私は英語を勉強し、このプロセスをあらゆる方法で簡素化します。 どういうわけか、特定のテキストの翻訳と転写とともに単語のリストを取得する必要がありました。 タスクは難しくなく、仕事に取り掛かりました。 少し後に、 Pythonスクリプトが作成されました。Pythonスクリプトは、これをすべて知っています。さらに、英語のテキストを含むすべてのファイルから周波数辞書を取得したかったので、もう少し知っています。 それで、スクリプトの小さなセットが出てきました。それについてお話ししたいと思います。
スクリプトは、ファイルを解析し、英語の単語を選択し、それらを正規化して、結果の英語の単語のリスト全体から最初のcountWordの単語をカウントおよび発行することによって機能します。
最終ファイルでは、単語は次のように記述されます。
[繰り返し回数] [単語自体] [単語の翻訳]
次に何が起こるか:
- ファイルから英語の単語のリストを取得することから始めます( 正規表現を使用)。
- 次に、単語の正規化を開始します。つまり、単語を自然な形式から辞書に保存されている形式に戻します(ここでは、 WordNet形式について少し学習します)。
- 次に、すべての正規化された単語の出現回数をカウントします(これは迅速かつ簡単です)。
- さらに、 StarDict形式の詳細についても説明します。これは、それを利用して翻訳と文字起こしを行うためです。
- 最後に、結果をどこかに書き込みます( Excelファイルを選択しました)。
私はpython 3.3を使用しましたが、多くの場合、必要なモジュールが欠落していたため、python 2.7で記述しなかったことを後悔しなければなりません。
周波数アナライザー。
それでは、簡単なものから始めて、ファイルを取得し、それらを単語に解析し、カウントし、ソートし、結果を生成しましょう。
まず、テキスト内の英語の単語を検索するための正規表現を作成します。
英語の単語を検索するための正規表現
「over」などの簡単な英語の単語は、 「([a-zA-Z] +)」という表現を使用して見つけることができます。英語のアルファベットの1つ以上の文字がここで検索されます。
「司令官」などの複合語を見つけるのはやや難しくなります。「司令官」、「in-」、「チーフ」という形式の連続した部分式を探す必要があります。 正規表現の形式は、 「(([a-zA-Z] +-?)* [A-zA-Z] +)」です。
中間部分式が式に存在する場合、結果にも含まれます。 そのため、「司令官」という単語だけでなく、見つかったすべての部分式も検索結果に含まれます。 正規表現は、 「((?: [A-zA-Z] +-?)* [A-zA-Z] +)」という形式を取ります。 私たちはまだ、表現に「did n't」という形式のアポストロフィを含む単語を含める必要があります。 これを行うには、最初の部分式の「-?」を置き換えます 「[-']?」 。
それだけです。正規表現の改善を終了します。さらに改善することもできますが、これについて詳しく説明します。
「((?:[a-zA-Z] + [-']?)* [a-zA-Z] +)」
英単語の周波数分析器の実装
英語の単語を抽出し、それらをカウントして結果を生成できる小さなクラスを作成します。
# -*- coding: utf-8 -*- import re import os from collections import Counter class FrequencyDict: def __init__(): # self.wordPattern = re.compile("((?:[a-zA-Z]+[-']?)*[a-zA-Z]+)") # ( collections.Counter ) self.frequencyDict = Counter() # , def ParseBook(self, file): if file.endswith(".txt"): self.__ParseTxtFile(file, self.__FindWordsFromContent) else: print('Warning: The file format is not supported: "%s"' %file) # txt def __ParseTxtFile(self, txtFile, contentHandler): try: with open(txtFile, 'rU') as file: for line in file: # contentHandler(line) # except Exception as e: print('Error parsing "%s"' % txtFile, e) # def __FindWordsFromContent(self, content): result = self.wordPattern.findall(content) # for word in result: word = word.lower() # self.frequencyDict[word] += 1 # # countWord , def FindMostCommonElements(self, countWord): dict = list(self.frequencyDict.items()) dict.sort(key=lambda t: t[0]) dict.sort(key=lambda t: t[1], reverse = True) return dict[0 : int(countWord)]
これで、本質的に、周波数辞書を使用した作業は完了できますが、作業はまだ始まったばかりです。 問題は、テキスト内の単語が文法規則を考慮して書かれていることです。つまり、末尾にed、ingなどの単語がテキスト内で発生する可能性があります。 実際、動詞の形式(am、is、are)でさえ、異なる単語としてカウントされます。
そのため、単語を単語カウンターに追加する前に、正しい形式にする必要があります。
次のパートに移ります- 英単語のノーマライザーを書きます 。
英語の補助詞
ステミングと見出し語化の 2つのアルゴリズムがあります。 ステミングとは、ヒューリスティック分析を指し、ベースは使用しません。 見出し語化では、さまざまな単語ベースが使用され、文法規則に従った変換も適用されます。 結果の誤差は停滞時よりもはるかに小さいため、目的に応じて補題を使用します。
見出し語化については、すでにここやここなど、habrに関する記事がいくつかありました 。 彼らはAOTベースを使用しています。 繰り返したくありませんでした。また、他の見出し語化のベースを探すのも面白かったです。 WordNetについてお話ししたいと思いますが、その上で補題を作成します。 まず、 公式のWordNet Webサイトで、プログラムのソースコードとデータベース自体をダウンロードできます。 WordNetには多くの機能がありますが、必要な機能はごく一部、つまり単語の正規化だけです。
データベースのみが必要です。 WordNetのソースプロセス(C)は、正規化プロセス自体を説明しています。本質的には、そこからアルゴリズムを取り出し、Pythonで書き直しました。 ああ、もちろん、Python用のWordNet用のライブラリ-nltkがありますが、まず、Python 2.7でのみ動作し、次に見た限り、正規化ではWordNetサーバーへのリクエストのみが送信されます。
レンマタイザーの一般的なクラス図:
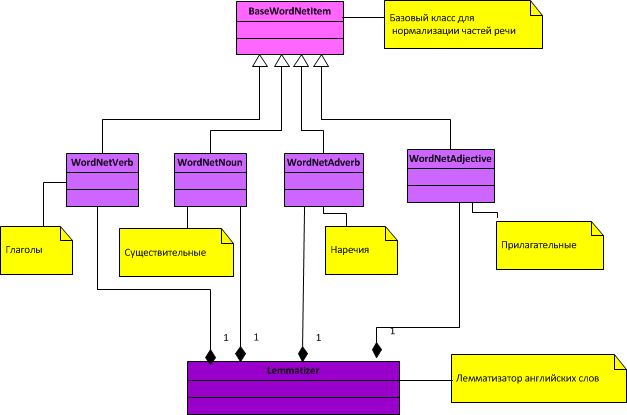
図からわかるように、正規化されているのは4つの品詞(名詞、動詞、形容詞、副詞)だけです。
正規化プロセスを簡単に説明すると、次のようになります。
1.品詞ごとに、2つのファイルがWordNetからダウンロードされます-インデックス辞書(品詞に応じた名前インデックスと拡張子、副詞の場合はindex.advなど)と例外ファイル(品詞に応じた拡張子excと名前、たとえばadv.excの場合)副詞)。
2.正規化中に、例外の配列が最初にチェックされ、単語が存在する場合、その正規化された形式が返されます。 単語が例外ではない場合、単語のゴーストは文法規則に従って始まります。つまり、語尾が切り捨てられ、新しい語尾が接着され、次に単語がインデックス配列で検索され、そこにある場合、単語は正規化されたと見なされます。 それ以外の場合、ルールが終了するか、単語が以前に正規化されるまで、次のルールが適用されます。
Lemmalizerのクラス:
品詞の基本クラスBaseWordNetItem.py
# -*- coding: utf-8 -*- import os class BaseWordNetItem: # def __init__(self, pathWordNetDict, excFile, indexFile): self.rule=() # . self.wordNetExcDict={} # self.wordNetIndexDict=[] # self.excFile = os.path.join(pathWordNetDict, excFile) # self.indexFile = os.path.join(pathWordNetDict, indexFile) # self.__ParseFile(self.excFile, self.__AppendExcDict) # self.__ParseFile(self.indexFile, self.__AppendIndexDict) # self.cacheWords={} # . , - , - # . # : [-][][] def __AppendExcDict(self, line): # , 2 ( - , - ). group = [item.strip() for item in line.replace("\n","").split(" ")] self.wordNetExcDict[group[0]] = group[1] # . def __AppendIndexDict(self, line): # group = [item.strip() for item in line.split(" ")] self.wordNetIndexDict.append(group[0]) # , , def __ParseFile(self, file, contentHandler): try: with open(file, 'r') as openFile: for line in openFile: contentHandler(line) # except Exception as e: raise Exception('File does not load: "%s"' %file) # . , . # def _GetDictValue(self, dict, key): try: return dict[key] except KeyError: return None # , True, False. # , , , ( ). def _IsDefined(self, word): if word in self.wordNetIndexDict: return True return False # ( ) def GetLemma(self, word): word = word.strip().lower() # if word == None: return None # , lemma = self._GetDictValue(self.cacheWords, word) if lemma != None: return lemma # , , if self._IsDefined(word): return word # , , lemma = self._GetDictValue(self.wordNetExcDict, word) if lemma != None: return lemma # , , . lemma = self._RuleNormalization(word) if lemma != None: self.cacheWords[word] = lemma # return lemma return None # ( , ) def _RuleNormalization(self, word): # , , , . for replGroup in self.rule: endWord = replGroup[0] if word.endswith(endWord): lemma = word # lemma = lemma.rstrip(endWord) # lemma += replGroup[1] # if self._IsDefined(lemma): # , , , return lemma return None
動詞を正規化するためのクラスWordNetVerb.py
# -*- coding: utf-8 -*- from WordNet.BaseWordNetItem import BaseWordNetItem # # BaseWordNetItem class WordNetVerb(BaseWordNetItem): def __init__(self, pathToWordNetDict): # (BaseWordNetItem) BaseWordNetItem.__init__(self, pathToWordNetDict, 'verb.exc', 'index.verb') # . , "s" "" , "ies" "y" . self.rule = ( ["s" , "" ], ["ies" , "y" ], ["es" , "e" ], ["es" , "" ], ["ed" , "e" ], ["ed" , "" ], ["ing" , "e" ], ["ing" , "" ] ) # GetLemma(word) BaseWordNetItem
名詞の正規化のためのクラスWordNetNoun.py
# -*- coding: utf-8 -*- from WordNet.BaseWordNetItem import BaseWordNetItem # # BaseWordNetItem class WordNetNoun(BaseWordNetItem): def __init__(self, pathToWordNetDict): # (BaseWordNetItem) BaseWordNetItem.__init__(self, pathToWordNetDict, 'noun.exc', 'index.noun') # . , "s" "", "ses" "s" . self.rule = ( ["s" , "" ], ["'s" , "" ], ["'" , "" ], ["ses" , "s" ], ["xes" , "x" ], ["zes" , "z" ], ["ches" , "ch" ], ["shes" , "sh" ], ["men" , "man" ], ["ies" , "y" ] ) # ( ) # BaseWordNetItem, , # def GetLemma(self, word): word = word.strip().lower() # , if len(word) <= 2: return None # "ss", if word.endswith("ss"): return None # , lemma = self._GetDictValue(self.cacheWords, word) if lemma != None: return lemma # , , if self._IsDefined(word): return word # , , lemma = self._GetDictValue(self.wordNetExcDict, word) if (lemma != None): return lemma # "ful", "ful", , . # , , "spoonsful" "spoonful" suff = "" if word.endswith("ful"): word = word[:-3] # "ful" suff = "ful" # "ful", # , , . lemma = self._RuleNormalization(word) if (lemma != None): lemma += suff # "ful", self.cacheWords[word] = lemma # return lemma return None
副詞WordNetAdverb.pyを正規化するためのクラス
# -*- coding: utf-8 -*- from WordNet.BaseWordNetItem import BaseWordNetItem # # BaseWordNetItem class WordNetAdverb(BaseWordNetItem): def __init__(self, pathToWordNetDict): # (BaseWordNetItem) BaseWordNetItem.__init__(self, pathToWordNetDict, 'adv.exc', 'index.adv') # (adv.exc) (index.adv). # .
形容詞WordNetAdjective.pyを正規化するためのクラス
# -*- coding: utf-8 -*- from WordNet.BaseWordNetItem import BaseWordNetItem # # BaseWordNetItem class WordNetAdjective(BaseWordNetItem): def __init__(self, pathToWordNetDict): # (BaseWordNetItem) BaseWordNetItem.__init__(self, pathToWordNetDict, 'adj.exc', 'index.adj') # . , "er" "" "e" . self.rule = ( ["er" , "" ], ["er" , "e"], ["est" , "" ], ["est" , "e"] ) # GetLemma(word) BaseWordNetItem
Lemmatizer Lemmatizer.pyのクラス
# -*- coding: utf-8 -*- from WordNet.WordNetAdjective import WordNetAdjective from WordNet.WordNetAdverb import WordNetAdverb from WordNet.WordNetNoun import WordNetNoun from WordNet.WordNetVerb import WordNetVerb class Lemmatizer: def __init__(self, pathToWordNetDict): # self.splitter = "-" # adj = WordNetAdjective(pathToWordNetDict) # noun = WordNetNoun(pathToWordNetDict) # adverb = WordNetAdverb(pathToWordNetDict) # verb = WordNetVerb(pathToWordNetDict) # self.wordNet = [verb, noun, adj, adverb] # (, ) def GetLemma(self, word): # , , ( ) , wordArr = word.split(self.splitter) resultWord = [] for word in wordArr: lemma = self.__GetLemmaWord(word) if (lemma != None): resultWord.append(lemma) if (resultWord != None): return self.splitter.join(resultWord) return None # ( ) def __GetLemmaWord(self, word): for item in self.wordNet: lemma = item.GetLemma(word) if (lemma != None): return lemma return None
さて、正規化が終了しました。 これで、周波数アナライザーは単語を正規化できます。 タスクの最後の部分-英語の単語の翻訳と転写を取得します。
StarDict辞書を使用した外国語翻訳者
StarDictについては長い間書くことができますが、この形式の主な利点は、ほとんどすべての言語で多くの辞書データベースがあることです。 HabrのStarDictトピックに関する記事はありませんでした。このギャップを埋める時が来ました。 StarDict形式を記述するファイルは通常、ソース自体の隣にあります。
すべての追加を破棄する場合、この形式で最も最小限の知識セットは次のようになります。
各辞書には3つの必須ファイルが含まれている必要があります。
1. ifo拡張子を持つファイル-辞書自体の一貫した説明が含まれています。
2.拡張子がidxのファイル。 idxファイル内の各エントリは、次々に続く3つのフィールドで構成されます。
- word_str -'\ 0'で終わるutf-8形式の文字列。
- word_data_offset- .dictファイルに書き込む前のオフセット(32または64ビットサイズ)。
- word_data_size -.dictファイルのエントリ全体のサイズ。
3. dict拡張子を持つファイル-翻訳自体が含まれています。翻訳へのオフセットを知ることでアクセスできます(オフセットはidxファイルに記録されます)。
最終的にどのクラスになるかについて考え直すことなく、ファイルごとに1つのクラスを作成し、それらを結合する1つの一般的なStarDictクラスを作成しました。
結果のクラス図:

StarDictのクラス:
辞書エントリの基本クラスBaseStarDictItem.py
# -*- coding: utf-8 -*- import os class BaseStarDictItem: def __init__(self, pathToDict, exp): # self.encoding = "utf-8" # self.dictionaryFile = self.__PathToFileInDirByExp(pathToDict, exp) # self.realFileSize = os.path.getsize(self.dictionaryFile) # path exp def __PathToFileInDirByExp(self, path, exp): if not os.path.exists(path): raise Exception('Path "%s" does not exists' % path) end = '.%s'%(exp) list = [f for f in os.listdir(path) if f.endswith(end)] if list: return os.path.join(path, list[0]) # else: raise Exception('File does not exist: "*.%s"' % exp)
クラスifo.py
# -*- coding: utf-8 -*- from StarDict.BaseStarDictItem import BaseStarDictItem from Frequency.IniParser import IniParser class Ifo(BaseStarDictItem): def __init__(self, pathToDict): # (BaseStarDictItem) BaseStarDictItem.__init__(self, pathToDict, 'ifo') # self.iniParser = IniParser(self.dictionaryFile) # ifo # , self.bookName = self.__getParameterValue("bookname", None) # [ ] self.wordCount = self.__getParameterValue("wordcount", None) # ".idx" [ ] self.synWordCount = self.__getParameterValue("synwordcount", "") # ".syn" [ , ".syn"] self.idxFileSize = self.__getParameterValue("idxfilesize", None) # ( ) ".idx" . , [ ] self.idxOffsetBits = self.__getParameterValue("idxoffsetbits", 32) # (32 64), .dict. 3.0.0, 32 [ ] self.author = self.__getParameterValue("author", "") # [ ] self.email = self.__getParameterValue("email", "") # [ ] self.description = self.__getParameterValue("description", "") # [ ] self.date = self.__getParameterValue("date", "") # [ ] self.sameTypeSequence = self.__getParameterValue("sametypesequence", None) # , [ ] self.dictType = self.__getParameterValue("dicttype", "") # , WordNet[ ] def __getParameterValue(self, key, defaultValue): try: return self.iniParser.GetValue(key) except: if defaultValue != None: return defaultValue raise Exception('\n"%s" has invalid format (missing parameter: "%s")' % (self.dictionaryFile, key))
クラスidx.py
# -*- coding: utf-8 -*- from struct import unpack from StarDict.BaseStarDictItem import BaseStarDictItem class Idx(BaseStarDictItem): # def __init__(self, pathToDict, wordCount, idxFileSize, idxOffsetBits): # (BaseStarDictItem) BaseStarDictItem.__init__(self, pathToDict, 'idx') self.idxDict ={} # , self.idxDict = {'.': [_____dict, _____dict], ...} self.idxFileSize = int(idxFileSize) # .idx, .ifo self.idxOffsetBytes = int(idxOffsetBits/8) # , .dict. self.wordCount = int(wordCount) # ".idx" # ( .ifo .idx [idxfilesize] ) self.__CheckRealFileSize() # self.idxDict .idx self.__FillIdxDict() # ( .ifo [wordcount] .idx ) self.__CheckRealWordCount() # , .ifo , def __CheckRealFileSize(self): if self.realFileSize != self.idxFileSize: raise Exception('size of the "%s" is incorrect' %self.dictionaryFile) # , .ifo , .idx def __CheckRealWordCount(self): realWordCount = len(self.idxDict) if realWordCount != self.wordCount: raise Exception('word count of the "%s" is incorrect' %self.dictionaryFile) # , def __getIntFromByteArray(self, sizeInt, stream): byteArray = stream.read(sizeInt) # , # formatCharacter = 'L' # "unsigned long" ( sizeInt = 4) if sizeInt == 8: formatCharacter = 'Q' # "unsigned long long" ( sizeInt = 8) format = '>' + formatCharacter # : " " + " " # '>' - , int( formatCharacter) . integer = (unpack(format, byteArray))[0] # return int(integer) # .idx ( 3- ) self.idxDict def __FillIdxDict(self): languageWord = "" with open(self.dictionaryFile, 'rb') as stream: while True: byte = stream.read(1) # if not byte: break # , if byte != b'\0': # '\0', languageWord += byte.decode("utf-8") else: # '\0', , (" dict" " dict") wordDataOffset = self.__getIntFromByteArray(self.idxOffsetBytes, stream) # " dict" wordDataSize = self.__getIntFromByteArray(4, stream) # " dict" self.idxDict[languageWord] = [wordDataOffset, wordDataSize] # self.idxDict : + + languageWord = "" # , # .dict (" dict" " dict"). # , None def GetLocationWord(self, word): try: return self.idxDict[word] except KeyError: return [None, None]
クラスDict.py
# -*- coding: utf-8 -*- from StarDict.BaseStarDictItem import BaseStarDictItem # ( , sametypesequence = tm). # -x ( utf-8, '\0'): # 'm' - utf-8, '\0' # 'l' - utf-8, '\0' # 'g' - Pango # 't' - utf-8, '\0' # 'x' - utf-8, xdxf # 'y' - utf-8, (YinBiao) (KANA) # 'k' - utf-8, KingSoft PowerWord XML # 'w' - MediaWiki # 'h' - Html # 'n' - WordNet # 'r' - . (jpg), (wav), (avi), (bin) . # 'W' - wav # 'P' - # 'X' - class Dict(BaseStarDictItem): def __init__(self, pathToDict, sameTypeSequence): # (BaseStarDictItem) BaseStarDictItem.__init__(self, pathToDict, 'dict') # , self.sameTypeSequence = sameTypeSequence def GetTranslation(self, wordDataOffset, wordDataSize): try: # .dict self.__CheckValidArguments(wordDataOffset, wordDataSize) # .dict with open(self.dictionaryFile, 'rb') as file: # file.seek(wordDataOffset) # , byteArray = file.read(wordDataSize) # , return byteArray.decode(self.encoding) # o (self.encoding BaseDictionaryItem) except Exception: return None def __CheckValidArguments(self, wordDataOffset, wordDataSize): if wordDataOffset is None: pass if wordDataOffset < 0: pass endDataSize = wordDataOffset + wordDataSize if wordDataOffset < 0 or wordDataSize < 0 or endDataSize > self.realFileSize: raise Exception
さて、翻訳者は準備ができています。今度は、周波数アナライザ、ワードノーマライザ、およびトランスレータを組み合わせる必要があります。main.pyファイルとSettings.ini設定ファイルを作成します。
メインファイルmain.py
# -*- coding: utf-8 -*- import os import xlwt3 as xlwt from Frequency.IniParser import IniParser from Frequency.FrequencyDict import FrequencyDict from StarDict.StarDict import StarDict ConfigFileName="Settings.ini" class Main: def __init__(self): self.listLanguageDict = [] # StarDict self.result = [] # ( , , ) try: # - config = IniParser(ConfigFileName) self.pathToBooks = config.GetValue("PathToBooks") # ini PathToBooks, (, ), self.pathResult = config.GetValue("PathToResult") # ini PathToResult, self.countWord = config.GetValue("CountWord") # ini CountWord, , self.pathToWordNetDict = config.GetValue("PathToWordNetDict") # ini PathToWordNetDict, WordNet self.pathToStarDict = config.GetValue("PathToStarDict") # ini PathToStarDict, StarDict # StarDict . listPathToStarDict listPathToStarDict = [item.strip() for item in self.pathToStarDict.split(";")] # StarDict for path in listPathToStarDict: languageDict = StarDict(path) self.listLanguageDict.append(languageDict) # , self.listBooks = self.__GetAllFiles(self.pathToBooks) # self.frequencyDict = FrequencyDict(self.pathToWordNetDict) # , StarDict WordNet. , , self.__Run() except Exception as e: print('Error: "%s"' %e) # , path def __GetAllFiles(self, path): try: return [os.path.join(path, file) for file in os.listdir(path)] except Exception: raise Exception('Path "%s" does not exists' % path) # , . , def __GetTranslate(self, word): valueWord = "" for dict in self.listLanguageDict: valueWord = dict.Translate(word) if valueWord != "": return valueWord return valueWord # ( , , ) countWord Excel def __SaveResultToExcel(self): try: if not os.path.exists(self.pathResult): raise Exception('No such directory: "%s"' %self.pathResult) if self.result: description = 'Frequency Dictionary' style = xlwt.easyxf('font: name Times New Roman') wb = xlwt.Workbook() ws = wb.add_sheet(description + ' ' + self.countWord) nRow = 0 for item in self.result: ws.write(nRow, 0, item[0], style) ws.write(nRow, 1, item[1], style) ws.write(nRow, 2, item[2], style) nRow +=1 wb.save(os.path.join(self.pathResult, description +'.xls')) except Exception as e: print(e) # def __Run(self): # for book in self.listBooks: self.frequencyDict.ParseBook(book) # countWord mostCommonElements = self.frequencyDict.FindMostCommonElements(self.countWord) # for item in mostCommonElements: word = item[0] counterWord = item[1] valueWord = self.__GetTranslate(word) self.result.append([counterWord, word, valueWord]) # Excel self.__SaveResultToExcel() if __name__ == "__main__": main = Main()
Settings.ini設定ファイル
; (, ), PathToBooks = e:\Bienne\Frequency\Books ; WordNet( ) PathToWordNetDict = e:\Bienne\Frequency\WordNet\wn3.1.dict\ ; StarDict( ) PathToStarDict = e:\Bienne\Frequency\Dict\stardict-comn_dictd04_korolew ; , Excel CountWord = 100 ; , ( Excel - , , ) PathToResult = e:\Bienne\Frequency\Books
ダウンロードして追加でインストールする必要がある唯一のサードパーティライブラリはxlwtです。Excel形式のファイルを作成する必要があります(結果はそこに書き込まれます)。
PathToStarDict変数のSettings.ini設定ファイルでは、「;」を使用して複数の辞書を作成できます。この場合、単語は辞書の順に検索されます-単語が最初の辞書で見つかった場合、検索は終了します。それ以外の場合、他のすべてのStarDict辞書が検索されます。
あとがき
この記事で説明されているすべてのソースは、githubからダウンロードできます。
通知:
- スクリプトはウィンドウの下に書かれました。
- 使用されたpython 3.3 ;
- さらに、xlwtライブラリをExcelで動作するように配置する必要があります。
- 個別に、WordNetおよびStarDictの辞書データベースをダウンロードする必要があります(StarDict辞書の場合は、アーカイブされたパックファイルをdict拡張子でさらに解凍する必要があります)。
- Settings.iniファイルで、辞書のパスと結果を保存する場所を指定する必要があります。
- , StarDict, ( ).