
ゆっくりとさらに進んでいきます...? パフォーマンス評価。
7年以上にわたり、インテルのノボシビルスク支社のパフォーマンス分析グループの一部としてパフォーマンス分析に携わってきました。 さまざまなアプリケーションのパフォーマンスを改善するために取り組んでいます。むしろ、コンパイラーがそれを改善できる方法を探しています。 この間、有用な経験が蓄積されました。これは、私の意見では、尊敬されているHabrの訪問者にとって興味深いものです。 この場合、アプリケーションのアルゴリズムの最適化についてではなく、アルゴリズムを根本的に変更しないアプリケーションのさまざまな変更について説明します。 アルゴリズム最適化プログラムにも生存権があることは明らかですが、これはまったく別のタスクです。
私はインテルのコンパイラー開発者なので、すべての研究はさまざまなコンパイラーの最適化に関連しており、異なるコンパイラーを比較しています(Windowsでは通常、インテル®コンパイラーとMicrosoft Visual Studioコンパイラーを比較しています)。 したがって、実際には、私の投稿を広告または反広告と見なさないでください。 私の考えを説明するために、当社が開発したものを含むさまざまなツールを使用します。 この投稿が、アプリケーションの最適化に関する一連の記事に成長することを願っています。
アプリケーションの最適性を評価するための簡単な基準はありますか?
アプリケーションのパフォーマンスを改善するタスクを含む問題やタスクは、現状の調査から始まることは明らかです。 評価が必要です。アプリケーションがどの程度既に最適化されているか、そしてそれをスピードアップするための努力をすることは理にかなっています。 一見すると、この問題には簡単な解決策があります。 このような見積もりを得るには、プロセッサの負荷を測定するだけで十分です。 さまざまなパフォーマンスアナライザーを使用すると、プログラムのさまざまなセクションの実行時間を測定できるだけでなく、実行中に発生するすべてのプロセッサ内イベントを計算してプログラムコードにリンクすることもできます。 この情報を使用して、コンピューティングコアの負荷を評価できます。 たとえば、1つの命令を実行するのに平均してどれくらいのプロセッササイクルがかかったか、および実行の遅延を引き起こした理由を判断するには。 提案された基準は、カーネルの効率をアプリケーションのパフォーマンスを改善する能力に関連付けます。 つまり、カーネルが効率的に動作する場合、心配する理由はありません。プログラムは最適に動作します。そうでなければ、アプリケーションを改善でき、分析するのが理にかなっています。 この基準を使用した結果、いくつかのプロセッサイベントが分析される作業が発生し、この分析に基づいて作成者は、アプリケーションのパフォーマンスを向上させる可能性について推測します。 おそらく、このような作業方法はコンピューターアーキテクトにとって非常に有用であり、プロセッサーアーキテクチャの改善について夢を見る機会を与えます。 しかし、残念ながら、アプリケーションのパフォーマンスの改善を考えているプログラマーにとって、この方法は非常に疑わしく、めったに機能せず、ロシアの知識人の永遠の質問に答えることはありません。 そして、手で鶏肉を食べることは可能ですか?」
多くの場合、コンピューティングコアの最大負荷は、プログラムのパフォーマンスを向上させることが不可能であることを意味するものではありません。
長方形行列の乗算を使用した簡単なテストを見てみましょう。 私の意見では、小さな作業例を作成することは、コンパイラーやプロセッサーの作業など、宇宙の構造に関する興味深い情報を取得する最良の方法です。 このようなテストでは、調査中のコードの実行時間を十分に長くして、プログラムの読み込み時間やランダムイベントの影響を受けないようにすることが重要です。そのため、調査中のコードを何度も実行できます。
#include <stdio.h> #include <stdlib.h> #define N 200 #define T 100 void matrix_mul_matrix(int t, int n, double *C, float *A, float *B) { int i,j,k; for (i=0; i<t; i++) for (j=0; j<t; j++) for(k=0;k<n;k++) C[i*t+j]+=(double)A[i*n+k] * (double)B[k*t+j]; } int main() { float *A,*B; double *C; int i,j; //... for(i=0;i<10000;i++) matrix_mul_matrix(T,N,C,A,B); printf("%f %f %f\n",C[0],C[1],C[100]); free(A); free(B); free(C); }
Windows Server 2008 R2 EnterpriseとIntel Xeon X5570プロセッサを搭載したラボマシンで、Microsoft VS 10.0コンパイラを使用してこのプログラムをコンパイルします。 およびIntel Parallel Studio XE2013。 簡単にするために、コマンドラインで作業し、Visual Studioで既定で使用されるコンパイルのリリースバージョンに対応するオプションを使用します。
cl matrix.c / O2 / GL / GS / GR / W3 / nologo / Wp64 / Zi -Ob0 -Fematrix_cl
icl matrix.c / O2 / GL / GS / GR / W3 / nologo / Wp64 / Zi -Ob0 -Fematrix
matrix_clの実行時間は〜21.9秒であり、matrixの実行時間は〜9.3秒です。
ここで、AmplifierがCPU使用率について教えてくれるものを見てみましょう。 Intel VTune Amplifier XE 2011は、Intelプロセッサのプロセッサイベントを操作できるパフォーマンス評価ツールです。
Amplifierで受信したアプリケーション用の2つのプロジェクトを作成し、予備分析を行います。一般的な調査です。 それで、結果として何が見えるでしょうか? matrix_clアプリケーションの「インテリジェンス」の結果は次のとおりです。

CPIレート(命令ごとのクロック、命令ごとの平均ティック数)に注意してください。 私のプロセッサーの場合、この値の理論上の最小値は0.25です。 (4つのアクチュエータでの4つの命令の並列実行)。 CPI番号0.546は非常に良いと考えられています。 もちろん遅延があります。 しかし、重要なことは何もないようです。 コンピューティングコアは良好な負荷で動作しており、すべてがかなり適切に見えます。 この評価から、アプリケーションのパフォーマンスが実際に2倍以上であることを理解できますか?
マトリックスの研究結果:
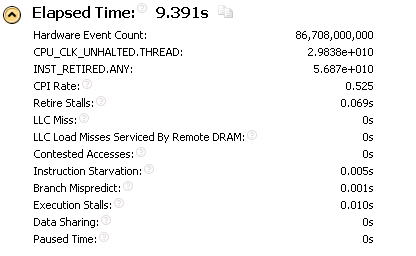
魔法のようなパフォーマンスの2倍以上の改善は、Intel VTune Amplifier XE 2011によってコンパイルされた計算の主要な「評価」にはほとんど影響を与えませんでした。 この場合のプロセッサの研究では、パフォーマンスが劇的に改善される可能性があるという信号は得られませんでした。
このパフォーマンスの向上は、自動ベクトル化によって達成されました。 これは、インテル®コンパイラーのオプションに–Qvec_reportを追加すると簡単にわかります。 コンパイラは
...
... \ matrix.c(9):(列5)リマーク:置換ループはベクトル化されました。
つまり 巡回置換最適化の使用により、アプリケーションのパフォーマンスが改善されました。 そのような最適化を適用できることを理解するには、行列乗算アルゴリズムを研究する必要がありました。
次に、別の種類の例を取り上げて、オブジェクトの長いチェーンをバイパスするプログラムを作成します。
#include <stdio.h> #include <stdlib.h> #define N 1000000 struct _planet { float x; float y; float z; double m; struct _planet *prev; struct _planet *next; } ; typedef struct _planet planet; planet* init_chain() { } int main() { planet *planet_chain; planet *cur; int i; double sum=0.0; planet_chain=init_chain(); for(i=0;i<1000;i++) { cur=planet_chain; while(cur) { sum += cur->m; cur=cur->next; } } printf("%f\n",sum); }
両方の最適化コンパイラーは、〜6.2sを実行するアプリケーションを作成しました。 アンプは、このアプリケーションのすべてが悪いことを報告します。

CPIレートは非常に低く、ほとんどの場合、コンピューティングコアは処理のためにデータを受信することを期待しています。
それではどうすればいいですか? 調査を続け、コンピューティングコアの負荷が低い原因はメモリサブシステムの動作の遅延であると判断したとします。 明らかに、カーネルの負荷は不十分です。 しかし、この神聖な知識は私たちに何を助けますか? メモリサブシステムのパフォーマンスを向上させる方法は何ですか? アプリケーションの特異性により、既知の方法を使用できますか?
これは、すべてが悪いアプリケーションの例であり、アルゴリズムを変更しないと状況を根本的に修正することはできません。
結論
したがって、さまざまなプロセッサ係数の単純な計算では、アプリケーションの有効性を評価するための情報はほとんど提供されません。
この場合、実行中のアプリケーションの有効性を評価するタスクの単純な類似点は、ポイントAからポイントBに移動するアスリートです。アスリートの最適な作業の基準として彼の筋肉に負荷をかけるか、トラックの平均速度とこのアスリートができる最大速度を比較する場合移動してから、そのような基準をどこまで進めますか? アスリートが非常に強くても悪いので、パスに沿って走り回るのではなく、常に茂みを突破する場合は、よりインテリジェントなアスリートが必要です。 逆に、アスリートがゆっくり走ったが、彼の道が沼地を通り抜けた場合、そこで彼は停止し、道を感じ、さらには定期的に戻ってくる必要がありますか? 問題を解決するために、より多くの訓練を受けたより速いアスリートを(大金で)参加させるか、レーストラック、スタート時のランナーの長所と短所を分析し、ランナーに最適なルートを提供し、外出先でそれを教えることができる有能なトレーナーを使用することができますいくつかの単純な状況での正しい決定。
一言で言えば、克服しなければならない道とアスリートの長所と短所の知識を分析せずに、彼がどれだけ距離を置いているかを評価することは困難です。
したがって、私の意見では、アプリケーションの有効性を評価するための簡単で普遍的な作業方法はなく、したがって、それを改善する簡単な方法はありません。 この問題を解決するには、脳を接続して多くの状況を分析し、よく知られた方法を適用して生産性を向上させる必要があります。 他のビジネスと同様に、脳の接続方法論が必要です。 問題をうまく解決するために、彼はいくつかのことを知らなければなりません、例えば:
1.)プロセッサのパフォーマンスに影響する主な問題、およびこれらの問題に影響する最適化方法。
2.)コンパイラ最適化の主な方法。 原則として、プログラムのパフォーマンスを向上させるのに役立つこれらのメソッドはすべて、すでに何らかの形で考慮され、既存の最適化コンパイラに実装されています。 作業で使用するツールを知っていると便利です。 おそらくもう1つのオプションを追加するだけで成功につながります。 コンパイラがこれまたはその最適化を行うことができるかどうか、そしてなぜあなたのコードに対してそれができなかったのかを知ることは興味深いですか?
3.)よく知られている最適化の多くは、手作業で効果的に行うことができます。 どのような場合に作成できますか? この最適化またはその最適化の使用が有益なのはいつですか?
したがって、将来、そのような方法論の例を提供し、私が知っているアプリケーションを最適化するための有用な方法についてお話します。