タスクと入力データについて簡単に
クラスターでは、以下を保持する必要があります。
- ユーザーがいる複数のWebサイトのDB
- これらのユーザーの統計情報を含むDB
- チケットシステム、プロジェクト管理システム、その他の些細なことのためのDB
言い換えると、MySQLで実行されているプロジェクトからのほぼすべてのプロジェクトのデータベースは、クラスター内に存在するはずです。
ほとんどのプロジェクトはDCにリモートで保持されるため、クラスターはそこに配置されます。
クラスタを地理的に異なるデータセンターに分散するタスクは、それだけの価値はありません。
クラスターを構築するために、同じ構成の3つのサーバーが使用されます:HP DL160 G6、2X Xeon E5620、24 GB RAM、ハードウェアRAID 10の4x SAS 300GB。
なぜパーコナなのか?
-同期真のマルチマスター複製(Galera)
-Perconaからの商用サポートの可能性
-最適化の印象的なリストを持つMySQLのフォーク
クラスター図
上記の物理サーバーごとに、クラスター内に3つのノードがあります(OS Ubuntu 12.04)。
keepalivedを使用して3つのサーバーすべてで共有される1つの仮想IPアドレスへの透過的な接続を使用します。 ノードの負荷を分散するために、 HAProxyが使用されます。もちろん、各サーバーにインストールされているため、一方のサーバーに障害が発生しても、VIPにより他方の負荷が引き続き分散されます。 LBおよびVIPにはクラスターと同じグランドを使用することを意図的に決定しました。
ノードAは参照(バックアップ)ノードとして使用され、アプリケーションはリクエストをロードしません。 同時に、彼女はクラスターの完全なメンバーになり、レプリケーションに参加します。 これは、クラスター障害またはデータ整合性違反が発生した場合、アプリケーションがアクセス不足のために破棄できなかった最も一貫性のあるデータをほぼ確実に含むノードがあるためです。 リソースの浪費のように思えるかもしれませんが、私たちにとっては、24時間年中無休の可用性よりも99%のデータの信頼性が依然として重要です。 この特定のノードをSST(状態スナップショット転送)に使用して、クラスターに接続された、または障害後に発生した新しいノードにダンプを自動的にダンプします。 さらに、ノードAはサーバーの優れた候補であり、標準の定期的なバックアップを削除します。
概略的に、これはすべて次のように表すことができます。
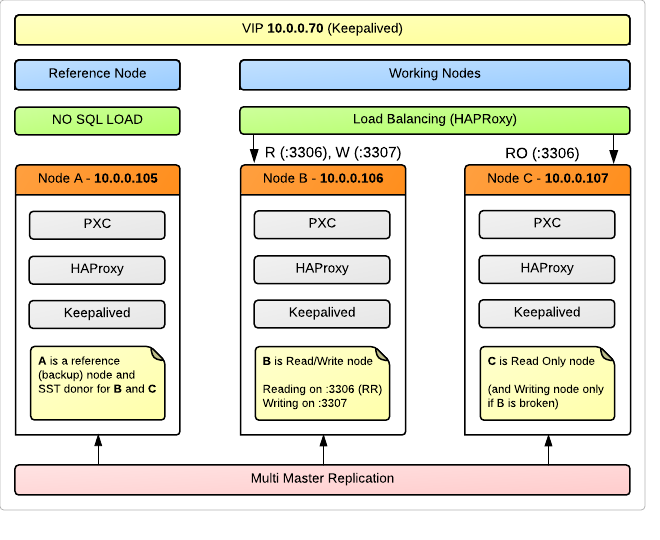
ノードBとノードCは負荷を保持する主力製品ですが、記録操作を処理するのはそのうちの1つだけです。 これは多くの専門家の推奨事項であり、以下でこの問題について詳しく説明します。
HAProxyおよびバランシングの詳細
HAProxyは、ノードBとCの間のラウンドロビンのポート3306に着信する要求をスキャンします。
3307に来るものは、 ノードBでのみプロキシされます。 ただし、 ノードBが突然クラッシュした場合、要求は指定されたノードCバックアップに送られます。
アイデアを実装するには(ノードの1つにのみ書き込む)、読み取り要求が10.0.0.70:07306(10.0.0.70はVIP)との接続を通過し、書き込み要求が10.0.0.70に送信されるようにアプリケーションを記述する必要があります。 3307 。
私たちの場合、これには、PHPアプリケーション設定で新しい接続を作成し、DBHandler変数の名前を別の値に置き換える作業が必要になります。 一般に、私たちが書いたアプリケーションにとってはそれほど難しくありません。 ベースもクラスター内にあるサードパーティプロジェクトの場合、デフォルトポート3307を指定するだけです。 これらのプロジェクトは小さな負荷を作成し、分散読み取り機能の損失はそれほど重要ではありません。
HAProxy構成( /etc/haproxy/haproxy.cfg ):
global log 127.0.0.1 local0 log 127.0.0.1 local1 notice maxconn 4096 chroot /usr/share/haproxy daemon defaults log global mode http option tcplog option dontlognull retries 3 option redispatch maxconn 2000 contimeout 5000 clitimeout 50000 srvtimeout 50000 frontend pxc-front bind 10.0.0.70:3306 mode tcp default_backend pxc-back frontend stats-front bind *:81 mode http default_backend stats-back frontend pxc-onenode-front bind 10.0.0.70:3307 mode tcp default_backend pxc-onenode-back backend pxc-back mode tcp balance leastconn option httpchk server c1 10.0.0.106:33061 check port 9200 inter 12000 rise 3 fall 3 server c2 10.0.0.107:33061 check port 9200 inter 12000 rise 3 fall 3 backend stats-back mode http balance roundrobin stats uri /haproxy/stats stats auth haproxy:password backend pxc-onenode-back mode tcp balance leastconn option httpchk server c1 10.0.0.106:33061 check port 9200 inter 12000 rise 3 fall 3 server c2 10.0.0.107:33061 check port 9200 inter 12000 rise 3 fall 3 backup backend pxc-referencenode-back mode tcp balance leastconn option httpchk server c0 10.0.0.105:33061 check port 9200 inter 12000 rise 3 fall 3
HAProxyがクラスターノードが生きているかどうかを判断するために、 clustercheckユーティリティが使用され(percona-xtradb-clusterパッケージに含まれています)、HTTP応答としてノードの状態に関する情報(同期/未同期)が表示されます。 各ノードで、xinetdサービスを構成する必要があります。
/etc/xinetd.d/mysqlchk
service mysqlchk { disable = no flags = REUSE socket_type = stream port = 9200 wait = no user = nobody server = /usr/bin/clustercheck log_on_failure += USERID only_from = 0.0.0.0/0 per_source = UNLIMITED }
/ etc /サービス
... # Local services mysqlchk 9200/tcp # mysqlchk
HAProxyはWebサーバーを起動し、統計を表示するためのスクリプトを提供します。これは、クラスターの状態を視覚的に監視するのに非常に便利です。
URLは次のようになります。
http:// VIP:81 / haproxy /統計ポート、および基本認証のログインとパスワードは、構成で指定されます。
HAProxyを介したバランシングを使用したクラスターのセットアップの問題については、 www.mysqlperformanceblog.com / 2012/06/20 / percona-xtradb-cluster-reference-architecture-with-haproxyをよく考慮してください。
KeepalivedとVIP
$ echo "net.ipv4.ip_nonlocal_bind=1" >> /etc/sysctl.conf && sysctl -p
/etc/keepalived/keepalived.conf
vrrp_script chk_haproxy { # Requires keepalived-1.1.13 script "killall -0 haproxy" # cheaper than pidof interval 2 # check every 2 seconds weight 2 # add 2 points of prio if OK } vrrp_instance VI_1 { interface eth0 state MASTER # SLAVE on backup virtual_router_id 51 priority 101 # 101 on master, 100 and 99 on backup virtual_ipaddress { 10.0.0.70 } track_script { chk_haproxy } }
ノード構成
すでにPXCのインストールとテストに関するHabrに関する記事があります: habrahabr.ru/post/152969で、両方の問題について詳しく説明しているので、インストールは省略します。 ただし、構成については説明します。
まず、すべてのノードで時刻を同期することを忘れないでください。 私はこの点を逃し、長い間、私のSSTがきつく垂れ下がっていた理由を理解できませんでした-開始し、プロセスでハングしましたが、実際には何も起こりませんでした。
ノードAの my.cnf (私の構成ではnode105です ):
[mysqld_safe] wsrep_urls=gcomm://10.0.0.106:4567,gcomm://10.0.0.107:4567 # wsrep_urls=gcomm://10.0.0.106:4567,gcomm://10.0.0.107:4567,gcomm:// # - , # , .. # , [mysqld] port=33061 bind-address=10.0.0.105 datadir=/var/lib/mysql skip-name-resolve log_error=/var/log/mysql/error.log binlog_format=ROW wsrep_provider=/usr/lib/libgalera_smm.so wsrep_slave_threads=16 wsrep_cluster_name=cluster0 wsrep_node_name=node105 wsrep_sst_method=xtrabackup wsrep_sst_auth=backup:password innodb_locks_unsafe_for_binlog=1 innodb_autoinc_lock_mode=2 innodb_buffer_pool_size=8G innodb_log_file_size=128M innodb_log_buffer_size=4M innodb-file-per-table
さらに、異なるパラメーターのみがあります。
ノードB (node106)
[mysqld_safe] wsrep_urls=gcomm://10.0.0.105:4567 [mysqld] bind-address=10.0.0.106 wsrep_node_name=node106 wsrep_sst_donor=node105
ノードC (node107)
[mysqld_safe] wsrep_urls=gcomm://10.0.0.105:4567 [mysqld] bind-address=10.0.0.107 wsrep_node_name=node107 wsrep_sst_donor=node105
最後の2つの構成では、クラスター内の最初のノードを探す場所(グループのすべてのメンバーが住んでいる場所を知っている)、および同期のために他のデータからではなく、そこから取得するデータをサーバーに明示的に指示します。
私が今停止したのはこの構成であり、徐々にプロジェクトをクラスターに転送します。 私は自分の経験についてさらに書き続けるつもりです。
問題のある問題
ここでは、すぐに答えが見つからなかった質問の概要を説明しますが、その答えは、テクノロジーを理解し、クラスターで正しく動作するために特に重要です。
クラスターで使用可能なすべてのノードから1つのノードに書き込むことが推奨されるのはなぜですか? 結局のところ、これはマルチマスターレプリケーションの考え方と矛盾しているように思われます。
この勧告を最初に目にしたとき、私は非常に怒っていました。 マルチマスターを心配せずに任意のノードに書き込むことができ、変更がすべてのノードに同期的に適用されることが保証されるような方法で想像しました。 しかし、このアプローチでは、クラスター全体のデッドロックが発生する可能性があるという厳しい現実があります。 長いトランザクションで同じデータが並行して変更される場合、特に高い確率。 なぜなら 私はまだこの問題の専門家ではありません。このプロセスを指で説明することはできません。 しかし、この問題がより詳細にカバーされている良い記事があります: Percona XtraDB Cluster:マルチノード書き込みと予期しないデッドロック
私自身のテストでは、すべてのノードでアグレッシブな記録を行うと、次々にレイダウンし、リファレンスノードのみが機能するようになりました。 実際、クラスターが機能しなくなったと言えます。 この場合、3番目のノードが負担を負う可能性があるため、これは確かにこのような構成のマイナスですが、データは安全で健全であり、最悪のシナリオでは、単一サーバーモードで手動で開始できます。
新しいノードを接続するときに、クラスター内の既存のノードのIPアドレスを指定する方法は?
これには2つのディレクティブがあります。
[mysqld_safe] wsrep_urls [mysqld] wsrep_cluster_address
最初に、私が正しく理解していれば、複数のノードアドレスを一度に指定する機能のために比較的最近Galeraによって追加されました。 基本的な違いはこれ以上ありません。
これらの指令の意味は、最初は私にとって特別な混乱を引き起こしました。
実際、多くのマニュアルでは、クラスタの最初のノードでwsrep_urlsの値を空にしておくことをお勧めしています。
それは間違っていることが判明した。 gcommの存在://は、新しいクラスターの初期化を意味します。 したがって、構成内の最初のノードの開始直後に、この値を削除する必要があります。 それ以外の場合、このノードを再起動した後、2つの異なるクラスターを取得し、そのうちの1つは最初のノードのみで構成されます。
私自身は、クラスターを開始および再起動するときに構成の順序を推測しました(既に詳細に説明しています)
1.ノードA: gcommで実行:// B、gcomm:// C、gcomm://
2.ノードA: gcommの削除://行末
3.ノードB、C: gcommで始まる:// A
注意:グループ通信要求のポート番号を指定する必要があります。デフォルトでは4567です。つまり、正しいエントリは次のとおりです。gcomm:// A:4567
SSTメソッドとして非ブロッキングxtrabackupを使用してドナーノードに書き込むことはできますか?
SST中、ドナーのクラスターチェックは、HTTP 503をそれぞれ発行します。HAProxyまたはこのユーティリティを使用してステータスを判断する別のLBに対して、ドナーノードは使用不可と見なされ、転送先のノードも同様になります。 ただし、この動作は、基本的に通常のbashスクリプトであるclustercheckを編集することで変更できます。
これは次のように行われます。
/ usr / bin / clustercheck
#AVAILABLE_WHEN_DONOR=0 AVAILABLE_WHEN_DONOR=1
注意:これは、 xtrabackupが SSTとして使用され、他の方法ではないことが確実な場合にのみ実行できることに注意してください。 私たちの場合、ドナーとして負荷のないノードを使用する場合、そのような編集はまったく意味がありません。
便利なリンク
Percona XtraDBクラスター
mysqlperfomanceblog.comのXtraDBクラスター
Perconaコミュニティフォーラム
Percona Discussion Googleグループ
ガレラウィキ