 Puppetは非常に便利な構成管理ツールです。 実際、これは、多数のマシンとサービスの構成と管理を自動化できるシステムです。
Puppetは非常に便利な構成管理ツールです。 実際、これは、多数のマシンとサービスの構成と管理を自動化できるシステムです。
Habréを含む、システム自体に関する多くの基本情報があります: here 、 here 、 here 。 1つの記事で、Badooの「戦闘状態」で、Puppetを非常に重い負荷の下で使用するためのいくつかの「レシピ」を収集しようとしました。
議論されるもの:
- Puppet:教育プログラム。
- クラスタリング、スケーリング。
- 非同期Storeconfigs;
- レポートのコレクション。
- データの分析。
HighLoad ++ 2012カンファレンスでのAnton Turetskyの報告を受けて、記事が書かれたことをすぐに予約してください。 数日で、私たちの「レシピ」は、追加の詳細と例で大きくなりすぎました。
負荷に戻ると、Badooでは非常に高いことに注意する必要があります。
- 2000以上のサーバー。
- マニフェスト(英語のマニフェスト 、この場合、管理サーバーの構成ファイル)で30,000行以上。
- 3分ごとにパペットマスター構成を要求する200以上のサーバー。
- 同じ期間にレポートを送信する200を超えるサーバー。
仕組み

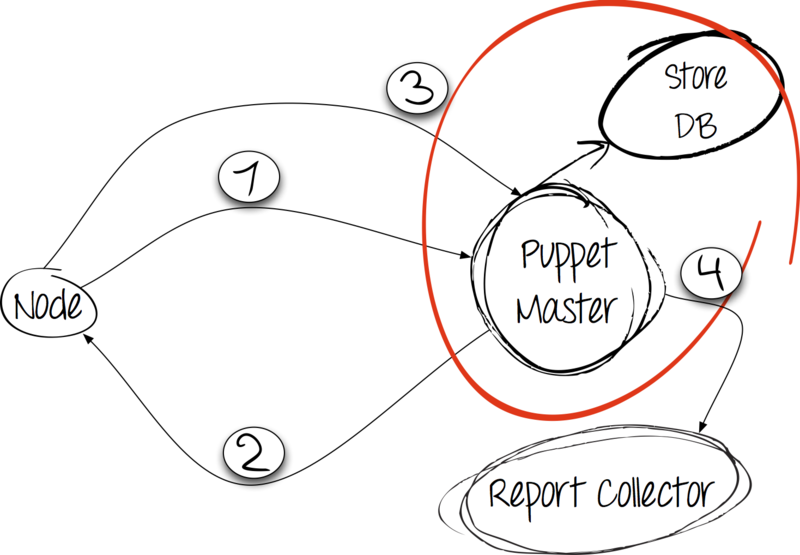
Puppet自体はクライアントサーバーアプリケーションです。 Puppetの場合、クライアントは接続を開始します。 この場合、これは構成をデプロイするノード(eng。node)です。
ステップ1:設定と引き換えに事実

クライアントは、Puppetアプリケーションの固有の依存関係であるファクトユーティリティを使用して自分に関する事実を収集し、通常のHTTP POSTリクエストでそれらをサーバーに送信し、彼の応答を待ちます。
ステップ2:処理と応答
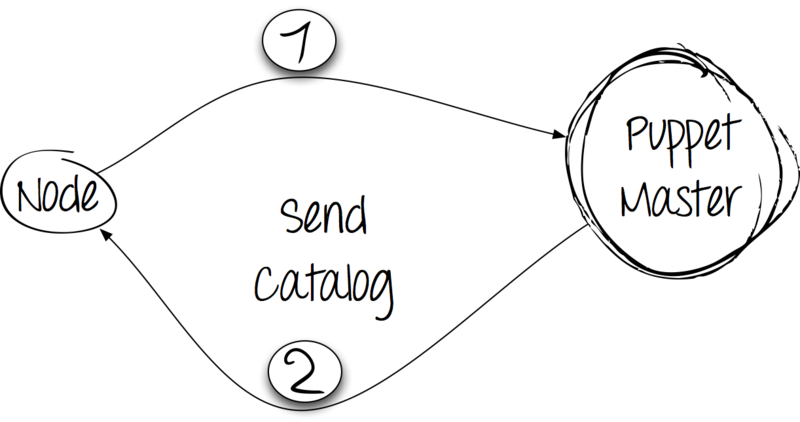
サーバーはクライアントからファクトダンプを受け取り、カタログをコンパイルします。 同時に、サーバーで利用可能なマニフェスト内の情報から進みますが、クライアントから受信した事実も考慮します。 カタログがクライアントに送信されます。
ステップ3:カタログを適用して結果を報告する

サーバーからディレクトリを受信すると、クライアントはシステムに変更を加えます。 実行の結果は、HTTP POST要求を使用してサーバーに報告されます。
ステップ4:レポートの収集と保存
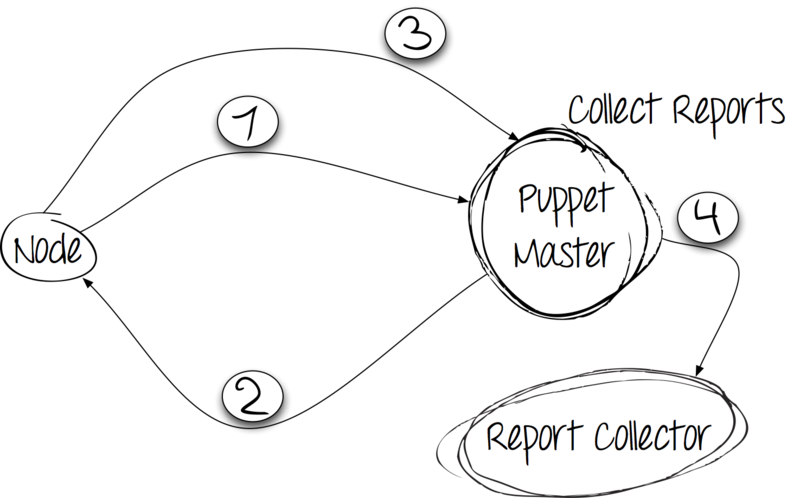
クライアントがすべてのルールを満たした後、レポートを保存する必要があります。 Puppetは、独自の開発とサードパーティのコレクターの両方を使用することをお勧めします。 やってみます!
基本パッケージをインストールして、次の図を取得します。
一見、すべてが正常です-設定して動作します。 しかし、時間が経つにつれて、写真はあまり楽しくなくなります。 クライアントの数は増加し、システム管理者はマニフェストを作成します。その結果、コードのコンパイルと各クライアントの処理に費やされる時間が長くなります。
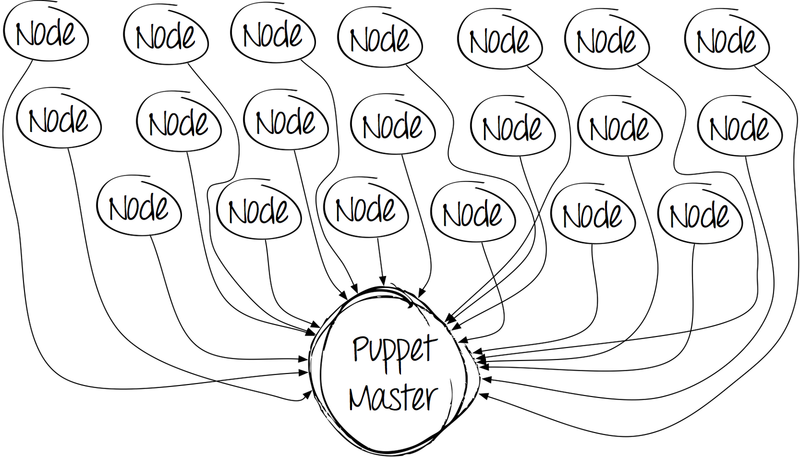
そして、ある瞬間、絵はとても悲しくなります。
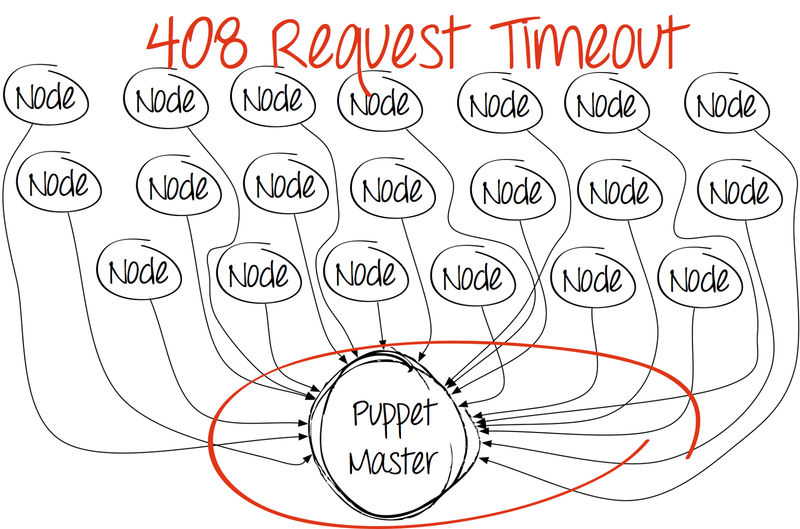
最初に頭に浮かぶのは、サーバー上のパペットマスタープロセスの数を増やすことです。 はい、Puppetは基本パッケージでこれを行う方法を知らず、カーネルを「スミアリング」しないためです。
メーカーが提案したソリューションはありますか? もちろん、しかし、さまざまな理由で、彼らは私たちの条件に適用されませんでした。
なぜApache + mod_passengerではありませんか? 特定の理由により、当社ではApache Webサーバーをまったく使用していません。
なぜnginx +乗客ではないのですか? 使用するnginxアセンブリに追加のモジュールが必要になるのを避けるため。
それで何?
ユニコーンに会う
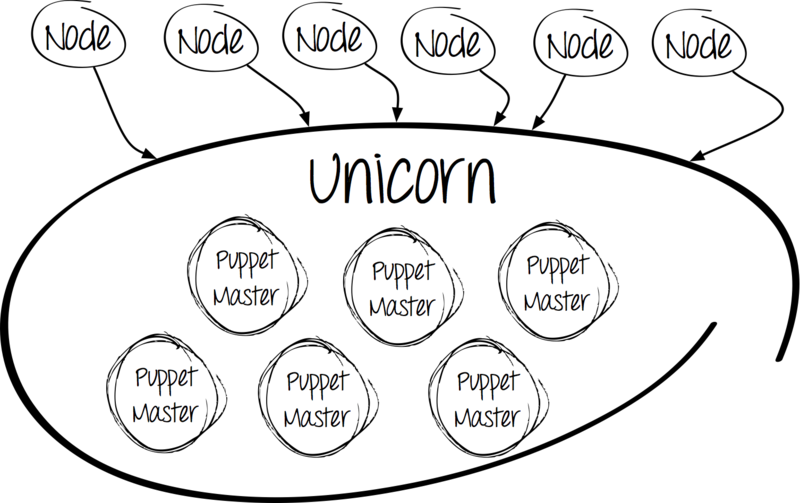
ユニコーンを選ぶ理由
ここで、私たちの意見では、その利点:
- Linuxカーネルレベルのバランシング
- 環境内のすべてのプロセスを開始します。
- nginxスタイルの接続を失わずに更新します。
- 複数のインターフェイスでリッスンする機能。
- PHP-FPMと類似していますが、Ruby用です。
Unicornを選択したもう1つの理由は、インストールと設定が簡単だったことです。
worker_processes 12 working_directory "/etc/puppet" listen '0.0.0.0:3000', :backlog => 512 preload_app true timeout 120 pid "/var/run/puppet/puppetmaster_unicorn.pid" if GC.respond_to?(:copy_on_write_friendly=) GC.copy_on_write_friendly = true end before_fork do |server, worker| old_pid = "#{server.config[:pid]}.oldbin" if File.exists?(old_pid) && server.pid != old_pid begin Process.kill("QUIT", File.read(old_pid).to_i) rescue Errno::ENOENT, Errno::ESRCH end end end
良いニュースです。複数のプロセスを実行することができます。 しかし、悪い点があります。プロセスの管理がはるかに難しくなっています。 怖くない-この状況には「レシピ」があります。
「神に信じる」
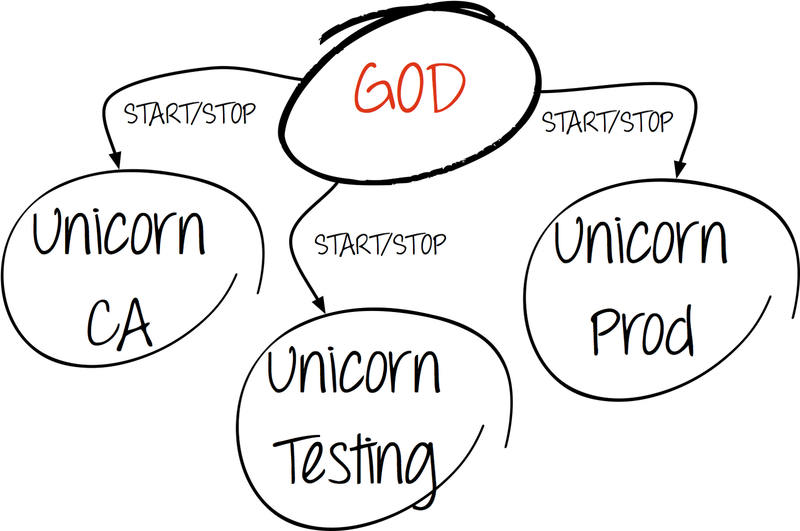
神はプロセス監視フレームワークです。 セットアップは簡単で、Puppet自体と同じようにRubyで書かれています。
この場合、神はさまざまなパペットマスタープロセスインスタンスを管理します。
- 実稼働環境;
- テスト環境。
- PuppetCA。
カスタマイズに関しても特別な問題はありません。 * .godファイルを処理するには、ディレクトリ/ etc / god /に構成ファイルを作成するだけで十分です。
God.watch do |w| w.name = "puppetmaster" w.interval = 30.seconds w.pid_file = "/var/run/puppet/puppetmaster_unicorn.pid" w.start = "cd /etc/puppet && /usr/bin/unicorn -c /etc/puppet/unicorn.conf -D" w.stop = "kill -QUIT `cat #{w.pid_file}`" w.restart = "kill -USR2 `cat #{w.pid_file}`" w.start_grace = 10.seconds w.restart_grace = 10.seconds w.uid = "puppet" w.gid = "puppet" w.behavior(:clean_pid_file) w.start_if do |start| start.condition(:process_running) do |c| c.interval = 5.seconds c.running = false end end end
Puppet CAは別のインスタンスに割り当てられていることに注意してください。 これは、すべての顧客が単一のソースを使用して証明書を検証および取得できるように特に行われます。 少し後、これを実現する方法を説明します。
バランス調整
既に述べたように、クライアントとサーバー間で情報を交換するプロセス全体はHTTPを介して行われます。つまり、nginxに頼って単純なhttpバランシングを設定することを妨げるものは何もありません。
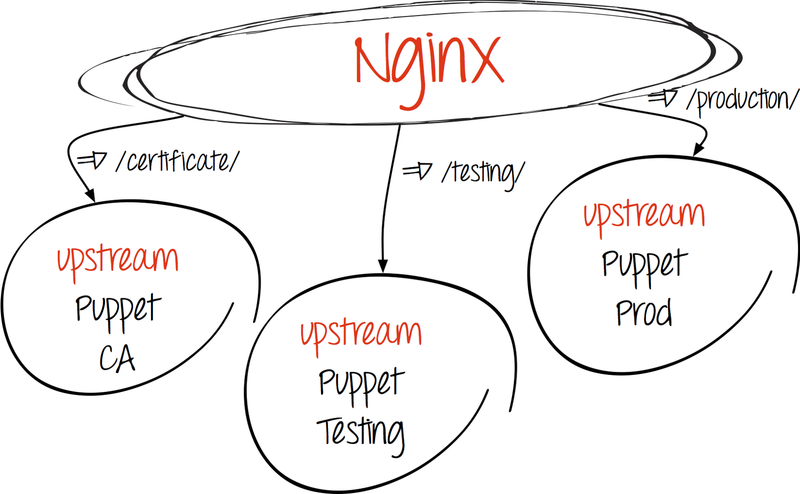
- アップストリームを作成します。
upstream puppetmaster_unicorn { server 127.0.0.1:3000 fail_timeout=0; server server2:3000 fail_timeout=0; } # puppet master ( , production-) upstream puppetca { server 127.0.0.1:3000 fail_timeout=0; } # Puppet CA
- リクエストを受信者にリダイレクトします。
- 操り人形
location ^~ /production/certificate/ca { proxy_pass http://puppetca; } location ^~ /production/certificate { proxy_pass http://puppetca; } location ^~ /production/certificate_revocation_list/ca { proxy_pass http://puppetca; }
- パペットマスター
location / { proxy_pass http://puppetmaster_unicorn; proxy_redirect off; }
- 操り人形
中間結果を要約する。 したがって、上記のアクションにより、次のことが可能になります。
- 複数のプロセスを実行します。
- プロセスの起動を管理します。
- 負荷を分散します。
スケーリングはどうですか?
パペットマスターサーバーの技術的能力は無制限ではなく、その負荷が極端に許容可能になると、スケーリングの問題が生じます。
この問題は次のように解決されます。
- puppetサーバーのRPMパッケージはリポジトリに保存されています。
- すべてのマニフェスト、および神とユニコーンの構成は、Gitリポジトリにあります。
別のサーバーを起動するには、次のもののみが必要です。
- 基本システムを配置します。
- puppet-server、Unicorn、Godをインストールします。
- Gitリポジトリを複製します。
- アップストリームにマシンを追加します。
私たちの「チューニング」はそこで終わりではありませんので、再び理論に戻ります。
Storeconfigs:何と理由?
クライアントが自分自身に関するレポートと事実を私たちに送信する場合、この情報を保存してみませんか?
これは、Storeconfigs-puppet-serverオプションに役立ちます。これにより、関連する顧客情報をデータベースに保存できます。 システムは、クライアントからの最新のデータを既存のデータと比較します。 Storeconfigsは、SQLite、MySQL、PostgreSQLのリポジトリをサポートしています。 MySQLを使用します。
この例では、多くのクライアントが3分ごとに構成を取得し、ほぼ同量のレポートが送信されます。 その結果、MySQLに書き込むための大きなキューをすでに取得しています。 ただし、データベースからデータを取得する必要があります。
この問題には次の解決策があります。
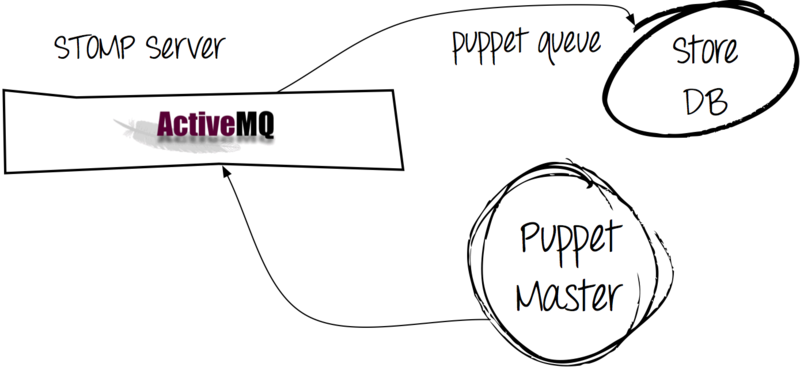
Apache ActiveMQを使用すると、クライアントから直接データベースにメッセージを送信するのではなく、メッセージキューを介してメッセージを渡すことができました。
その結果、次のことができます。
- レポートをサーバーに送信しようとするとすぐに「OK」になるため、クライアントでのpuppet-processの実行が高速になります(データベースに書き込むよりもキューにメッセージを書き込む方が簡単です)。
- MySQLの負荷を軽減します(パペットキュープロセスはデータをデータベースに非同期的に書き込みます)。
puppet-serverを構成するには、構成に次の行を追加する必要がありました。
[main] async_storeconfigs = true queue_type = stomp queue_source = stomp://ACTIVEMQ_address:61613 dbadapter = mysql dbuser = secretuser dbpassword = secretpassword dbserver = mysql-server
また、パペットキュープロセスを開始することを忘れないでください。
説明されている設定のおかげで、Puppetはサーバー上でスマートかつ適切に動作しますが、そのアクティビティを定期的に監視することをお勧めします。 Puppet Reportsについて考える時が来ました。
非標準のレポート
デフォルトで提供されるもの:
- http;
- tagmai;
- ログ;
- rrdgraph;
- 店。
残念なことに、高品質の視覚的コンポーネントの欠如という単一の理由により、どのオプションも私たちに完全かつ完全に適合しませんでした。 残念ながら、あるいは幸いなことに、その時点での標準のPuppetダッシュボードは、私たちにとってあまりにも退屈に思えました。
そのため、私たちはForemanを選択しました。これは、最も必要な素敵な図表を喜んでくれました。


左の写真では、各タイプのリソースを使用するのにどれくらい時間がかかるかがわかります。 360度の場合、クライアントでの完全な実行時間が取られます。
右側の図には、ステータス付きのイベント数が表示されます。 この例では、1つのサービスのみが起動されました。現在の状態が参照の状態に完全に対応しているため、10個を超えるイベントがスキップされました。
最後の推奨事項:バージョン3.0.0へのアップグレード

グラフは、更新後の時間の増加を明確に示しています。 確かに、開発者が約束したように、生産性は50%増加しませんでしたが、その増加は非常に顕著でした。 マニフェスト( メッセージを参照)を編集した後も、約束された50%を達成したため、努力は完全に報われました。
結論として、適切な構成により、Puppetは深刻な負荷に対処でき、2000台のサーバーの構成管理はかなり手の届くところにあると言えます。
アントン[ banuchka ]トルコ語、システム管理者
バドゥー