非常に短い歴史
限られたボルツマンマシン(RBM)の起源の歴史に特に焦点を当てるつもりはありません。それはすべて、トレーニングが非常に難しいフィードバックネットワークであるリカレントニューラルネットワークで始まったことにのみ言及します。 学習におけるこのわずかな困難のために、人々はより単純な学習アルゴリズムを適用できるより限定された再発モデルを発明し始めました。 これらのモデルの1つはホップフィールドニューラルネットワークであり、彼はニューラルネットワークダイナミクスを熱力学と比較することにより、ネットワークエネルギーの概念を導入しました。
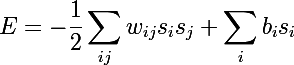
- w-ニューロン間の重み
- b-ニューロンの変位
- sはニューロンの状態です
RBMへの道の次のステップは、通常のボルツマンマシンでした。ホップフィールドネットワークとは性質が確率的であり 、ニューロンは観測可能な状態と隠れた状態を記述する2つのグループに分けられます( 隠れマルコフモデルとの類推により、そこから彼は「隠された」という言葉を借りました。 ボルツマンマシンのエネルギーは次のように表されます。
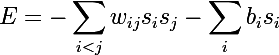
ボルツマンマシンは完全に接続された無向グラフであるため、同じグループの2つの頂点は互いに依存しています。

しかし、 2部グラフを得るためにグループ内の結合を削除すると、RBMモデルの構造が得られます。

このモデルの特徴は、あるグループのニューロンの特定の状態では、別のグループのニューロンの状態は互いに独立していることです。 次に、このプロパティが重要な役割を果たす理論に移ります。
解釈と目的
RBMは、マルコフの隠れたモデルと同様に解釈されます。 観察できる状態(外部環境と通信するためのインターフェイスを提供する可視ニューロン)と隠れている状態がいくつかあり、それらの状態を直接見ることはできません(隠されたニューロン)。 しかし、観察可能な状態に基づいて、潜在状態に関する確率的結論を引き出すことができます。 そのようなモデルをトレーニングした後、目に見える状態について結論を導き、隠れた状態(誰もベイズの定理 =をキャンセルしていない)を知って、モデルがトレーニングされている確率分布からデータを生成する機会を得ます。
したがって、モデルトレーニングの目標を定式化できます。初期状態からの再構築されたベクトルが元に最も近くなるようにモデルパラメーターを調整する必要があります。 再構成されたとは、隠れ状態からの確率的推論によって得られたベクトルを指し、観測された状態からの確率的推論によって得られます。 元のベクトルから。
理論
次の表記法を紹介します。
- w_ij -i番目のニューロン間の重み
- a_i-可視ニューロンの変位
- b_j-隠されたニューロンの変位
- v_i-可視ニューロンの状態
- h_j-隠されたニューロンの状態
バイナリベクトルで構成されるトレーニングセットを検討しますが、これは実数のベクトルに簡単に一般化できます。 可視ニューロンがn個、隠れニューロンがm個あるとします。 RBMのエネルギーの概念を紹介します。
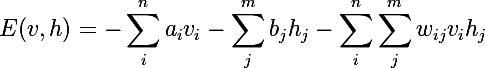
ニューラルネットワークは、 vとhのあらゆる種類の結合確率を次のように計算します。

ここで、 Zは次の形式のパーティション関数の合計またはノーマライザーです(N個のイメージvとM個のイメージhのみがあるとします)。

明らかに、ベクトルvの合計確率は、すべてのhを合計することによって計算されます。

与えられたvに対して、隠れ状態h_k = 1の1つである確率を考慮してください。 これを行うには、1つのニューロンを想像すると、1のシステムのエネルギーはE1になり、0の場合はE0になり、確率1は、現在のニューロンとオフセットの検査対象の層の状態ベクトルの線形結合のシグモイド関数に等しくなります:
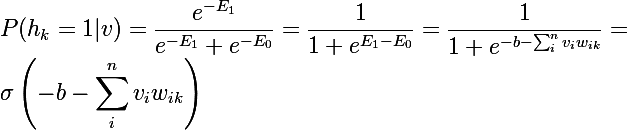
そして、与えられたvについて、すべてのh_kは互いに独立しているため、

同様の結論が、与えられたhの確率vについてもなされます。
思い出すように、トレーニングの目標は、再構成されたベクトルを元のベクトルに最も近づけること、つまり、確率p(v)を最大化することです。 このためには、モデルパラメーターに関する確率の偏導関数を計算する必要があります。 モデルのパラメーターに応じたエネルギーの微分から始めましょう:
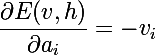
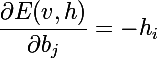
また、負のエネルギーの指数の導関数が必要になります。

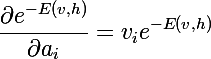

パーティション関数を区別します:
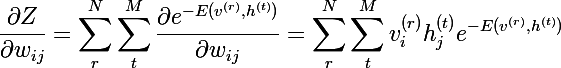
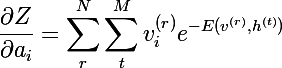

私たちはほとんどそこにいます-)重みに関して確率vの偏導関数を考えます:
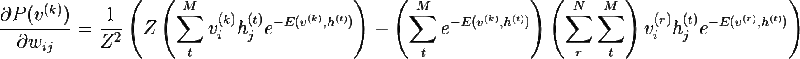
明らかに、確率を最大化することは確率の対数を最大化することと同じです。このトリックは、あなたが美しい解決策を見つけるのに役立ちます。 重量による自然対数の導関数を考えます:
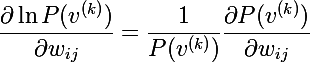
最後の2つの式を組み合わせて、次の式を取得します。
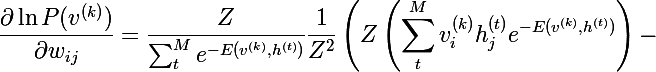
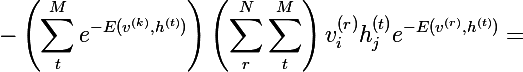

各項の分子と分母にZを掛け、それを確率に単純化すると、次の式が得られます。

そして、 数学的期待値の定義により、最終式が得られます(角括弧の前のMは期待値の記号です)。
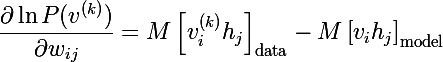
ニューロンの変位に関する微分も同様に導出されます。
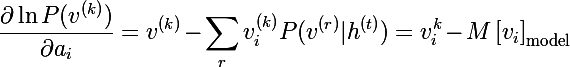

最後に、モデルパラメータを更新するための3つのルールがあります。 これは学習速度です。
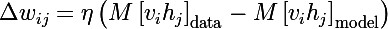
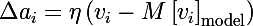

インデックスでのPSフライは間違っている可能性があります。habrには組み込みがありません
 エディター=)
エディター=)
学習アルゴリズムの対照的発散
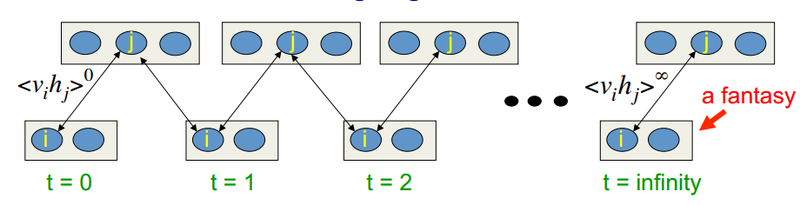
このアルゴリズムは2002年にヒントン教授によって発明されたもので、その単純さで注目に値します。 主な考え方は、数学的な期待は明確に定義された値に置き換えられるということです。 サンプリングプロセスの概念が導入されました(Gibbsサンプリング、関連性についてはこちらをご覧ください)。 CD-kプロセスは次のとおりです。
- 可視ニューロンの状態は入力画像と同等です
- 隠れた状態の確率が導出されます
- 隠れ層の各ニューロンには、現在の状態に等しい確率で「1」の状態が割り当てられます
- 可視層の確率は、非表示に基づいて導出されます
- 現在の反復がkより小さい場合、ステップ2に戻ります。
- 隠れた状態の確率が導出されます
ヒントンの講義では、次のようになります。
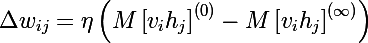
つまり サンプリングを長くすればするほど、勾配はより正確になります。 同時に、教授は、CD-1(サンプリングの1回の繰り返し)でさえ、かなり良い結果がすでに得られていると主張しています。 最初の項は正相と呼ばれ、マイナス記号がある第2項は負相と呼ばれます。
話は安いです。 コードを見せてください。
バックプロパゲーションアルゴリズムの実装と同様に、ほぼ同じインターフェイスを使用します。 それでは、ニューラルネットワークのトレーニングの機能をすぐに考えてみましょう。 慣性モーメントを使用してトレーニングを実施します。
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .

#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):

:

, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :

MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :


public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch
// foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them
for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation
string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch
// foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them
for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation
string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
-
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch// foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update themfor (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculationstring msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
-
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch// foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update themfor (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculationstring msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
-
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch// foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update themfor (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculationstring msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
-
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch// foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update themfor (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculationstring msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
-
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch// foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update themfor (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculationstring msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
-
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch// foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update themfor (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculationstring msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :