私はすぐに9 x 9のフィールドで実際の将giのAIを書くことを敢えてせず、5 x 5のフィールド(このフィールドは初心者がよく使用します)でゲームの簡略版から始めることにしました。 ウィキペディアでゲームの完全なルールを読むと、次のセクションを理解しやすくなります。
ゲームのルール
これからは「将gi」を書くことに同意しましょうが、5 x 5フィールドでのゲームの簡略版を意味します。
フィギュア
新しいゲームを学ぶときに理解する最初のことは、動きです。 将giには10種類の形があります。 数字の指定、それらの名前、および考えられる動きを以下の表に示します。
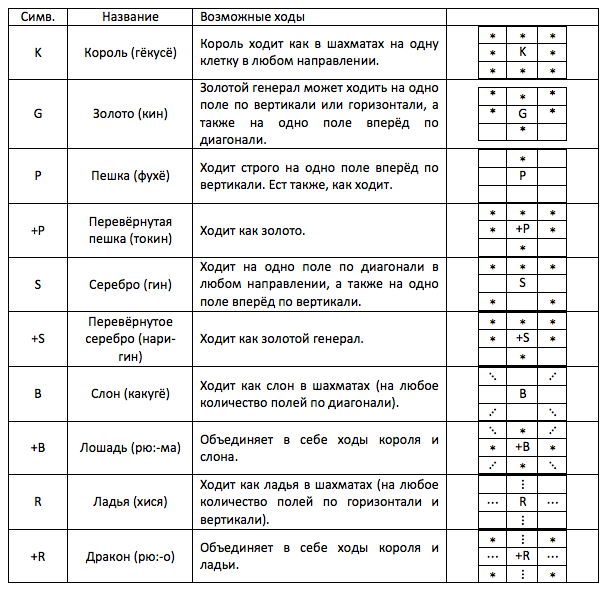
クープス
確かに、数字の中には「逆ダブル」があり、ほとんどの場合元のものより強いことに気づきました。 将giでの増幅の原理はチェスに似ていますが、チェスでポーンのみが回転して任意のピースに変わると、金と王を除くすべてのピースが将giに変わります。 クーデターを達成するには、敵の最後の水平線で移動を開始または終了する必要があります。 一般的な場合、クーデターは任意です。 ルークで最後の水平線に到達できますが、裏返さないでください。クーデターでキャンプに戻ります(最後の対角線で移動を開始したため)。 クーデターゾーンに到達すると、当然ポーンはロールオーバーする必要があります。
放電
ここまで読んだら、将giはチェスやチェッカーのようなものだと思うかもしれませんが、そうではないことを保証します。 将giには1つのニュアンスがあり、すぐにこのゲームを数桁難しくします。
自分の自由フィールドに、相手が食べたものを置くことができます。 このような行動は退院と呼ばれます(個人的には、この文脈でAndrei Vasnetsovが最初に使用した「スペースランディング」という言葉を好みます)。
確かに、リセット時にはいくつかの制限がありますが、それらは非常に簡単です。
- すべての数値は元に戻されずにリセットされます。
- クーデターゾーンにピースをドロップすると、移動した後にのみロールオーバーできます。
- ポーンが既に存在する場所にポーンを折り畳むことはできません(トークンはポーンとは見なされません)。
- ポーンを最後の水平にドロップすることはできません。
- チェックメイトでポーンをフォールドすることはできません。
リセットルールは重要ではないように見えるかもしれませんが、ゲームの戦略全体を根本的に変更します。 チェスやチェッカーの場合は、わずかな物質的優位性を獲得し、その後交換を続けてエンドゲームで勝つだけで十分であれば、チェスでは交換がより緊張したポジションにつながり、誤算を複雑にします。
一連の動きと初期配置
ゲームは、5つのセルからなる正方形のフィールドで行われます。 ゲームの開始時、フィールドは次のようになります。

私には知られていない理由で、将giでは黒が最初に始まり、白は守られています。 条件と混同しないように、パーティを開始するパーティはセンテと呼ばれ、防御側はゴテであることに同意しましょう。
プログラミング自体に進む前に、もう1つ重要な注意事項があります。 将giにはシャーの概念はありません。 あなたの王は脅されているので、自分を守る必要も逃げる必要もありません。 非常にうまく攻撃を開始できます。 確かに、次の動きはあなたの王を食べる可能性が高く、ゲームは終了します。
ゲームプログラミング
エントリは非常に長いことが判明しましたが、信じてください、あなたはそれなしではできませんでした。 むかしむかし、私はすでにハブにゲームツリーに関する投稿を書きました。 ゲームツリーの主な利点は、三目並べ、下書き、チェス、将shoなど、あらゆるゲームに適用できることです。 主なアイデアを思い出してみましょう。
検索ツリー
ゲームツリーの完全な検索
将giをやってみましょう。ボード上のある時点で、センテに最適な動きを見つける必要がある興味深い位置が生じました。 なぜなら コンピューターは本質的に愚かな実行者なので、可能なすべての動きを並べ替えて評価するように命じることができます。 次に、最高の格付けを持つ動きが最高の動きになります。 しかし、まだ動きを評価する方法がわかりません。
ここで少し余談しますが、特定の位置にいる通常のユニットでセンテが有利な場合、この位置のゴスは通常のユニットを失うことに気づくことができます。 sente側とgote側の両方から位置を評価する関数は同じモジュロ結果を与え、違いは符号のみにあることがわかります。
次に、goteの最適な応答の移動の推定値を反転することにより、senteの各移動の推定値を取得できます。 そして、ゴスの最高の動きの推定は、センテなどの最高の戻りの動きを評価することによって得られます。 つまり 進捗評価関数は本質的に再帰的であることがわかりました。 これらの再帰的な位置評価は、理想的には、ツリーの各ブランチにマットがあるゲームが終了するまで継続する必要があります。 次の図は、将giをプレイするときに発生するゲームツリーの小さな部分を示しています。
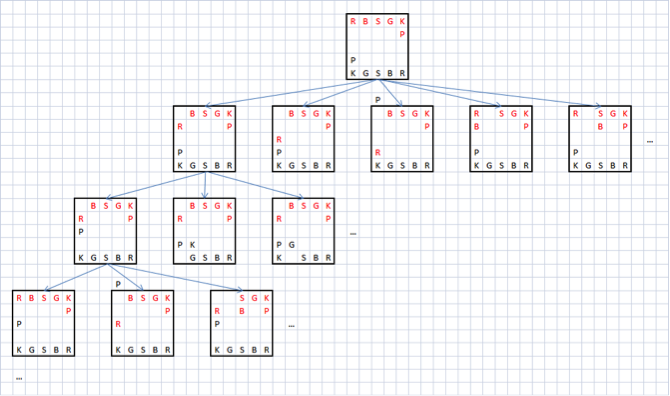
再帰の深さが制限されたゲームツリーの列挙
明らかに、このツリーは非常に速く成長します。 三目並べの場合でも、チェスや将giは言うまでもなく、完全なツリーには25万以上のノードが含まれます。 実際のアルゴリズムでは、再帰の深さは人為的に制限されており、最大の再帰の深さに達すると、静的な位置推定の関数が呼び出されます。たとえば、単に材料の利点を計算します。 したがって、最適な移動検索機能は次のように記述できます。
関数 SearchBestMove (深さ: バイト ;色: TColor ) : 実数 ;
var
r 、 tmpr : 実数 ;
i 、 N : 単語 。
移動: TAMoves ;
始める
深さ= 0の 場合
r : = EstimatePos
他に
始める
実数 : =- 100000 ;
N : = GenerateAllMoves ( Moves ) ;
for i : = 1 から N
始める
移動しますMoves [ i ] ;
tmpr : =- SearchBestMove ( Depth - 1 、 opcolor (色) ) ;
移動をキャンセルするMoves [ i ] ;
tmpr> rの場合
r : = tmpr ;
終わり ;
終わり ;
SearchBestMove : = r ;
終わり ;
このアルゴリズムが完全な位置推定値を提供するのではなく、動きの深さを通して生じる位置の推定値のみを提供することは明らかです。 したがって、プログラムのゲームを強化する必要がある場合、まず、再帰の深さを増やす必要があり、これはツリーの増加につながり、したがってカウント時間の増加につながります。
アルファベータクリッピング
実際、ツリー全体ではなく、その一部のみを整理し、同時に完全な列挙と同じ精度の推定値を提供できるアルゴリズムがあります。 このアルゴリズムは、アルファベータクリッピングと呼ばれます。
アルゴリズムの基本は、ツリーの一部のブランチが完全に検討される前であっても非効率であると見なすことができるという考え方です。 たとえば、一部のノードの評価関数が以前に検討されたブランチよりも悪いことが保証されている場合、このノードの検討は予定より早く停止できます。
このような状況は、次の場合に発生します。Senteの背後にあるポジションを検討します。検討した後、一部のブランチはポジションの評価を受け取ります。 次に、ツリーの深さで、別の可能な動きを検討すると、白のスコアが以前に取得した最大値以上になることに気付きました。 明らかに、このノードをさらに調べることは意味がなく、そこから出現するすべてのブランチは位置の改善をもたらさないでしょう。
このアルゴリズムは、より良い動きが以前に考慮された場合にのみブランチをカットできることにお気づきかもしれません。 すべての動きを最悪から最高まで順番にチェックしたと仮定すると、アルファベータアルゴリズムは網羅的検索と比較してゲインを提供しません。 最初に最適な動きが考慮された場合、Nノードの完全なツリーではなくアルファ-ベータアルゴリズムは、推定の精度が同じで、Nノードのルートのみを考慮します。
並べ替えの動き
主な問題は、どの動きが実際に良いか、どの動きが悪いかを事前に判断することができないことです。 この場合、ヒューリスティックに頼らなければなりません。 ポジションを評価する際に重要な利点のみが考慮される場合、最初に動きを考慮することは理にかなっています。 さらに、そもそも、重い数字が軽いものと見なされるような動きを考慮することは理にかなっています。 さらに、倒立した駒は将inで大きな役割を果たします。したがって、予備のクーデターの動きについては、予備のヒューリスティックスコアを増やすこともできます。
クーデターといえば。 クーデターが可能であれば、必ずしもクーデターを行う必要はないことを理解することが重要です。 たとえば、ゲームの終わりに、横に退却できる銀は、金よりも効果的である場合があります。 しかし、ポーン、ルーク、および司教については、クーデターが常に実行されます。 クーデターは元の動きをすべて残し、新しい動きを追加します。
その結果、すべての動きが生成され、それらのヒューリスティック評価が実行された後、この評価によってそれらをソートし、次のようなアルファベータアルゴリズムの入力に送信する必要があります。
関数 AB ( POS : TRPosition ;色: TColor ;深さ: バイト ; A 、 B : 実 ) : 実 ;
var
移動: TAMoves ;
i 、 MovesCount : バイト ;
OLDPos : TRPosition ;
始める
MovesCount : = 0 ;
if ( Depth = 0 ) または Mate ( POS。HandSente 、 POS。HandGote 、 color ) then
A : = EstimatePos
他に
始める
カラー=センテの場合
MovesCount : = GenerateMoves ( POS 。 ボード 、色、 POS。HandSente 、 Moves )
他に
MovesCount : = GenerateMoves ( POS。Board 、 color 、 POS.HandGote 、 Moves ) ;
for i : = 1 to MovesCount do
始める
A> = Bの場合
休憩
OLDPOS : = POS ;
MakeMove ( POS 、カラー、 Moves [ i ] ) ;
[ i ]を移動します。 r : = -AB ( POS 、 opcolor (色) 、深さ-1 、 -B 、 -A ) ;
POS : = OLDPos ;
if Moves [ i ] 。 r > A その後
A : = Moves [ i ] 。 r ;
終わり ;
終わり ;
AB : = A ;
終わり ;
最終実装
その結果、私は小さなプログラムを作成し( ダウンロード )、私の意見では、将giを非常に上手く演じています。 もちろん、それは完璧とはほど遠いものであり、修正と改良を必要とするものがたくさんあります。 動きを追加するのはいいことです-ヒューリスティックな評価で王に脅威を与え、プログラムを完成させて本格的な将giのプレイ方法を教えるのは素晴らしいことですが、これらはすべて将来の計画ですが、今のところこの興味深いゲームであなたの手を試すことができます。