力をテストするために、別の個人ベース-ボスポラスデータベース[6] [7]を使用します。 105人の写真で構成されています。 ベースには、1人あたり最大35種類の表情が含まれています。
下のグラフは、ボスフォラスデータベースを使用して得られた唯一の違い(つまり、テストサンプルに精通している可能性は除外されています)で、少し高いグラフに似ています。

テストサンプルには、1300枚の写真(727 Mおよび573 W)が含まれています。 954仕様で最大精度91%を達成しています。 100の特性で既に90%のマークに達していることに注意してください。
これら2つのグラフと記事にあるビデオは、トレーニング段階で彼が「見なかった」データに対するこのアプローチの高い精度を示しています。 それが、性別認識のための最先端のアルゴリズムと考えられている理由です。
次のビデオは、テレビ番組の断片に対するアルゴリズムの動作を示しています。 この精度を達成するために、時間の経過に伴う結果の「平滑化」が使用されます。各顔は19フレームで観察され、それぞれが性別を決定します。 その結果、最後の19フレームで最も頻繁に発生する性別が選択されます。
参照資料
- S.バルハ、およびH.ロウリー、 性識別パフォーマンスの向上 、International Journal of Computer Vision、v。 71 i。 2007年1月1日
- Y.フロイントとR.シャピレ、 「オンライン学習の意思決定理論的な一般化とブースティングへの応用」、 Journal of Computer and System Sciences、1996年pp。 119-139
- Y.フロイントとR.シャピレ、 ブースティングの簡単な紹介 、日本人工知能学会誌、14(5):771-780、1999年9月
- PJフィリップス、H。ムーン、SAリズヴィ、PJラス、 「顔認識アルゴリズムのFERET評価方法論」 、IEEE Trans。 パターン分析と機械知能、Vol。 22、pp。 1090-1104、2000
- http://www.itl.nist.gov/iad/humanid/feret/feret_master.html
- ボスポラスデータベース
- A. Savran、B。Sankur、MT Bilge、「顔のアクションユニットの自動検出のための3Dモダリティと2Dモダリティの比較評価」、パターン認識、Vol。 45、第2号、p767-782、2012年。