インメモリデータグリッド ( IMDG )のタスクは、分散状態でランダムアクセスメモリにデータを保存することにより、非常に高いデータ可用性を提供することです。 最新のIMDGは、大量のデータを処理するためのほとんどの要件を満たすことができます。
簡単に言えば、 IMDGは、通常のマルチスレッドハッシュテーブルとのインターフェースが類似した分散オブジェクトストレージです。 オブジェクトはキーで保存します。 ただし、キーと値がデータタイプ「バイト配列」と「文字列」によって制限される従来のシステムとは異なり、IMDGでは、ビジネスモデルの任意のオブジェクトをキーまたは値として使用できます。 これにより、柔軟性が大幅に向上し、代替テクノロジで必要な追加のシリアル化/逆シリアル化を行わずに、ビジネスロジックが動作するオブジェクトをデータグリッドに正確に格納できます。 また、ほとんどの場合、通常のハッシュテーブルとして分散データウェアハウスを操作できるため、データグリッドの使用が簡素化されます。 ビジネスモデルのオブジェクトを直接操作する機能は、 IMDGとインメモリデータベース ( IMDB )の主な違いの1つです。 後者の場合、ユーザーは依然としてオブジェクトリレーショナルマッピング(オブジェクトからリレーショナルへのマッピング)を実行する必要があります。これにより、原則として、パフォーマンスが大幅に低下します。
IMDB、NoSql、NewSqlデータベースなど、IMDGと他の製品を区別する他の機能があります。 主なものの1つは、クラスター内の真にスケーラブルなデータパーティション分割です。 IMDGは基本的に、各キーがクラスター内の厳密に定義されたサーバーに保存される分散ハッシュテーブルです。 クラスターが大きいほど、より多くのデータをクラスターに格納できます。 このアーキテクチャで基本的に重要なのは、クラスター全体での移動を排除(または最小化)する(ローカルに)同じサーバーでデータを処理することです。 実際、適切に設計されたIMDGを使用する場合、クラスターに新しいサーバーを追加するか、既存のサーバーを削除しない限り、データの移動は完全になくなり、クラスタートポロジとそのデータ分散が変更されます。
以下の図は、一連のキー{k1、k2、k3}を持つ従来のIMDGを示しています。各キーは別々のサーバーに属します。 外部データベースはオプションです。 IMDGが存在する場合、IMDGは原則として、データベースからデータを自動的に読み取るか、データベースに書き込みます。
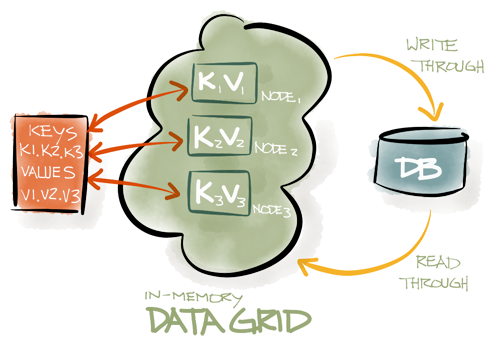
IMDGのもう1つの特徴は、 ACIDの要件( 原子性、一貫性、分離、耐久性-原子性、整合性、分離、保存 )を満たすトランザクション 性のサポートです。 原則として、クラスター内のデータの整合性を保証するために、2フェーズコミット(2フェーズコミットまたは2PC)が使用されます。 IMDGごとにロックメカニズムが異なる場合がありますが、最も高度な実装では通常、パラレルロックを使用します(たとえば、 GridGainはMVCC-マルチバージョン同時実行制御、マルチバージョン管理を使用した同時アクセスの制御を使用します)。これにより、ネットワーク交換を最小限に抑え、トランザクションのACID整合性を保証します高いパフォーマンスを維持しながら。
データの整合性は、 IMDGデータベースとNoSQLデータベースの主な違いの1つです。 ほとんどの場合、 NoSQLデータベースは、結果整合性(EC )と呼ばれるアプローチを使用して設計されます。このアプローチでは、データはしばらくの間一貫性のない状態になる場合がありますが、時間の経過とともに必然的に一貫したものになります。 一般に、ECシステムでの書き込み操作は、遅い読み取り操作に比べて十分に高速です(より正確には、書き込み操作より高速ではありません)。 * 最適化された * 2PCを備えた最近のIMDGは、少なくとも書き込み速度の点でECシステムに対応し(それらよりも先に進んでいない場合)、読み取り速度が大幅に上回っています。 おもしろいことに、業界はそれでもまだ遅い2PCからECに移行し、今ではECからはるかに高速な* 最適化された * 2PCに移行し、完全な円を描いています。
製品ごとに異なる2PC最適化が提供される場合がありますが、一般に、すべての最適化のタスクは、同時実行性の向上、ネットワーク通信の最小化、トランザクションの完了に必要なロック数の削減です。 たとえば、Googleの分散型Spannerグローバルデータベースは、2PCがMapReduceやECと比較してデータの整合性と高いスループットを保証するためのより高速で簡単な方法を提供したという理由だけで、トランザクション2PCアプローチに基づいています。
通常、異なるIMDGには多くの共通の基本機能がありますが、メーカーによって異なる追加の機能や実装の詳細が多数あります。 IMDG製品を評価するときは、立ち退きポリシー、サーバーの起動時((事前)読み込み手法)を含むデータ読み込み手法、同時再パーティション化、ストレージに必要な追加メモリ量に注意してくださいレコード(データオーバーヘッド)など。 また、実行時にキャッシュを照会する機能にも注意してください。 GridGainなどの一部のIMDGでは、 分散結合をサポートする通常のSQLを使用して、ユーザーがメモリに格納されたデータを照会できるようにします。これは非常にまれです。
IMDGでのデータの保存は、インメモリアーキテクチャに必要な機能の半分にすぎません。 IMDGに保存されたデータも、並列かつ高速で処理する必要があります。 典型的なインメモリアーキテクチャは、IMDGを使用してクラスター内のデータをパーティション分割し、実行可能なコードが、必要なデータがあるサーバーに送信されます。 実行可能コード(計算タスク)は通常Compute Gridsの一部であり、正しくデプロイされ、負荷のバランスをとる(負荷分散)、耐障害性( フェールオーバー )を持ち、スケジュールどおりに実行できる必要があるため( スケジューリング )、 計算グリッドとIMDGの統合は非常に重要です。 IMDGとCompute Gridが同じ製品の一部であり、同じAPIを使用している場合、最大の効果が得られます。 これにより、開発者の統合の負担がなくなり、通常、インメモリソリューションの最高のパフォーマンスと信頼性を実現できます。
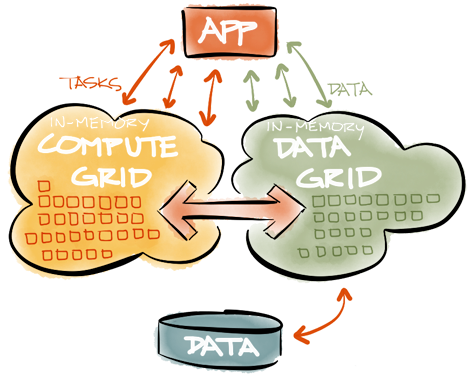
IMDG(Compute Gridとともに)は、リスク分析(リスク分析)、取引システム(取引システム)、リアルタイムの不正防止システム(不正検出)、生体認証(生体認証)、eコマース( eコマース)、オンラインゲーム(オンラインゲーム)。 実際、スケーラビリティとパフォーマンスの問題に直面している製品はすべて、インメモリ処理とIMDGアーキテクチャの使用から恩恵を受けることができます。