ほとんどのストレージシステムの主な問題は新しいものではありません-ボリュームレベルのデータ管理です。 このアプローチでは、当初、柔軟性だけでなく、複合施設のパフォーマンスも制限されます。 問題は主な問題ですが、決して唯一の問題ではないことを直ちに予約してください。 ただし、最初にまず最初に。
動作原理
ウェブマスターの間で知られているジョークがあります。「すべてを迅速、効率的、安価に行います。 任意の2つのポイントを選択します。」 最近まで、それはデータストレージシステムにある程度当てはまりました。 情報にすばやくアクセスする必要がある場合は、SSDに保存する必要があります。 しかし、彼らのアキレス腱は、比較的低容量の高コストで構成されていました。 一方、従来のソリューションには反対の利点がありました。低価格と大量生産です。 はい、SSDと比較してアクセス速度が大きいだけが災害でした。 Dell Compellentは、Fluid Dataの新しい動的アーキテクチャのおかげで、両方のアプローチを組み合わせたストレージシステムの開発における論理的な進化のステップでした。 アクティブモードの後者は、ボリュームレベルではなくブロックレベルでデータをインテリジェントに管理します。 それぞれについてのさまざまな情報がオンザフライで継続的に収集され、動的ストレージ、移行、およびデータ回復の機能を操作するために使用されます。 このデータを収集すると、システムの負荷が最小限に抑えられ、保存されたデータや使用済みディスクの種類、RAIDレベル、記録時間、データアクセスの頻度などの特性に関する詳細情報を取得できます。 利益は明らかです。情報は常に利用可能で保護されており、アプリケーションははるかに高速に展開され、新しいテクノロジーはすぐにサポートされます。 しかし、それがどのように機能するかを見てみましょう。
デルのエンジニアがストレージで最初に戦うことを決めたのは、ボリュームを作成する際のディスクスペースの浪費です。 従来、管理者は特定のアプリケーションに必要な容量を計算し、それを「念のため」に投げて、最終的には事前に定義された過剰なボリュームでボリュームを作成します。 一般に、このアプローチは正しいですが、問題は未使用の容量を再配布できないことです。 つまり、ギガバイト単位でボリュームを作成した場合、このギガバイトはすべて1つのアプリケーションでのみ使用可能になり、他のアプリケーションは「そのまま」残ります。 実際には、多くの場合、アプリケーションは割り当てられた容量の半分未満を使用するため、「凍結」スペースのストックが企業のストレージに形成され、そのためにお金が無駄になります。 それにもかかわらず、再保険のために、多くの企業はまだそのようなステップを取っています。
いいですか? ほとんどない。 管理者は、当初必要だった容量よりも多くの容量を購入せざるを得ません。 同時に、しばらくして容量が使い果たされると、新しいディスクを購入する必要があります。そのため、ストレージに追加のラックを設置する必要がある場合があります。 そして、これは、成長する「頭脳」のエネルギー供給、冷却、および管理は言うまでもありません。
これらの問題を解決するために、Dell CompellentはDynamic Capacityソフトウェアを使用します。これにより、リソースの割り当てと使用が完全に分離されます。 この機能自体はシンプロビジョニングと呼ばれます。 その本質は、システムをインストールした直後に、管理者が任意のサイズの仮想ボリュームを割り当てることができるという事実にありますが、物理容量はデータがディスクに書き込まれるときにのみ消費されます。 これは、顧客が今日のデータを保存するのに必要なだけの容量を購入できるようになり、ビジネスのニーズの拡大に応じて(必要に応じて)徐々に購入できることを意味します。 ほとんどの場合、シンプロビジョニングを使用すると、企業は従来の成長プロビジョニングと比較して、ディスクスペースを最大40〜60%節約できます。 また、シンインポート機能を使用すると、レガシーストレージシステムで作成されたボリュームの未使用容量を解放することもできます。
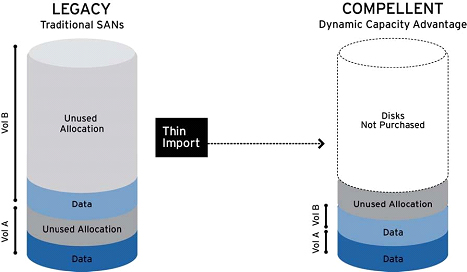
だから、空間の効率的な分布を理解したとき、彼についていくつかの言葉を言う時でした。
バーチャルな喜び
ブロックレベルのデータ管理により、Dell Compellentシステムはディスクレベルのストレージを仮想化できるため、システムの柔軟性が大幅に向上します。 管理者は、特定のサーバー間で特定のディスクを配布する必要がなくなりました-代わりに、システム内のすべてのディスクにまたがる共通のリソースプールが作成されます。 サーバーは、ディスクタイプ、RAIDレベル、またはサーバー接続に関係なく、ストレージリソースを単に利用可能な容量として「認識」します。 したがって、特定の時点でのすべてのストレージリソースは、すべてのサーバーで使用できます。 機能とは、アプリケーションに十分な容量がない場合にシステムが自動的にボリュームを拡張する機能です。
このアーキテクチャでは、読み取り/書き込み操作がすべてのドライブに分散されるため、複数のI / O要求を並行して処理できます。 その結果、従来のストレージシステムのボトルネックが解消されます。 プールに容量が追加されると、使用可能なすべてのディスクにデータが自動的に再配分されるため、管理者は負荷分散とパフォーマンスチューニングを手動で処理する必要がありません。
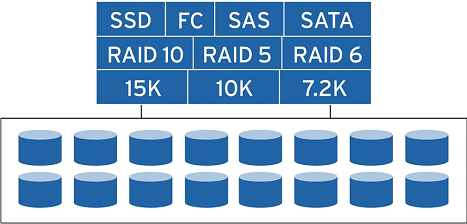
ストレージ仮想化により、サーバー仮想化の実装効果が大幅に向上します。ユーザーは、何百もの仮想ボリュームをすばやく作成して、任意のサーバープラットフォームをサポートできます。
データフロー
デザートについては、いつものように、最も「おいしい」、つまり動的分類とデータ移行のテクノロジーを残すことが決定されました。 データを効果的に保存する方法をすでに学習していることを前提としています。 次のステップは、このデータへのアクセスを効率的に整理することです。 問題の本質を理解するために、次の例えを検討してください。
靴下を保管しているアパートの場所を覚えていますか? 確かに近くのどこかに:クローゼットの中に、引き出しの中や、目の前の床に散らばっています。 今、覚えておいて、ビーチパラソルまたはエアマットレスはどこですか? バルコニーで、中二階で? 最後に、最後の質問:これらのものを逆に保存しないのはなぜですか? 答えは明らかです。 靴下は非常に頻繁に使用されます。つまり、靴下へのアクセスはできるだけ便利で高速でなければなりません。 動的分類およびデータ移行テクノロジーは同じ原則を使用します。

新しいデータは、最初のTier 1ストレージレベルのSAS / FC 15Kディスクに書き込まれ、アクセス頻度が分析され、減少するにつれて、アクティブなデータブロックが2番目のストレージレベルのFCまたはSASディスクに移行します。 しばらくすると、長期間アクセスされていないデータは、第3ストレージレベルの大容量SASまたはSATAディスクに転送されます。 さらに、各レベルで異なるタイプのRAIDが使用され、データはレベル内でそれらに沿って動的に移動されます(たとえば、RAID10からRAID5へ)。
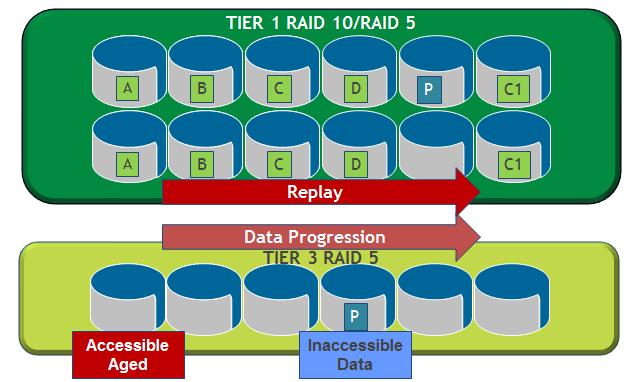
さらに、アクセス速度を上げるために、最もアクティブなデータが各ディスクの外部セクターに保存されます。 システムロジックは両方の方法で機能します。 つまり、パッシブデータに対して複数の呼び出しが行われた場合、それらはより高いレベルに移動します。 管理者は、会社の特定のタスクに従ってレベル間を移動するアルゴリズムを調整するか、工場出荷時のデフォルト値を使用します。
続く
もちろん、これらはFluid Dataのすべての利点や機能とはほど遠いものです。 別の話は、リモートサイトへのデータの複製、保護と回復の機能、プラットフォームのスケーラビリティ、さらにはインターフェイスです。 しかし、これらすべてを1つの記事にしようとすると、一方では尊敬されるハブロフスク市民をそのような資料の量で恐ろしくするか、「すべてについて、しかし少し」百科事典のように見せかける危険があります。 幸いなことに、2つのオプションのいずれかを選択する必要はありません。したがって、Fluid Dataの場合のように、独自の方法を考えて、テクノロジーに関するストーリーを2つの部分に分けます。 続行するには...