最後に、夏の終わりに、Intel 910が登場しました。 SSDの記録に対する有効性に関する以前の懐疑論はすべて払拭されます。
ただし、最初にまず最初に。
Intel 910はPCI-E形式のカードで、かなり堅実なサイズです(個別のグラフィックカードに似ています)。 ただし、投稿をアンパックするのは好きではないので、最も重要なことであるパフォーマンスに移りましょう。
注目を集める絵

数字は実際のものです、はい、それは任意の記録のための10万IOPS'ovです。 カットの下の詳細。
デバイスの説明
しかし、最初に、1つのLSIを4つの日立にドラッグすると、Intelが得られるAlchemy Classicをプレイします。
このデバイスは、特別に適応されたLSI 2008であり、100 GBの容量を持つSSDデバイスが各ポートに「接続」されています。 実際、すべての接続はボード自体で行われるため、接続はデバイスの関係を分析する場合にのみ表示されます。
おおよそのスキームは次のとおりです。
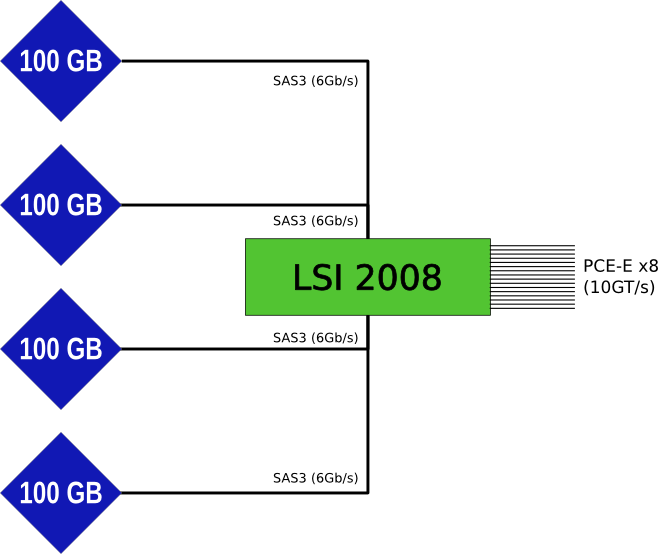
LSI'yコントローラは非常に多く見られていることに注意してください-独自のBIOSがなく、起動可能かどうかもわかりません。 lspciでは、次のようになります。
04:00.0シリアル接続SCSIコントローラー:LSI Logic / Symbios Logic SAS2008 PCI-Express Fusion-MPT SAS-2 [Falcon](rev 03)
サブシステム:Intel Corporationデバイス3700
デバイスの構造(各100 GBの4つのSSD)は、ユーザーがデバイスの使用方法を決定することを意味します-raid0またはraid1(薄い愛好家-raid5、ただし、これはこのクラスのデバイスで実行できる最大の愚かさです) 。
mpt2sasドライバーによって提供されます。
hitachiを宣言する4つのscsiデバイスを接続します。
sg_inq / dev / sdo ベンダー識別:日立 製品識別:HUSSL4010ASS600
拡張sataコマンドはサポートしていません(ほとんどの拡張SASサービスコマンドと同様)-ブロックデバイスとして完全に機能するために最低限必要なものだけです。 幸いなことに、それはresizeオプションでsg_formatをサポートします。これにより、記録がアクティブなときのハウスキーピングへの影響を少なくするために完全な予約を行うことができます。
テスト中
合計で、デバイスの特性を評価するために5つの異なるテストを行いました。
- ランダム読み取りテスト
- ランダム書き込みテスト
- 並列並列読み取り/書き込みテスト(注:実際の場合によくあるように、各スレッドが互いに別々にスラッシングし、リソースを奪い合うため、「読み取り/書き込み」の割合について話す必要はありません)。
- 最大線形読み取りパフォーマンステスト
- 最大線形書き込みパフォーマンステスト
線形読み取りおよび書き込みテスト
一般に、これらのテストは誰にとってもほとんど関心がありません; HDDは「ストリーム」を提供するためにはるかに優れています。 容量が大きく、価格が低く、線形速度が非常に優れています。 raid0に8〜10個のSASディスク(または高速のSATA)を搭載した単純なサーバーは、10ギガバイトのチャネルを完全に詰まらせることができます。
しかし、それでも、指標は次のとおりです。
線形読み取り
最大のパフォーマンスを得るには、デバイスごとに256kの2つのストリームを設定します。 合計パフォーマンス:1680MB / s、ためらわず(偏差はわずか40μs)。 同時に、遅延は1.2msでした(256kブロックの場合、これで十分です)。
実際、これは、この読み取り専用デバイスが10 Gbit / sチャンネルを完全に叩き、20 Gbit / sチャンネルで印象的な結果以上を表示できることを意味します。 同時に、負荷に関係なく、一定の作業速度を示します。 Intel自体は最大2GB / sを約束することに注意してください。
ライン録音
最高の記録数を得るには、キューの深さを低くする必要がありました-デバイスごとに記録ごとに1つのストリーム。 他のパラメーターは同様でした(256kブロック)
ピーク速度(秒数)は1800MB / s、最小-約600MB / sでした。 100%の平均書き込み速度は1228MB / sでした。 記録速度の突然の低下は、ハウスキーピングによるSSDの出生時のトラウマです。 この場合、ドロップは最大600MB / s(約3倍)でした。これは、劣化が最大10-15倍に達する可能性のある旧世代のSSDよりも優れています。 Intelは、リニア録音で約1.6GB / sの速度を約束しています。
ランダムIO
もちろん、誰も直線的なパフォーマンスを気にしません。 誰もが高負荷下でのパフォーマンスに関心があります。 そして、SSDにとって最も難しいことは何ですか? ボリュームの100%を小さなブロックで、多くのストリームで、数時間中断することなく記録します。 320番目のシリーズでは、これによりパフォーマンスが2000 IOPSから300に低下しました。
テストパラメーター:デバイスの4つの部分からのraid0、linux-raid(3.2)、64ビットが実行されます。 混合読み込みの場合、randreadまたはrandwriteモードの各タスクについて2つのタスクを説明します。
一定の割合で読み取りおよび書き込み操作の数を相関させる多くのユーティリティとは異なり、2つの独立したストリームを実行します。1つは常に読み取り、もう1つは常に書き込みを行います(これにより、デバイスに書き込み問題がある場合、デバイスをより完全にロードできます) 、引き続き読書を提供できます)。 その他のパラメーター:direct = 1、buffered = 0、ioモード-libaio、4kブロック。
ランダム読み取り
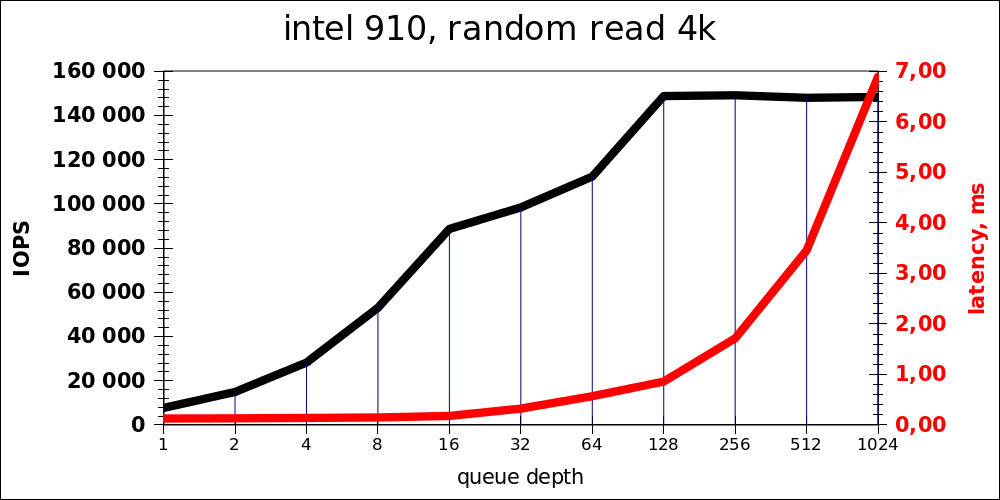
| 十二面体 | IOPS | 平均遅延 |
|---|---|---|
| 1 | 7681 | 0.127 |
| 2 | 14893 | 0.131 |
| 4 | 28203 | 0.139 |
| 8 | 53011 | 0.148 |
| 16 | 88700 | 0.178 |
| 32 | 98419 | 0.323 |
| 64 | 112378 | 0.568 |
| 128 | 148845 | 0.858 |
| 256 | 149196 | 1,714 |
| 512 | 148067 | 3,456 |
| 1024 | 148445 | 6,895 |
最適な負荷は、同時に16〜32の操作のオーダーであることがわかります。 スポーツの関心から1024の長いキューが追加されました。もちろん、これは製品にとって適切な指標ではありません(ただし、この場合でも、待ち時間はかなり高速なHDDレベルで取得されます)。
また、速度がほとんど増加しなくなるポイントは128であることに気付くことができます。内部に4つのピースがある場合、これは各コントローラーの通常のキュー深度32です。
ランダム書き込み
| 十二面体 | IOPS | 平均遅延 |
|---|---|---|
| 1 | 14480 | 0,066 |
| 2 | 26930 | 0,072 |
| 4 | 47827 | 0,081 |
| 8 | 67451 | 0.116 |
| 16 | 85790 | 0.184 |
| 32 | 85692 | 0.371 |
| 64 | 89589 | 0.763 |
| 128 | 96076 | 1,330 |
| 256 | 102496 | 2,495 |
| 512 | 96658 | 5,294 |
| 1024 | 97243 | 10.52 |
同様に、最適なのは16〜32の同時操作の領域であり、非常に大きな(10倍の)レイテンシにより、さらに10k IOPSを圧縮できます。
興味深いことに、低負荷では、書き込みパフォーマンスが高くなります。 同じスケールでの読み取りと書き込み(読み取り-緑)の2つのグラフの比較を次に示します。
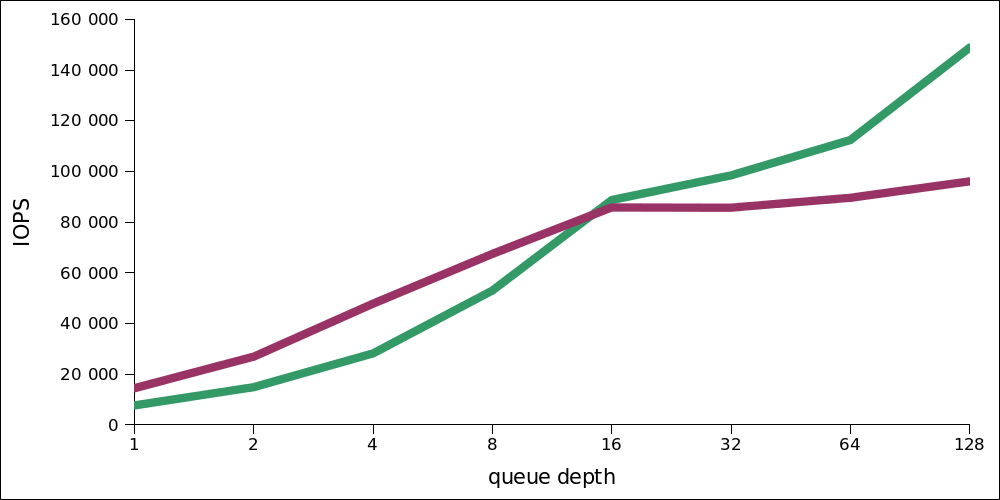
混合負荷
製品環境(OLAPを含む)の実際の負荷を明らかに超えると考えられる最も重いタイプの負荷。
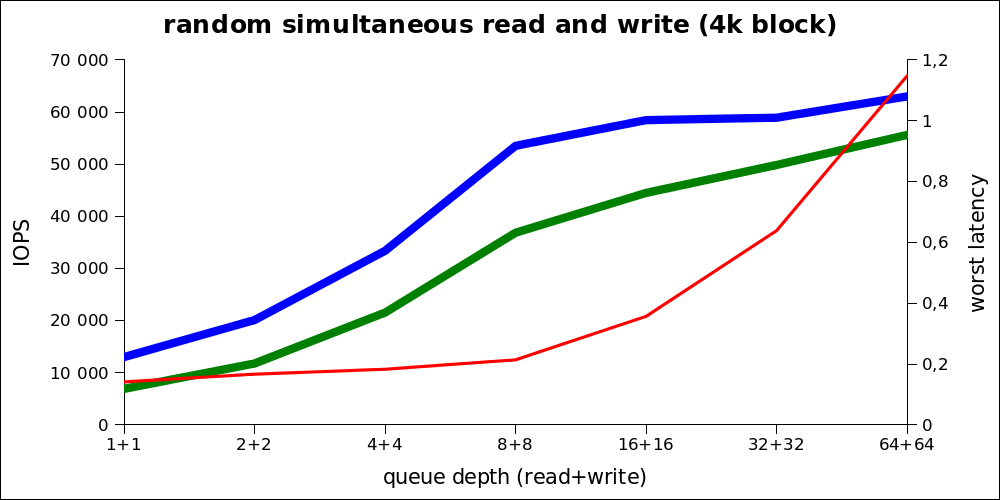
このグラフから実際のパフォーマンスを理解することはできないため、同じ数字を累積形式で示します。
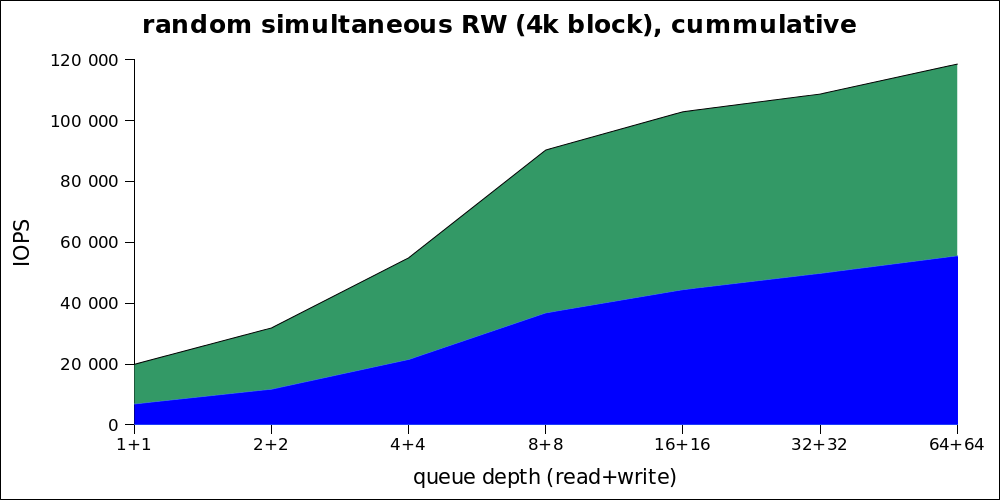
| 十二面体 | IOPS読み取り | IOPS書き込み | 平均遅延 |
|---|---|---|---|
| 1 + 1 | 6920 | 13015 | 0.141 |
| 2 + 2 | 11777 | 20110 | 0.166 |
| 4 + 4 | 21541 | 33392 | 0.18 |
| 8 + 8 | 36865 | 53522 | 0.21 |
| 16 + 16 | 44495 | 58457 | 0.35 |
| 32 + 32 | 49852 | 58918 | 0.63 |
| 64 + 64 | 55622 | 63001 | 1.14 |
最適な負荷は8 + 8(16)から32の領域にもあることがわかります。したがって、非常に高い最大パフォーマンスにもかかわらず、通常の負荷では最大〜80k IOPSについて話す必要があります。
結果として得られる数値は、Intelが約束したものよりも多いことに注意してください。 サイトで、彼らはこのモデルが記録のために35 kIOPSに対応可能であると主張しています。これは、パフォーマンスグラフ上で、およそ6のiodepthに対応します。また、この数字はハウスキーピングの最悪ケースに対応する可能性があります
このデバイスの唯一の欠点は、ホットスワップに関する特定の問題です。PCI-Eデバイスは、交換する前にサーバーを切断する必要があります。