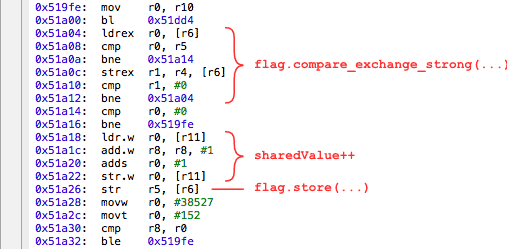
2つのスレッドが20,000,000回ある単純なC ++プログラムは、mutexによって保護された値に1を追加します。出力が異なる結果を生成するたびに、20,000,000未満になります。
sayingにもあるように、敵はCPUです。
彼のブログで、Jeff Preshingはロックフリープログラミング、ノンブロッキングスレッド同期技術に関する多くの記事を公開しています。 含めて、彼はダブルチェックロックの使用とメモリバリアを置く必要性について多くのことを話しました。 ジェフは、1つのデモが1000語よりも優れていると判断しました。
デモプログラムのコード 。2つのストリームのそれぞれが、mutexで保護された
sharedValue
の共有値に
sharedValue
追加します。
その場しのぎのmutexは次のようになります。ビジー状態の場合は値1を取得し、フリー状態の場合は値0を取得する単純なセマフォ。
int expected = 0; if (flag.compare_exchange_strong(expected, 1, memory_order_acquire)) { // The lock succeeded }
引数
memory_order_acquire
および
memory_order_release
を使用すると、一部の人にとって冗長に見えるかもしれませんが、これは、いくつかのスレッドが調整された方法でセマフォ値を調整する必要な保証です。
flag.store(0, memory_order_release);
彼のプログラムでは、Jeffは引数
memory_order_acquire
および
memory_order_release
を意図的に削除して、これが何をもたらすかを示しました。
void IncrementSharedValue10000000Times(RandomDelay& randomDelay) { int count = 0; while (count < 10000000) { randomDelay.doBusyWork(); int expected = 0; if (flag.compare_exchange_strong(expected, 1, memory_order_relaxed)) { // Lock was successful sharedValue++; flag.store(0, memory_order_relaxed); count++; } } }
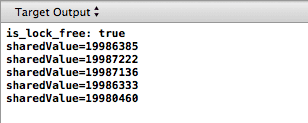
これがXcodeが生成するものです。
iPhoneでプログラムを実行した結果はすでに表示されています。
なぜこれが起こっているのですか? 実際のところ、処理の順序が弱いプロセッサ(CPUの順序が弱い)が要求キューを最適化できるため、命令は想定した順序で実行されません。 たとえば、図は、異なるCPU上の上記の例の2つのスレッドがどのように共通ミューテックスを使用して
sharedValue
値を変更するかを
sharedValue
ます。
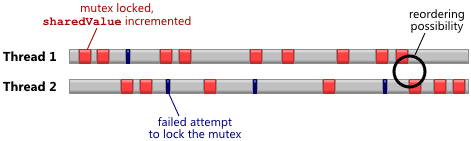
ミューテックスをブロックして値を変更しようとする試みが成功すると赤で表示され、別のスレッドによってブロックされたミューテックスへのアクセスが失敗すると黒で表示されます。 1つのスレッドがミューテックスのみを解放し、2番目のスレッドがそれをブロックする準備ができた瞬間、この瞬間は、CPUの観点から、要求キューを並べ替えるのに最適です。
CPUがリクエストキューを並べ替える理由は、別の記事のトピックです。 これに対抗するには、いくつかの隣接する命令を共有するメモリバリアをインストールし、それらが場所を切り替えないようにする必要があります。 これが、
memory_order_acquire
および
memory_order_release
引数の目的です。 それらを彼らの場所に戻します。
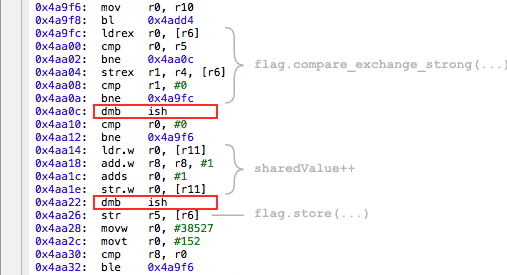
void IncrementSharedValue10000000Times(RandomDelay& randomDelay) { int count = 0; while (count < 10000000) { randomDelay.doBusyWork(); int expected = 0; if (flag.compare_exchange_strong(expected, 1, memory_order_acquire)) { // Lock was successful sharedValue++; flag.store(0, memory_order_release); count++; } } }
この場合のコンパイラは、ARMv7でメモリバリアとして
dmb ish
命令を挿入します。
そして、ミューテックスはすでに普通に仕事を始めており、
sharedValue
共通値を確実に保護しています。
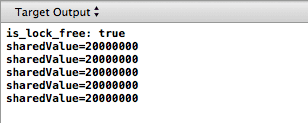
現在、Weakly-Orderedプロセッサの大規模な使用に直面しています。 以前は、マルチコアPowerPCがあったサーバーまたは過去の高性能「ポピー」でのみ使用されていました。 今、マルチコアARM-すべての携帯電話で。 そのため、モバイルアプリケーションを開発するときには、このニュアンスを考慮する必要があります。
「特別にバグのある」Presingコードでは、エラーの確率は1〜1000であり、通常のプログラムでは1〜1.000.000です。つまり、このようなグリッチはテスト中にキャッチするのが非常に困難です。 プログラムは完全に999.999回実行でき、次回クラッシュすることもあります。