これらすべての問題を技術的に理解するには、データマイニングテクノロジーを使用した情報分析が適しています。 データマイニングクラスタリングを使用して顧客セグメンテーションプロセスを自動化することにより、企業は多くの質問に対する回答を見つけることができます。
会社が商品またはサービスの販売およびさらにアフターサービスに従事している場合のオプションを検討してください。 したがって、会社には販売している潜在的な顧客がいます。 また、サービスを受けているクライアントまたは以前にサービスを受けたクライアントもいます。 以前に販売しました。 簡単にするために、これらをカスタマーサービスと呼びます。
目的とアイデアを簡潔に説明します。 分析のために、複数の指標(15〜20)を取得する必要があります。これらの指標は潜在顧客であり、同時に顧客にサービスを提供しています。 また、サービス対象の顧客のみが持つ2〜3個のインジケータを選択する必要があります。これらはターゲットインジケータです。 サービス対象クライアントの配列でのデータマイニングのクラスタリングを分析するため。 出力では、独自の特性を持ついくつかのクラスターを取得します。 次に、ターゲットインジケーターに従ってクラスターをセグメントにグループ化し、マーケティング担当者が理解できる定義を提供します。 結果のモデルを分析し、潜在的な顧客に結果のクラスターを投影します。 出力では、セグメント化された潜在的な顧客を取得します。 受け取ったセグメントに基づいて、各顧客セグメントの販売戦略と方法論を構築できます。
この手法と、結果を達成するための一連の手順をより詳細に検討してみましょう。
分析する顧客指標を選択する
明らかに、そのような分析の自動化を考えている企業には、たとえば、会社にいる従業員の数、活動の種類、経理、弁護士など、大量のデータをクライアントに保存する優れた情報システム(IS)が必要です。 一般に、IPには数十、数百のそのようなインジケーターを格納できますが、特定の分析では、15〜20のインジケーターで十分な場合があります。
同時に提供され、潜在的な顧客に存在するインジケータを選択します。
選択された指標は関連性があります。 これらの指標のデータを定期的に更新することが可能であるべきです。 何らかの指標に関する情報を収集できない場合は、分析で使用しないでください。 分析を開始する前に、最新の情報を収集します。この手順に1〜2か月かかる場合でも価値があります。
カスタマーサービスのターゲットを選択する
たとえば、顧客サービスの期間、顧客の収益性、サービス製品など、クライアントがあなたにとって魅力的かどうかを明確に判断するサービス対象クライアントのいくつかのターゲットを定義します。 明らかに、これらの指標は、サービスを提供する顧客にのみ典型的です。 そのような指標はほとんどない場合があります(2-3)。主なことは、この指標が、たとえば長期的な収益性の観点からビジネスの魅力的なクライアントなど、目標に応じて望ましいセグメントを特徴付けることです。
グループ指標値
IPでは、選択したインジケータの値を数値データまたはさまざまなフィールドのセットの形式で保存できます。 分析のために、これらの値をグループにまとめるのが最適です。たとえば、会計士の数:1、2-5、6-9、10以上。
モデルを作成する顧客を選択します。
最初は、一連のサービス対象クライアントでのみ作業が実行されます。 数年、たとえば5年以上の顧客関係履歴を選択するのが最善です。 サンプル内の顧客が多いほど、結果はより正確になります。
選択したクライアントとその特性は、MS SQL Serverなどのデータベースに配置する必要があります。 最も単純なケースでは、1行が1クライアントであり、各テーブルフィールドは前の段階で選択されたインジケーターである1つのファクトテーブルになります。
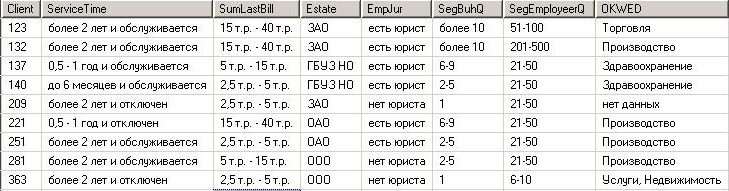
データを入力するとき、分析のために準備し、以前に実行した指標値のグループ化に従って変換する必要がある可能性が高いでしょう。
また、テーブルでは、これらの値をテキストの形式で保存できますが、より正確にはコードの形式-ディレクトリへのリンクです。 ファクトテーブルでは、SQL Server Integration Services(SSIS)などを使用して、T-sqlのスクリプトでデータを入力できます。
分析用のモデルを作成する
次に、たとえばSQL Server Business Intelligence Development Studio(BIDS)を使用して、データマイニングの分析用のモデルを作成する必要があります。 BIDSでモデルを作成する詳細な説明は、この記事の範囲外であり、標準のMicrosoftクラスタリングアルゴリズムを使用していることにのみ注意してください。
出力では、特定の数のクラスターを取得します。各クラスターは、選択した顧客インジケーターによって特徴付けられます。

結果のクラスターの特性値を強調表示します
各クラスターは、分析で使用されるすべてのインジケーターの特性値で記述される必要があります。これは、潜在顧客およびサービス提供顧客の特性です。 たとえば、クラスター1は、会計士2〜5の数、課税の予算タイプ、および医療活動のタイプによって特徴付けられます。 クラスターの説明にすべてのインジケーターの値が含まれていることが重要です。 1つのインジケータに複数の値が含まれている可能性があります。たとえば、単一のクラスタでは、ヘルスケアと教育のアクティビティのタイプを持つクライアントが近い可能性があります。 これは正常です、両方の値を取ります。

グループクラスター
次に、以前に選択されたサービス対象クライアントの同じターゲットターゲットインジケーターのコンテキストで、結果のクラスターを分析します。 実際、売り手が理解できる言語で各クラスターを記述するテーブルを作成できます。 たとえば、クラスター1-平均寿命を持ち、平均を超える月収を獲得している顧客、クラスター2-平均を超えて生活し、平均を下回る収入を獲得している顧客。 これらの説明と定式化はすべて、マーケティング分析の有能な分野にあります。 一部のクラスターは、ターゲットに従って同じグループに関連付けられている場合、グループ化できます。 結果のクラスターグループはセグメントと呼ばれます。
潜在顧客を選択する
セグメント化するすべての潜在的な顧客の配列を選択する必要があります。 一般的な場合、これらはすべて、販売のために従業員の仕事を入力できるすべての顧客です。
潜在顧客をクラスターに分散する
次に、クラスターごとに特別に作成されたプログラムコードを使用して、情報システムに保存されている分析されたインジケーターの値に基づいて、潜在的な顧客を連続的に選択します。 たとえば、クラスター1の特徴は、会計士2〜5の数、課税の予算タイプ、およびアクティビティヘルスケアのタイプです。 対応するIPフィールドにそのような値を持つすべてのクライアントを見つけ、それらをクラスター1に入れます。
実際には、次の3つの状況が発生します。
- クライアントは、1つのクラスターのみに一意に対応します。
- クライアントは2つ以上のクラスターに対応します。
- クライアントはどのクラスターにも分類されません。
これらの状況を考慮してください:
- 1つのクライアントが1つのクラスターのみに分類される場合、目的のクラスター値を記録し、それを忘れます。
- クライアントが2つ以上のクラスターに対応する場合、クライアントがより広範囲に対応するクラスターを分析する必要があります。 インジケーターのどの値が、比較されたクラスターをある程度特徴付けているかを知っています。 そして、特定のクライアントのインジケーターの値を知っています。 ここから、クライアントがどのクラスターに近いかを明確に判断し、そこに配置できます。 明らかに、これはすべてのクライアントに対して手動で行うのではなく、クラスター間の可能な交差点のオプションをプログラムで分析する必要があります。
- クライアントがクラスターに明示的に分類されない場合、クラスターを特徴付けるインジケーターの値のオプションを拡張する必要があります。 さらに、高度な特性により、クライアントが属するクラスターを判別できます。 たとえば、「会計士の数」インジケータに関するクラスター1は、「2〜5」の値によってより大きな範囲で特徴付けられますが、このクラスターは「6〜9」の値の特性も低くなります。 この値は、高度な分析に追加されます。
すべての比較のロジックは、SQL Server Business Intelligence Development Studioの[クラスターの識別]タブから明らかです。

結果
出口では、すべての潜在的な顧客が異なるセグメントに分散されています。 これらのセグメントの値はICに記録されます。 各セグメントについて、マーケティング部門は販売戦略と方法論を規定しています。
クラスター情報は定期的に更新することが重要です。 潜在的な顧客のIPの情報は毎日変化し、新しい顧客が現れ、適切なセグメントを付加する必要があります。 上記のロジックはすべて、プログラムコードのセットの形式で配置されます。 したがって、新規顧客のセグメントをすばやく自動的に計算することができます。 誰かが「オンザフライ」でこれを行う必要があります。クライアントをIPに導入するとき、誰かが1日に1回だけ行う必要があり、それはすべて特定のビジネスのニーズに依存します。
将来的には、データマイニングテクノロジーをIPに直接統合することにより、結果として得られるアルゴリズムを自己学習させることができます。 この場合、クラスタリングモデルは、サービスを提供するクライアントと切断されたクライアントの変化するデータから取得したISからの新しい情報に基づいて絶えず自己学習し、クラスタ全体で潜在的なクライアントの分布を調整します。