どういうわけか、vkontakteから音楽コレクションをダウンロードすることにしました(これはほぼ1000曲です)。 vk.apiに連絡したくなかったので、python + リクエストライブラリを使用することにしました。 それは何から来た-カットの下で!
まず、VKontakteオーディオ録音ページにアクセスしたときのブラウザーの動作を見てみましょう。 開発者ツール(私はChrome、F12を使用しました)を開き、 vk.com / audioにアクセスします。 ブラウザが行うすべてのリクエストを確認できます。
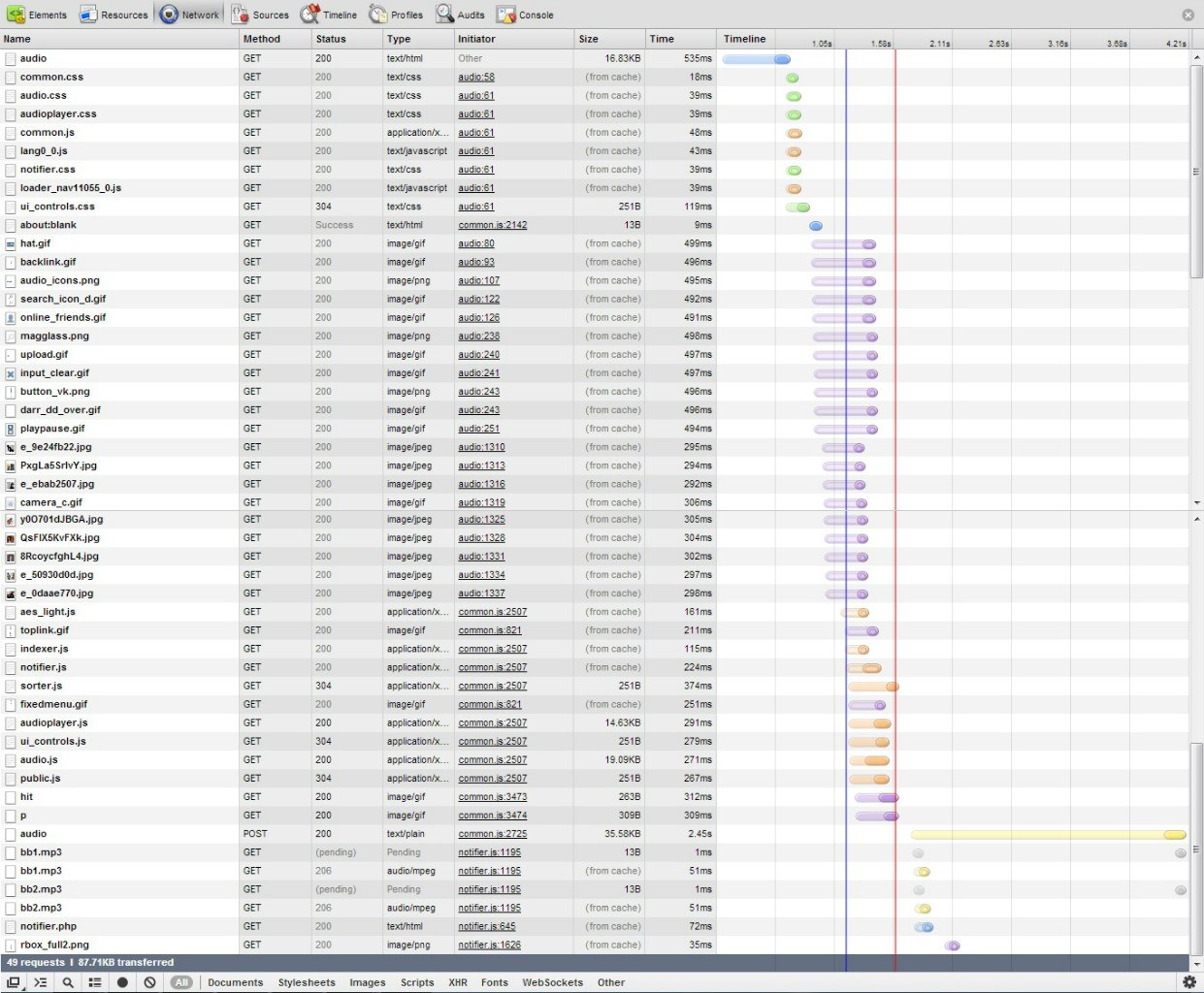
ブラウザーアクションの意味は次のとおりです。
最初の行は、ページに最初にアクセスしたときにサーバーに送信するGETリクエストです。 応答として、サーバーはhtmlページコードを提供します。
その後、ブラウザはすべての必要なリソースの読み込みを開始します:css、js、images。
リストの最後に向かって、非標準の行が表示されます。これは、audioというPOST要求です。 ほとんどの場合、このリクエストはjavascriptを送信して音声記録のリストを取得します。
応答では、サーバーは次のような行を返します。
11055<!>audio.css,audio.js<!>0<!>6362<!>0<!>{"all":[ ['17738938','173762121', 'http://cs1276.userapi.com/u1040081/audio/c0e97293c5e2.mp3','300','5:00', 'Louis Prima','Sing, Sing, Sing (With A Swing)','369754','0','0','','0','1'], ['17738938','173368012', 'http://cs4372.userapi.com/u9237008/audio/5f51ceac6ca1.mp3','326','5:26', 'Look at my horse','My horse is amazing','10324035','0','0','','0','1'], ...
ビンゴ! これがまさに私たちが必要とするものです。 応答として、サーバーはすべてのコンポジションのJSONリストを返し、それぞれに次のパラメーターを渡します。
- 0-私のID
- 1-コンポジションID
- 2-歌へのリンク
- 3-ビットレート?
- 4-期間
- 5-著者
- 6-曲のタイトル
- 7-バイト単位のサイズ?
- 他のパラメーターは明確ではありません。
オーディオ録音のリストを取得する
ようこそリストを取得するにはどうすればよいですか? ブラウザがリクエストで送信するヘッダーを確認しましょう。
Request Headers: Accept:*/* Accept-Charset:windows-1251,utf-8;q=0.7,*;q=0.3 Accept-Encoding:gzip,deflate,sdch Accept-Language:ru-RU,ru;q=0.8,en-US;q=0.6,en;q=0.4 Connection:keep-alive Content-Length:45 Content-Type:application/x-www-form-urlencoded Cookie:remixlang=0; remixseenads=2; audio_vol=100; remixdt=0;remixsid=************; remixflash=11.4.31 Host:vk.com Origin:http://vk.com Referer:http://vk.com/audio User-Agent:Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.4 (KHTML, like Gecko) Chrome/22.0.1229.94 Safari/537.4 X-Requested-With:XMLHttpRequest Form: Dataview URL encoded act:load_audios_silent al:1 gid:0 id:17738938
リクエストをシミュレートしてみましょう:
import requests as r def getAudio(): response = r.post(url = "http://vk.com/audio", data = { "act":"load_audios_silent", "al":"1", "gid":"0", "id":"17738938" } ) print response.content getAudio()
request.post関数は、URLへのPOSTリクエストを作成します。 彼女はいくつかのパラメータを渡すことができます。 主なものは次のとおりです。
- headers-サーバーに送信するヘッダーの辞書
- data-リクエストで送信されるデータの辞書
関数は私たちを印刷します
<!--11055<!>audio.css,audio.js<!>0<!>6362<!>3<!>230b860567731c4875
結果は予測可能です-結局のところ、私たちは承認されたユーザーであることを示しませんでした。 これを行うには、Cookieをサーバーに渡します。 リクエストを少し修正しましょう。
import requests as r def getAudio(): response = r.post( "http://vk.com/audio", data = { 'act':"load_audios_silent", "al":"1", "gid":"0", "id":"17738938" }, headers = { "Cookie":"remixlang=0; remixseenads=2; remixdt=0; remixsid=**************; audio_vol=96; remixflash=11.4.31" } ) print response.content[0:1000] getAudio()
これで必要なものが得られました。
いいね 受け取ったリスト。 次に、それを解析し、各曲を個別にダウンロードする必要があります。 気にしないことに決め、正規表現を使用しました。
#-*-coding:cp1251-*- import requests as r import re import random as ran import os import urllib as ur # : ALLOW_SYMBOLS = " qwertyuiopasdfghjklzxcvbnm.,-()" COOKIE = "" # cookies, . def getAllowName(string): """ , ALLOW_SYMBOLS""" s='' for x in string.lower(): if x in ALLOW_SYMBOLS: s += x return s def getRandomElement(arr, delete = False): """ arr. delete = True, .""" index = ran.randrange(0, len(arr), 1) value = arr[index] if delete: arr.remove(value) return value def getAudio(): """ . """ response = r.post( "http://vk.com/audio", data = { 'act':"load_audios_silent", "al":"1", "gid":"0", "id":"17738938" }, headers = { "Cookie":COOKIE } ) i=0 pat = re.compile(r"\[.+?\]") # [.*] return pat.findall(response.content) # already_added = [] # id , . pat = re.compile(r"\'(.+?)\'") # '.*' def OneDownload(x): """ , ( ['...', '...', '...', ...]) """ global already_added try: elements = pat.findall(x) # id, url, author, name = (elements[1], elements[2], elements[5], elements[6]) # - id, url, author, name except: return if id not in already_added: # already_added.append(id) # file_path = "audio/"+getAllowName(author+" - "+name)+".mp3" # , with open(file_path, "w"): # pass ur.urlretrieve(url, file_path) # print name, "downloaded" def getFirstNSongs(first=0, last = None): """, , """ if not os.path.exists(os.path.join(os.getcwd(), 'audio')): # audio os.mkdir('audio') songs = getAudio() # # , first last: if last!=None: songs = songs[first:last+1] else: songs = songs[first:] for x in songs: # OneDownload(x) # getFirstNSongs(last = 10)
ここでの主な機能はOneDownload()です。 実際、曲をダウンロードするのは彼女です。 これは、標準関数urllib.urlretrieve(url、file_path、...)を使用して行われます。 この関数は、URLにアクセスするときにサーバーが返すデータをダウンロードし、file_pathにあるファイルに書き込みます。
すべてが正常で、すべてがダウンロードされていますが、ゆっくりです!
アルゴリズムの並列化を試みることができます。 並行して実行したい機能はOneDownloadです。 並列化デコレーターを作成します。
def Thread(f): def _inside(*a, **k): thr = threading.Thread(target = f, args = a, kwargs = k) thr.start() return _inside
Pythonのデコレータは、関数を引数として受け取り、何らかのアクションを起こす関数です。
このデコレータは、受け入れられた関数を別のスレッドで実行するだけです。
グローバル変数-スレッド数を追加します。 この変数はスレッドから直接変更できないため、関数を追加します
インクリメント、およびレシート:
alive_threads = 0 def inc(x): # global alive_threads alive_threads+=x return alive_threads def get(): # global alive_threads return alive_threads
次に、コードを変更します。 プログラムの最終バージョンは次のとおりです。
#-*-coding:cp1251-*- import requests as r import re import threading import time import random as ran import os import urllib as ur THREADS_COUNT = 10 ALLOW_SYMBOLS = " qwertyuiopasdfghjklzxcvbnm.,-()" COOKIE = "" # cookies def getAllowName(string): s='' print string.lower() for x in string.lower(): if x in ALLOW_SYMBOLS: s += x return s def getRandomElement(arr, delete = False): index = ran.randrange(0, len(arr), 1) value = arr[index] if delete: arr.remove(value) return value alive_threads = 0 def inc(x): global alive_threads alive_threads+=x return alive_threads def get(): global alive_threads return alive_threads def Thread(f): def _inside(*a, **k): thr = threading.Thread(target = f, args = a, kwargs = k) thr.start() return _inside def getAudio(): response = r.post( "http://vk.com/audio", data = { 'act':"load_audios_silent", "al":"1", "gid":"0", "id":"17738938" }, headers = { "Cookie":COOKIE } ) i=0 pat = re.compile(r"\[.+?\]") return pat.findall(response.content) already_added = [] # id , . pat = re.compile(r"\'(.+?)\'") # '.*' count = 0 @Thread def OneDownload(x): global already_added inc(1) # - try: elements = pat.findall(x) id, url, author, name = (elements[1], elements[2], elements[5], elements[6]) except: return if id not in already_added: already_added.append(id) file_path = "audio/"+getAllowName(author+" - "+name)+".mp3" with open(file_path, "w"): pass ur.urlretrieve(url, file_path) inc(-1) # - def getFirstNSongs(a=0, N = None): if not os.path.exists(os.path.join(os.getcwd(), 'audio')): os.mkdir('audio') songs = getAudio() if N!=None: songs = songs[a:N] else: songs = songs[a:] previous = 0 # cc=10 while (len(songs)>0 and len(songs)!=previous) or (len(songs) == previous and cc>0): # , 10 if previous != len(songs): previous = len(songs) #, . - cc=10 # - 10 else: cc-=1 # , 1. - 10 print " ", len(songs), " ", alive_threads while alive_threads<THREADS_COUNT: # x = getRandomElement(songs, delete = True) # , try: OneDownload(x) # except: songs.append(x) # - . while alive_threads>=THREADS_COUNT: time.sleep(10) # - 10 . getFirstNSongs(N=3) #, , 3
これですべてが機能します。
ソースとコンパイルされたバージョンはここからダウンロードできます:
VKmusic
#UPD
コンパイルされたバージョンにはバグがあり、音楽は私のページからのみダウンロードされました。 修正されたバージョン:
VKMusic