 特定のクラスのアルゴリズムの並列化の効率を改善する方法の1つは、順次および並列の両方の実行フェーズのパイプライン化です。 インテルTBBは、システム内のスレッド間のタスク管理と負荷分散を処理することにより、パイプラインアルゴリズムの実装に必要な労力と時間を削減するのに役立ちます。 ただし、アルゴリズムのフェーズを構成するタスクの定式化と形成は、アルゴリズムの複雑さに応じて重要な問題になる可能性があり、これは実際のアプリケーションでよくあることです。 アルゴリズム自体に監視用のツールが含まれていない場合、タスクの監視はさらに難しくなります。 インテルVTuneアンプのタスク分析ツールは、開発者がマルチスレッド環境で実行構造を便利なグラフィカル形式で表示できるようにし、分析効率を高め、アプリケーション開発時間を大幅に短縮します。 この記事では、パイプラインタスクの簡単な例を見て、TBBパイプラインクラスを使用して並列化し、VTune Amplifierで分析し、分析結果に基づいて実装パフォーマンスを改善します。
特定のクラスのアルゴリズムの並列化の効率を改善する方法の1つは、順次および並列の両方の実行フェーズのパイプライン化です。 インテルTBBは、システム内のスレッド間のタスク管理と負荷分散を処理することにより、パイプラインアルゴリズムの実装に必要な労力と時間を削減するのに役立ちます。 ただし、アルゴリズムのフェーズを構成するタスクの定式化と形成は、アルゴリズムの複雑さに応じて重要な問題になる可能性があり、これは実際のアプリケーションでよくあることです。 アルゴリズム自体に監視用のツールが含まれていない場合、タスクの監視はさらに難しくなります。 インテルVTuneアンプのタスク分析ツールは、開発者がマルチスレッド環境で実行構造を便利なグラフィカル形式で表示できるようにし、分析効率を高め、アプリケーション開発時間を大幅に短縮します。 この記事では、パイプラインタスクの簡単な例を見て、TBBパイプラインクラスを使用して並列化し、VTune Amplifierで分析し、分析結果に基づいて実装パフォーマンスを改善します。
はじめに
よく知られているように、一般的な場合の計算タスクは、異なるタスクによって並列に実行されるサブタスク(分解)に分割できます。 タスクまたは入力データのタイプに応じて、データまたはタスク自体に分解を適用できます。 簡単に言えば、データ分解は、同じ計算アルゴリズムで異なる計算機で処理するために入力データセットを分割することと考えることができます。 タスクによる分解-反対に、同じデータまたは異なる部分で異なるデバイスによって実行されるいくつかの異なるアルゴリズム。 コンピューティングデバイスの分解の主な目的は、タスクの計算中、使用可能なすべてのデバイスが可能な限りビジーであることを確認することです。 これにより、このタスクを実行するときに既存のデバイスセットのパフォーマンスが最大になり、完了するまでの時間が短縮されます。 この点で、アルゴリズムを最適化するためには、コンピューターシステム内のタスクの各部分とタスク全体の両方の実行を分析する能力が非常に重要です。 この記事では、新しいバージョンのVTune Amplifier XE 2013プロファイラーを使用して、インテルTBBライブラリーを使用して並列化された計算問題を分析する可能性を検討します。
すぐに、翻訳なしで豊富な英語の用語を失礼するようお願いします。 これは意図的に行われたものです。ツールを使用するときはまだ使用する必要があり、それらをロシア語に翻訳しようとしても読者を混乱させるだけです。 (UPD:写真の翻訳されていないテキストが目を痛めると言われました-私は翻訳に取り組んでおり、すぐに写真を更新します)
はじめに、コンピューターシステム、データセットなど、一般化された表現が豊富に含まれていることは偶然ではないため、実際のタスクとはほとんど関係のない一般化された例から始め、その後、分析する実例に徐々に進みます。 。 真空で実行される球面アルゴリズムを考えてみましょうが、同時に、あるソースからデータを取得し、このデータに対していくつかの並べ替え手順を実行し、処理されたデータを受信機に書き込むという実際のタスクによく似ています(図1)。 このような構造は、コーデック、フィルター、または通信プロトコルが最も早く頭に浮かぶ多くのアプリケーションで非常に一般的です。

図1
真空の深さを維持し、例を単純化するために、ソースからのデータの部分間の可能な関係を考慮しません。 これは正しくありませんが、たとえば、コーデックでビデオフレームを処理する場合、隣接するピクセルの依存関係がアルゴリズムによって考慮されるためです。 ただし、一般的なケースでは、十分に大きなデータ配列をいつでも選択できます。これは、他の配列から独立していると見なすことができます。 同時に、分解をかなり安全に使用して、データのさまざまな部分で並列に計算アルゴリズムを実行することができます。これにより、アルゴリズムの真球度が歪められ、図2に示す回路に似たものになります:データはソースから順次読み取られ、並列ブロックで処理されます(P) 、そして再び連続して受信機に書き込まれます(W)。

図2
データソースがディスクやネットワークインターフェイスなどのシリアルデバイスである場合、読み取りと書き込みのプロセスもシーケンシャルになります。 システムに無料のコンピューティングスレッドがある場合でも、並列化できる実行ステージはアルゴリズムの実行フェーズのみです。 アムダールの法則によると、並列化によるタスク全体のパフォーマンスの向上は、これらの連続したフェーズに限定されます。
この制限を克服するために、すべてのエグゼクティブフローがその実装で常にビジーになるように、タスクの一部を再配布できます。 これは、データ部分が独立しており、その処理順序が重要でない場合、または出力に復元できる場合に可能です。 これを行うために、各スレッドで実行される同じ読み取り/プロセス/書き込みステージで構成される単純なパイプラインを構築します(図3)。 読み取りおよび書き込みステージは引き続きシーケンシャルのままですが、スレッド間で分散されます。 他のストリームが同じステージを実行している間、ストリームは読み取りまたは書き込みステージを開始できないことに留意する必要があります。 ただし、2つの異なるストリームは、異なるデータを同時に読み書きできます。
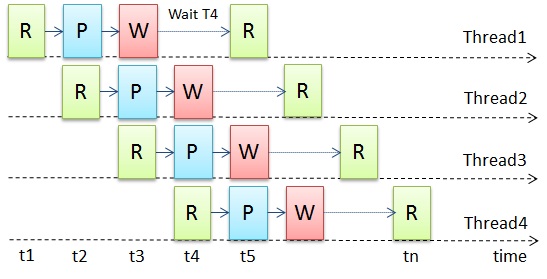
図3
この方法でアルゴリズムを再構築するために、タスク分解を正式に使用しました。つまり、タスクの異なるフェーズが異なるスレッドによって同時に実行されました。 同時に、データをパーツに分割し、それらに対して異なるストリームで同じ操作を実行するために、データ分解も使用します。 この組み合わせアプローチにより、スレッドが常に仕事で忙しくなり、タスク全体の効率が最大化されるようになります。 ただし、読み取り/書き込みデバイスの遅延の可能性を考慮していないため、アルゴリズムの球形性は依然として維持されます。また、データ入力の不規則性を平滑化するためのコンピューティングフローには多くの作業があり、コンピューティングデバイスは常に実行可能ですアルゴリズム。
実際には、事態はさらに複雑になる可能性があります。 たとえば、データを送信するために入力/出力デバイスが費やす時間の安定した値を保証したり、プロセッサーが現時点で空きであったり、データが同種であり、同じアルゴリズムによる処理に同じ時間を必要とすることを保証するものはありません。 ほとんどの場合、ソースの特性により、入力データが遅れて到着する場合があります。 プロセッサは、優先度の高い他のタスクでビジー状態になっている可能性があります。 データによっては、処理時間が長くなる場合があります。たとえば、詳細が小さいフレームは、均一な背景を持つフレームよりも圧縮アルゴリズムによってはるかに長く処理されます。 原則として、書き込み操作は問題ではありません。ほとんどのシステムではバッファリングされており、レシーバーへの物理的なデータの書き込みが遅くなる可能性があるためです。 これは、出力が入力で再び使用されない場合にのみ機能しますが。 一般に、球面真空モデルから既存のシステムの問題の実際の実装に移行すると、コンベヤーの計画された効率はすべて無駄になる可能性があり、複雑なスキームは元の単純なスキームと同様に非効率のままです(図4)。

図4
負荷の不均衡によって引き起こされる非効率性を排除するために、各スレッドによって実行される作業を動的に分散させることができます。 これには、ビジースレッドの状態を監視し、アルゴリズムによって処理されるデータのサイズを制御し、空きスレッド間でサブタスクを分散する必要があります。 そのようなインフラストラクチャの実装は、簡単な場合にのみ、ほとんど労力を必要とせずに可能です。 一般に、このようなインフラストラクチャをゼロから開発することは非常に困難です。 そして、スレッド間の動的な負荷分散のためのメカニズムを既に含んでいるIntel TBBライブラリの機能をアドバタイズする時です。 また、この例では、TBBには、 パイプラインクラスと呼ばれる組み込みパイプラインアルゴリズムが含まれています。これは、タスクでの使用に適しています。
例
オープンソースコードを含むすべての情報はthreadingbuildingblocks.orgにあるため、TBBでのパイプラインアルゴリズムの実装については詳しく説明しません。 以下に、タスクの例、TBBを使用してパイプラインを作成する方法を示します。 サンプルコードは、ライブラリディレクトリまたはWebサイトにあります。
簡単に言えば、パイプラインとは、一連の実行ユニットをオブジェクトのストリームに適用することです。 エグゼクティブユニットは、データストリームに対して特定のアクションを実行するタスクステージを実装できます。 TBBライブラリでは、これらのステージはフィルタークラスのインスタンスとして定義できます。 したがって、コンベアは一連のフィルターとして構築されます。 一部のステージ(Processingなど)は、異なるデータを持つ複数のストリームで並行して動作するため、 パラレルフィルタークラスとして定義する必要があります。 読み取りや書き込みなどの残りの段階は、順番に特定の順序で実行する必要があり(順序を変更しない場合)、 serial_in_orderフィルタークラスとして定義されます。 ライブラリにはこれらの型の抽象クラスが含まれており、それらからクラスを継承する必要があります。 以下は、特定の単純化を使用して、これを行う方法を示す例です。
| |
| |
この例では、データはファイルに含まれているため、ファイルポインターのプライベートクラスメンバーを定義する必要があります。 同様に、記録ステージのMyWriteFilterクラスを定義し、出力ファイルへのポインターを保存します。 これらのクラスは、データおよびパイピングオブジェクト用のメモリの割り当てを担当します。 主な作業は、基本クラスで定義されたoperator()メソッドで実行されます。 入力ファイルからコンテナへのデータの読み取りと、コンテナから出力ファイルへのデータの書き込みをそれぞれ実装することにより、これらのメソッドを再定義するだけです。
| |
Processステージはスレッドで並列に実行できるため、 並列フィルタークラスとして定義し、 operator()メソッドにはデータフロー処理アルゴリズムの「肉」を含める必要があります。
| |
最終的にパイプラインを組み立てるだけで済みます。 フィルタークラスのオブジェクト、 パイプラインクラスのオブジェクトを作成し、すべてのステージを接続します。 パイプラインを構築した後、トークンの数を示すパイプラインクラスのrun()メソッドを呼び出す必要があります(このような転送はごめんなさい)。 この場合、トークンの数は、パイプラインで同時に実行できるデータオブジェクトの数を意味します。 適切な量を選択することは、議論のための別のトピックになる可能性があります。TBB文書の推奨事項に従って、システムで使用可能なスレッド数の2倍に等しい数を選択します。 これにより、パイプラインをビジー状態に保つのに十分なデータオブジェクトを用意すると同時に、最初の段階で後続のオブジェクトよりもはるかに高速にデータオブジェクトを処理する場合、データオブジェクトのキューが拡大しないことを保証できます。
tbb::pipeline pipeline; MyReadFilter r_filter( input_file ); pipeline.add_filter( r_filter ); MyProcessFilter p_filter; pipeline.add_filter(p_filter ); MyWriteFilter w_filter( output_file ); pipeline.add_filter( w_filter ); pipeline.run(2*nthreads)
したがって、パイプラインに3つのサブタスクを作成しました。これらは、システムで利用可能なプロセッサーの使用を最大化するためにTBBライブラリによって管理されます。プロセスサブタスクは並列化され、残りのサブタスクは可用性に応じてスレッド間で動的に分散されます。 これらのステージを正しく接続するだけで済みました。 ご覧のとおり、この例ではフロー制御コードはありません。これはすべてライブラリタスクスケジューラに隠されています。
よくあることですが、最後から2番目の行(または逆に最初の行)から手を挙げて、非常に細心の注意を払ったリスナーが非常に良い質問をします。構築されたコンベアが効果的であることをどのように確認できますか? さらに深く掘り下げた場合、サブタスクがパイプラインでどのように実行されるか、サブタスクを管理するオーバーヘッドはどのようになっているのか、そして実装にギャップがあるのかを正確に知るにはどうすればよいですか?
アルゴリズムの実装を初期の非効率的な実装と比較することを提案することは無意味です。 まず、より高速に動作すること以外は何も理解できません。 そして第二に、おそらくそれはより速く動作し、動作しません。
つまり、これらの質問に対する単純な答えはありません。 測定および分析する必要があります。 VTune Amplifier XEを使用したプロファイリングにより、このプロセスがより簡単に、より直感的に、そして最も重要なこととしてより高速になります。 VTuneアンプは、システムにプロセッサーをロードする効率を判断し、TBBライブラリのタスク管理スキームを明確に示し、パイプラインの構築中にアルゴリズムのパフォーマンスに影響を与える可能性のあるエラーを検出するのに役立ちます。
教育目的のために、ホットスポット分析から始めましょう。 ファイルからテキスト形式で整数値を読み取り[読み取りステージ]、それらを2乗して[プロセス]、テキスト形式で再度数値を[書き込み]出力ファイルに書き込むコードの例を分析します。 読者はVTuneプロファイラーの操作の基本に精通していると想定し、プロファイリングを開始するためにどのボタンを押すかについては詳しく説明しません。
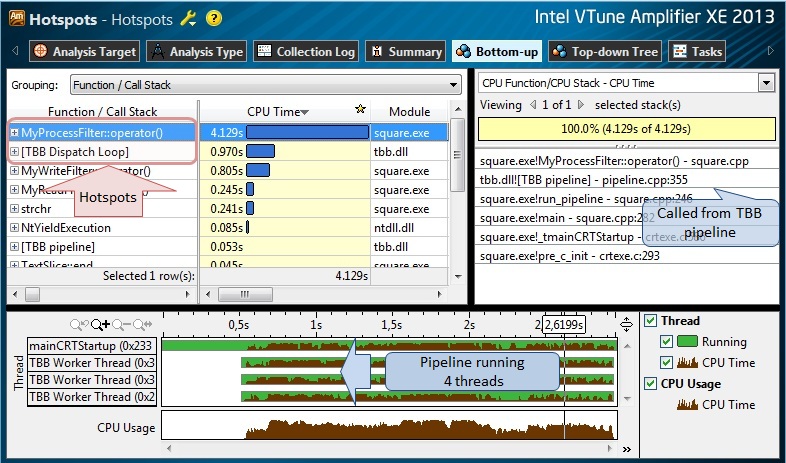
図5
ホットスポット分析の結果(図5)は非常に期待されています-テストプログラムは4コアプロセッサ上の4つのスレッドによって実行されました。 TBBパイプラインから呼び出されるMyProcessClass :: operator()メソッドは、テキストから整数に変換し、値の2乗を計算し、テキストへの逆変換を実行するため、最もホットな関数です。 興味深いことに、一部の関数[TBB Dispatch Loop] (実際には関数ではなく、TBBスケジューラの「内部」を隠す条件名)もホットリストに含まれており、計画のオーバーヘッドが存在する可能性を示しています。 並行性分析を続けて、アルゴリズムの並列化の有効性を判断しましょう。
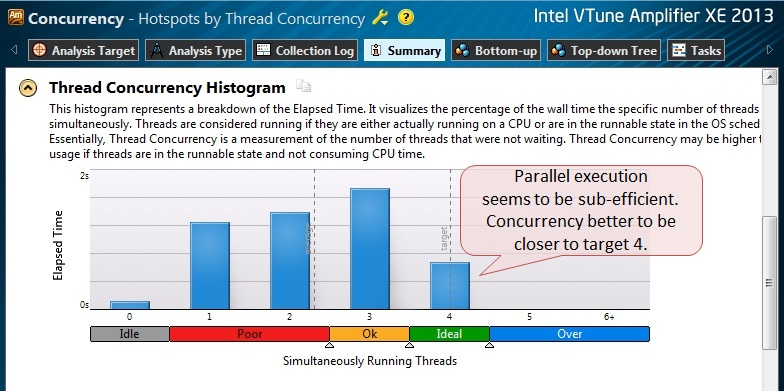
図6
結果のプログラムの並列ヒストグラムから、最大効率にはほど遠いことがわかります。基本的に、アプリケーションは4スレッド未満で実行されました。 (ヒストグラムの青いバーは、アプリケーションがY軸に沿ってXスレッドで作業した時間を示します。理想的には、同時実行レベル4 [4]の単一の列を表示したいです。 。
ボトムアップビューの結果を一目見ただけでも、スレッド間で発生した過剰な同期を確認するのに十分です(図7)。 黄色のトランジションにカーソルを合わせると、ポップアップウィンドウにこの同期のソースへのリンクが表示されます。
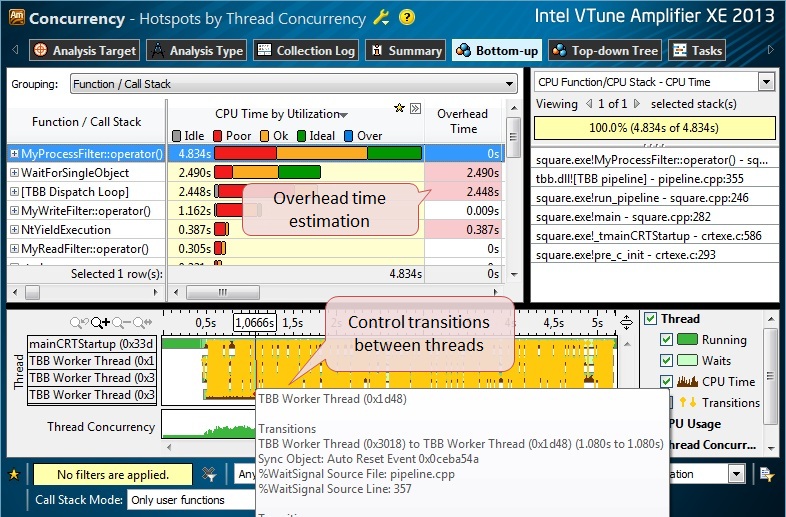
図7
この時点で、最も忍耐強いユーザーでさえ、さらなる調査をあきらめ、偶然にもライブラリの非効率的な実装をTBB開発者のせいにします。 スケジューラの作業を分析するツールが手元になかったら、同じことをしていたでしょう。 理論的には、ソースコードのインスツルメンテーションを使用してタスクを独立してトレースし、「手動」でトレースを解析するか、タスクのタイミングを特定するスクリプトを想像できます。 ただし、組み立てられたトラックの処理が複雑であるため、このパスは魅力的に見えません。 したがって、すでにVTuneアンプに含まれているツールを使用することをお勧めします。これらのツールを使用すると、便利なグラフィック形式でユーザータスクを実行する構造をすばやく復元できます。
タスクアナライザーを有効にするには、VTune Amplifierで利用可能なタスクAPIの特別な機能を使用してソースコードをインストルメントする必要があります。 これを行うには、次の手順を実行する必要があります。
- ソースにユーザーAPIのヘッダーファイルを含めます
#include "ittnotify.h"
- タスクのドメインを定義します。 異なる並列インフラストラクチャ(TBB、OpenMPなど)のスレッドなど、異なるドメインで実行されるタスクを分離することは非常に便利です。
__itt_domain* domain = __itt_domain_create("PipelineTaskDomain");
- ステージを記述するタスクハンドルを定義します。
__itt_string_handle* hFileReadSubtask = __itt_string_handle_create("Read"); __itt_string_handle* hFileWriteSubtask = __itt_string_handle_create("Write"); __itt_string_handle* hDoSquareSubtask = __itt_string_handle_create("Do Square");
- 次に、タスクの段階で実行されるソースコードを、計測API関数__itt_task_beginおよび__itt_task_endへの 呼び出しでラップします。 たとえば、読み取りと書き込みの段階は次のように直感的です。
void* MyReadFilter::operator()(void*) { __itt_task_begin(domain, __itt_null, __itt_null, hFileReadSubtask); // ALLOCATE MEMORY // READ A DATA ITEM FROM FILE // PUT DATA ITEM TO CONTAINER __itt_task_end(domain); }
void* MyWriteFilter::operator()(void*) { __itt_task_begin(domain, __itt_null, __itt_null, hFileWriteSubtask); // GET DATA ITEM FROM CONTAINER // WRITE THE DATA ITEM TO FILE // DEALLOCATE MEMORY __itt_task_end(domain); }
同様に、プロセス段階をラップすることもできます。 (ユーザーAPI関数の詳細については、製品のドキュメントを参照してください)。
void* MyProcessFilter::operator()( void* item ) { __itt_task_begin(domain, __itt_null, __itt_null, hDoSquareSubtask); // FIND A CURRENT DATA ITEM IN CONTAINER // PROCESS THE ITEM __itt_task_end(domain); }
- VTune Amplifierヘッダーファイルへのパスをプロジェクトに追加することを忘れないでください。
$(VTUNE_AMPLIFIER_XE_2013_DIR)を含む - 実行可能モジュールをlibittnotify.libライブラリにパスを静的にリンクします
$(VTUNE_AMPLIFIER_XE_2013_DIR)lib [32 | 64]システムの「ビットネス」に依存します。
そして最後に、分析構成ウィンドウ(図8)でユーザータスクの分析を有効にし、必要なプロファイリングを開始することが残っています。
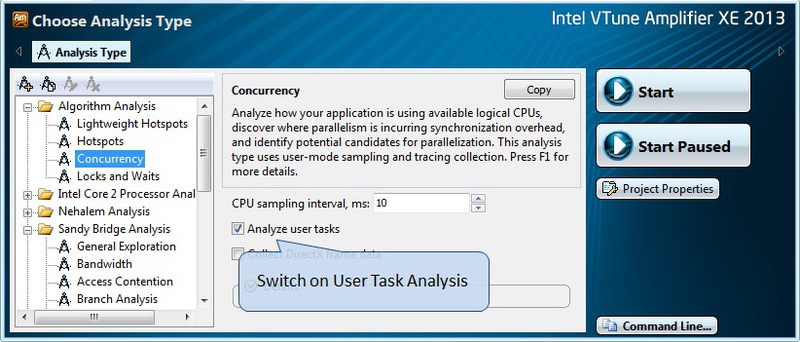
図8
同時実行のプロファイリングが完了したら、[タスクビュー]タブに切り替えます(図9)。 ここで、フロー制御の遷移の黄色の線は、多少干渉します-右側のパネルで無効にすることができます。また、必要な情報をカバーするCPU時間グラフも無効にすることができます。 ただし、それでも、タスクはタイムライン上でほとんど区別できません。 タスクのグラフィック表現を表すカラーバーは細すぎて区別できません。 この場合、より短い時間間隔を選択し、右クリックコンテキストメニューまたはツールバーを使用してスケール(拡大)を増やします。
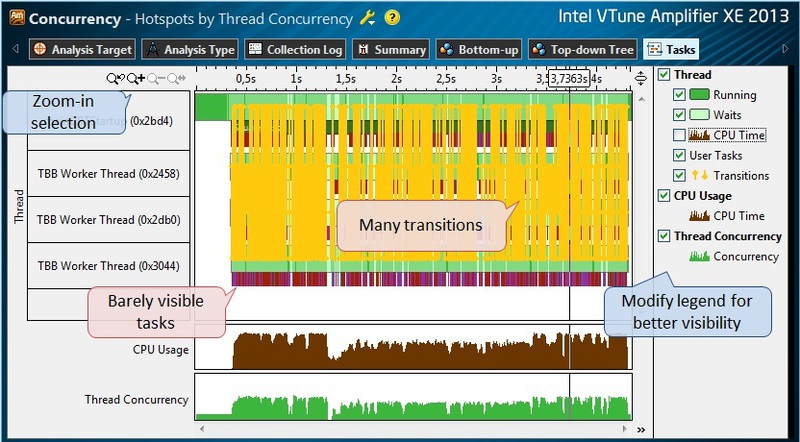
図9
タスクの拡大画像では、いくつかの問題に気付くことができます(図10)。 1つ目は、スレッドが非アクティブである、つまりプロセッサがアイドル状態で、同期イベントを待機しているタスク間の間隔です(タスク自体の期間と比較して)。 2番目の問題は、タスクフェーズの期間です。 たとえば、「Do Squire」サブタスクには約0.1ミリ秒しかかかりません。 タスクはTBBスケジューラによって管理されているため、これは非常に短い実行間隔であり、タスクをスケジュールしてTBBワーカースレッドによって実行されるように割り当てるには時間がかかります。 つまり、サブタスクを管理するオーバーヘッドは、タスク自体を完了するのにかかる時間と釣り合っていることがわかります。 これは許可されないため、サブタスクでの作業に費やす時間を増やす必要があります。つまり、より多くの作業を与える必要があります。
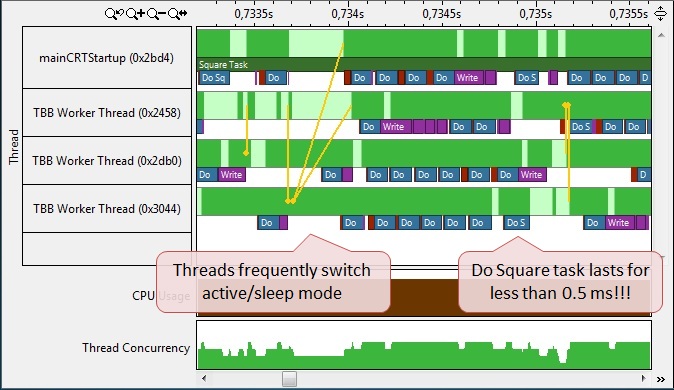
図 10。
この例では、コード内のどの関数がどのタスクを実行するかはすでに明確になっていますが、これは記事のプレゼンテーションを簡素化するために意図的に行われたものです。 実際のアプリケーションでは、多数の機能がタスクの実行に関与する可能性があります。 タスクの実行に影響を与え、負荷を増加させるすべての機能を見つけるために、同時実行またはホットスポットプロファイリングの結果のボトムアップビューに切り替えることができます。 タスクのタイプ(TaskType / Function)による関数のグループ化を変更し、アプリケーションをインスツルメントすることで作成したサブタスクのリストをテーブルに取得します。 タスクを開き、「+」アイコンをクリックすると、このサブタスクの実行に参加した関数の呼び出しのリストとツリーが表示され、統計的に有意なプロセッサ時間が消費されます(図11)。

図11
次に、ダブルクリックして、ホット関数MyProcessFilter ::演算子()のソースコードに移動し、渡されたテキスト(テキストスライス)で機能することを確認します(図12)。 この関数内では、テキスト内の文字を反復処理し、整数型に変換し、値をそれ自体で乗算し、テキスト文字に戻します。 特定のサブタスクの負荷を増やす最も明白な方法は、テキストのサイズを増やすことです。これにより、このサブタスクで実行される操作の数が直線的に増えます。 セグメントMAX_CHAR_PER_INPUT_SLICEの最大文字数の新しいサイズを選択します。これは、たとえば、プロファイリング中に受け取った時間インジケーターに基づいて、元の100倍になります。 また、1つのオブジェクトのデータサイズが大きくなると、読み取りおよび書き込み操作の効率も向上すると想定しています。

図12
アプリケーションを再コンパイルし、タスク分析を使用して再度プロファイルします(図13)。 Do Squareサブタスクは約10ミリ秒で実行されるようになりました(タスクの画像にカーソルを合わせて数値特性を取得します)。 また、サブタスク間に「ギャップ」が実質的にないため、スレッドが長時間ビジーになります。 また、TBBスケジューラが、書き込みフェーズなどの同じだが短いサブタスクを配置し、それらをより長いキューに接続し、同じスレッドで実行されるように割り当てることで、追加の同期のコストを削減する方法に気付くことができます。
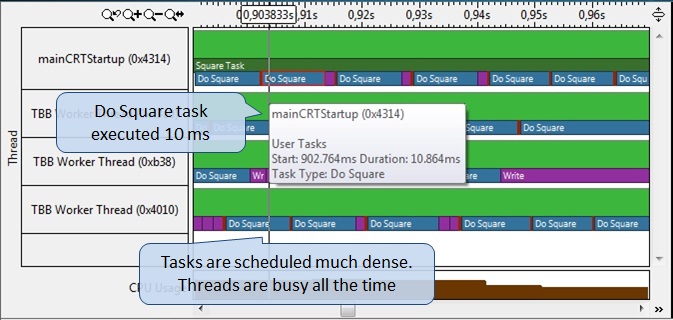
図13
また、プログラム全体の完全な並列性を確認することも興味深いでしょう。 図14からわかるように、アプリケーションは主に3スレッドまたは4スレッドで実行されました。これは、最初の結果と比較して大きな成果です。 同時実行レベルの平均値を比較することもできますが、並列化していない部分も含めて、アプリケーションのシーケンシャル部分に影響することを覚えておく必要があります。
はい、プログラムのシリアル部分は残りますが、1/3減少しました。 タイムラインビューの結果にも表示されます。 この連続部分が選択され、残りの時間で除外される場合、メインスレッドのアプリケーション全体の初期化フェーズに対応することがわかります。 どの部分がパイプラインの操作に対応し、初期化に関連していないかを正確に判断したい場合、プロファイリングを制御するユーザーAPI関数を使用できます-パイプラインを作成する直前にコレクションを開始し、作業が完了した後にコレクションを終了します。

図14
実装効率を改善するための推定アイデアを提供するグラフに加えて、アプリケーションの数値パフォーマンス指標を調べて比較できます。 VTune Amplifierのすべての結果は、適切な比較機能を使用して比較できます。 最初のホットスポット分析の結果と、コードを変更した後に得られた結果の対応関係をよりよく理解するために、単純に2つの画像を並べて表示します(図15)。 興味深いことに、プログラムの実行時間(Elapsed Time)は減少しましたが、関数MyProcessFilter :: operator()で費やされた時間は変更されていません。これは、総作業量を変更せず、単に再配布したためです。 同時に、TBBタスクプランニングのコストが大幅に削減されました。 さらに、テキストの大きなセクションでの作業がより効率的になるため、データの読み取りと書き込みの合計時間も明らかに減少しました。
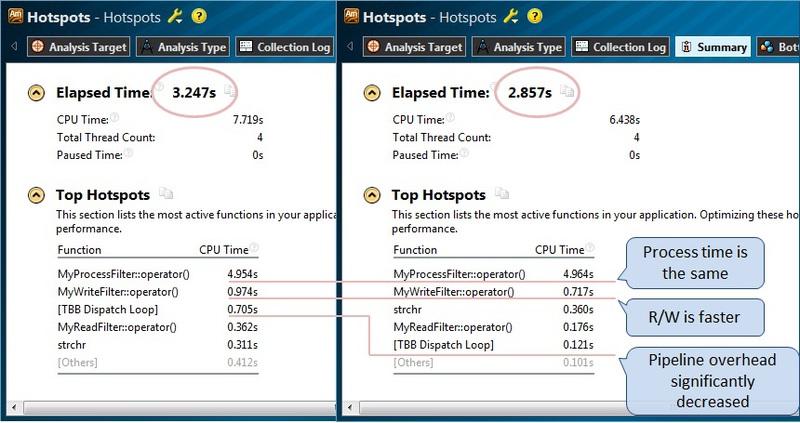
図15
おわりに
データとタスクに応じた分解は、アルゴリズムの並列化に効果的に使用されます。 アルゴリズムの一部のクラスは、順次実行フェーズと並列実行フェーズのパイプライン技術を使用して改善できます。 インテル®TBBライブラリーは、アルゴリズムのパイプライン化の実装にかかる時間を大幅に削減すると同時に、システムで利用可能なスレッドでタスクのスケジューリングと実行のバランスをとるタスクを引き受けます。 アルゴリズムのフェーズに基づいたタスクの形成は、実装されているアルゴリズムの複雑さに応じて重要なタスクになる可能性があり、タスクの実行の管理はさらに困難になる可能性があります。 VTune Amplifierのタスク分析ツールキットを使用すると、開発者はマルチスレッド環境でのタスクの実行を便利なグラフィカル形式で視覚化できるため、分析効率が向上し、アプリケーション開発時間が大幅に短縮されます。