はじめに
これは、既存のOCRの単なるレビューではなく( 3つだけについて説明します)、インストールガイドではありません(インストールについて説明します)。 この記事は、Linuxでロシア語と英語を実際に認識する方法とその方法を理解するために作成されました。
説明されたプロセスの本質を理解するためのいくつかの言葉。
OCR-光学式文字認識。
印刷された文書をデジタル化するには技術が必要です。 自動化の目的でOCRを使用するものもあります(たとえば、キャプチャを認識したり、スパムボットから保護するため)。
LinuxのOCR
繰り返しますが、ここではロシア語を認識するプログラムを検討します。 Linuxでは、ラテン語で動作するように設計されたいくつかのOCRがあります。たとえば、ヘブライ語でのみ動作する特殊な複合体があります。これはすべてこのトピックには当てはまりません。
実際、 Cuneiform 、 Tesseract 、 Finereader Engineの 3つの製品についてのみ説明します。 GUIは最初の2つ用に開発されていますが、それら自体はすべてコンソールインターフェイスのみを提供します。
私はDebian Squeezeを使用しますが、ソースへのリンクを提供し、パッケージのアセンブリについて説明します( notesalexp.orgのリポジトリまたはディストリビューションのリポジトリを使用できます-アセンブリの例を示します)。
トピックは次の順序で展開されます。
1. OCR for Linux(3エンジン)のインストール、インストール。
2.例によるCLI OCRの比較。
3. OCRのGUI、それらの比較。
4.小規模なテストオンラインOCR。
5.結論といくつかの予測と提案。
Linux用OCRをインストールする
くさび形
ウィキペディアのプロジェクトに関するページ。
宣言された機能:多くの言語のサポート、元の文書の書式設定の保存、txtへの出力、hocr、html、マトリックスプリンターで印刷されたFAXおよびテキストの認識。
LinuxでCuneiformを使用する2つの実際の方法について説明します。ネイティブとWineを使用します(これは必要です。以下を参照してください)。
1.ネイティブ楔形
ランチパッドのセクション
ソースコード
インストールを進めましょう。
ソースをダウンロードして展開します。
さらに、すべてが標準です(ソースを含むreadme.txtを参照)。 ソースがあるディレクトリに移動し、順番に実行します。
mkdir builddir cd builddir cmake -DCMAKE_BUILD_TYPE=debug .. make sudo checkinstall sudo ldconfig
できた
2. Wineでのインストール。
この方法の利点は、元の機能的なGUIをすぐに取得できることです。 Wineバージョンは重要ではありません(CuneiformはWine 1.0でも動作しました)。 唯一の機能:Wine設定でmsvcrtライブラリの新しい置換を指定する必要があります。
配布物はこのリンクから入手できます。
テッセラクト。
ウィキペディアのプロジェクトに関するページ。
Google Codeのページ。
宣言された機能:多くの言語のサポート、txtおよびhocrへの出力、独自のサンプルを使用したプログラムのトレーニング(これはそのままでは動作しません)、特定のサンプルの構成ファイルの使用。
このReadmeについて簡単かつ自由に説明します。
インストール前の依存関係の解決:
sudo apt-get install autoconf automake libtool libpng12-dev libjpeg62-dev libtiff4-dev zlib1g-dev
Tesseractは、1.67以上のlibleptonica-devバージョンにも依存しています。 Squeezeでは、このパッケージは廃止されたため、収集する必要がありました。
ソースコードを取得し、解凍してビルドします。
./autobuild ./configure make sudo checkinstall sudo ldconfig
Tesseractソースを取得し、それらを展開してディレクトリに移動します。
次に行うこと:
./autogen.sh ./configure make sudo checkinstall sudo ldconfig
Tesseractがインストールされます。 言語認識用のパッケージ( ロシア語と英語)を受け取り、tessdataディレクトリー(デフォルトでは/ usr / local / share / tessdata )に解凍します。
働くことができます。
FineReader Engine
ここで発表を見れます 。
入手方法 私たちはここに行き、注意深く読んでトライアルを要求します(100回の認識の制限)。 あなたはロシア語で尋ねることができます。
インストールは簡単です: ダウンロードして 、 ルートの下でabbyyocr.runを実行し、テキストの指示に従います。
宣言された機能:多くの言語、さまざまなエンコードのサポート、パスワードの操作、ページ番号、テーブルの認識、バーコード、マトリックスプリンターで印刷されたテキスト、タイプライター、ゴシックフォントなど、txt、rtf、html、xmlへの出力、 xls。
Rubyquet +
CLI OCRについて説明したので、TesseractとCuneiformのCLI Rubyquet +について説明します。
私はそれをテストしませんでした(これを行うことができます)-前述のOCRの同じCLIも独自に利用できます。
CLI OCRの比較
* CLI-コマンドラインインターフェイス-コマンドラインインターフェイス(「コンソール」)。
すぐに警告します。このセクションは非常に膨大です。 不要な詳細や大量の手紙なしでやりたい場合-ネタバレを開かないことをお勧めします。
覚えておいてください:私は比較において絶対に客観的であるふりをしません。 他の結果や他の結論が得られる場合があります。
テストの基準を示します。
もちろん、完全な結果は、すべての文字、書式設定、および図面を100%認識できるはずです。 ただし、実際には、最も一般的なのはテキスト認識です。 ユーザーは、必要な書式設定を実行し、後処理中にテキストを画像で補うことができます。
認識の品質を評価するために、次の基準を紹介します(ただし、基準からは離れます)。
「 間違った単語 」の基準-計算を簡単にするための誤って認識された単語(単語内の1つの誤った文字から完全に単語がなくなるまで)が最も重要な基準です。
「 無効な文字 」基準-最初の基準を適用できない場合に誤って認識された文字(余分な文字、句読点など)。
基準「 書式設定エラー 」-表、図、太字および斜体での記述の定義に関する作業の品質を決定するために使用されます。
各サンプルおよびプログラムについて、正しく認識された単語の割合が計算され、これが基本的な要因になります。 サンプル内の単語数は、Finereaderで認識結果を取得します。
サンプルについて。
私たちが最もよく認識することは何ですか? スキャナーを通過したドキュメント、またはドキュメントの写真。 当然、品質と解像度が異なります(OCRでは少なくとも300 dpiとしてスキャンすることをお勧めします。200dpi、300 dpi、600dpiでスキャンしたサンプルを比較しましょう。2MPと5MPの品質で撮影した写真を使用します)。 さらに、一部のサンプルには表と写真が含まれます。
私はそれらへのリンクの形で認識可能な画像を提供します(記事に直接存在することは干渉するだけです)。 最初のリンクによる認識結果はGoogleドキュメントで、2番目のリンクは「オリジナル」とマークされ、Dropboxの元の形式で利用できます。
レビューを煩雑にしないために、ソース画像と結果のテキストのパスの代わりに、それぞれINPUTとOUTPUTを記述します。
サンプル番号1(番号付きリスト)。
試験サンプルNo.1
そのため、200 dpi(1インチあたりのドット数)でスキャンされたこの質問リストが最初に手に入れられ、研究全体で常に使用されていました。
0001.png
サンプルの特徴:実際には、いくつかのラテン文字を含むロシア語の2列(番号付けとテキスト自体)に分割されています。
1. くさび形 。
構文:
テキストでロシア語と英語を認識します(それぞれ
または
になります)。
-RTF出力フォーマット(フォーマットの保存を試行);
テキストを単一の列として認識します。
テキストを含むファイルへのパス。
は画像へのパスです。
結果:
0001.png.cun.rtf
( オリジナル )
間違った単語:14(テキスト内の728単語)
無効な文字:7
書式設定エラー:段落を入れずに、誤って斜体で入力したことがあります。
結論:単語認識の精度は約98%です。 主な間違いは、「and」と「n」の混同です。 ある場所では、ラテン語のアルファベットをなんとか認識できました。
すべてのすべて、良い。
2. Tesseract 。
構文:
-tesseractは一度に2言語をサポートしません。
「単一のテキストブロックを想定する」、つまり 結果のテキストを単一のブロックにフォーマットします(そうでない場合、番号付けはテキスト全体の前にきちんと配置されます-ブロックはすべて同じです)。
結果(RTFで保存できません):
0001.png.tes.txt
( オリジナル )
間違った単語:6(テキスト内の728単語)
間違った文字:5
書式設定エラー:テキストファイルに出力する場合、元の書式設定を保存することは不可能です。楔形よりも段落の方がうまく機能し、技術的にラテン文字を認識できません。
結論:単語認識の精度は約99%です。 テキストは楔形文字を使用する場合よりも見栄えがよくなります。
3. ファインリーダー 。
すぐに、大きなマイナスに注意します。私が理解しているように、Finereaderはスーパーユーザー権限でのみ動作します。
構文:
語と英語のテキスト言語。
-
への出力。
0001.png.fin.rtf
( オリジナル )
間違った単語:2(テキスト内の728単語)
無効な文字:0
フォーマットエラー:ほぼ完璧。 単語の2つのエラー-ラテンアルファベットを認識できませんでした。
結論:ほぼ100%の精度。
モデルNo. 1の結論 :Finereaderが1位、Tesseractが2位、Cuneiformが3位に最小マージンで参加します。
0001.png
サンプルの特徴:実際には、いくつかのラテン文字を含むロシア語の2列(番号付けとテキスト自体)に分割されています。
1. くさび形 。
cuneiform -l ruseng -f rtf --singlecolumn -o 'OUTPUT' 'INPUT'
構文:
-l ruseng
テキストでロシア語と英語を認識します(それぞれ
rus
または
eng
になります)。
-f rtf
-RTF出力フォーマット(フォーマットの保存を試行);
--singlecolumn
テキストを単一の列として認識します。
-o 'OUTPUT'
テキストを含むファイルへのパス。
'INPUT'
は画像へのパスです。
結果:
0001.png.cun.rtf
( オリジナル )
{kind=link}
間違った単語:14(テキスト内の728単語)
無効な文字:7
書式設定エラー:段落を入れずに、誤って斜体で入力したことがあります。
結論:単語認識の精度は約98%です。 主な間違いは、「and」と「n」の混同です。 ある場所では、ラテン語のアルファベットをなんとか認識できました。
すべてのすべて、良い。
2. Tesseract 。
tesseract 'INPUT' 'OUTPUT' -l rus -psm 6
構文:
-l rus
-tesseractは一度に2言語をサポートしません。
-psm 6
「単一のテキストブロックを想定する」、つまり 結果のテキストを単一のブロックにフォーマットします(そうでない場合、番号付けはテキスト全体の前にきちんと配置されます-ブロックはすべて同じです)。
結果(RTFで保存できません):
0001.png.tes.txt
( オリジナル )
{kind=link}
間違った単語:6(テキスト内の728単語)
間違った文字:5
書式設定エラー:テキストファイルに出力する場合、元の書式設定を保存することは不可能です。楔形よりも段落の方がうまく機能し、技術的にラテン文字を認識できません。
結論:単語認識の精度は約99%です。 テキストは楔形文字を使用する場合よりも見栄えがよくなります。
3. ファインリーダー 。
すぐに、大きなマイナスに注意します。私が理解しているように、Finereaderはスーパーユーザー権限でのみ動作します。
sudo abbyyocr9 -rl Russian English -if 'INPUT' -f RTF -of 'OUTPUT'
構文:
-rl Russian English
語と英語のテキスト言語。
-f RTF
-
-f RTF
への出力。
0001.png.fin.rtf
( オリジナル )
{kind=link}
間違った単語:2(テキスト内の728単語)
無効な文字:0
フォーマットエラー:ほぼ完璧。 単語の2つのエラー-ラテンアルファベットを認識できませんでした。
結論:ほぼ100%の精度。
モデルNo. 1の結論 :Finereaderが1位、Tesseractが2位、Cuneiformが3位に最小マージンで参加します。
サンプルNo. 2(スキャンされた英語の教科書)。
試験サンプルNo.2
0002.png
1. くさび形 。
結果:
0002.png.cun.rtf
( オリジナル )
間違った単語:2(テキスト内の534単語)
無効な文字:6
書式エラー:脚注を一重引用符として認識し、角括弧、ハイフン、ダッシュに対応できませんでした。 単語の転写を認識できませんでした。
結論:言葉の99%。 いいね
CuneiformV12が認識するバージョン:
0002.cun.win.rtf
( オリジナル )
結果は、ネイティブバージョンの結果に近いです。
2. Tesseract 。
結果:
0002.png.tes.txt
( オリジナル )
間違った単語:1(テキスト内の534単語)
無効な文字:4
書式エラー:いくつかの余分な文字が見つかりましたが、脚注に対処できませんでした。
結論:言葉の99%。 くさび形よりも良い。
3. ファインリーダー 。
結果:
0002.png.fin.rtf
( オリジナル )
間違った単語:0(テキスト内の534単語)
無効な文字:2
書式エラー:1つの脚注とページ番号を認識しませんでした。
結論:イタリック体で認識される単語の100%。 最良の結果。
0003.png
1. くさび形 。
0003.png.cun.rtf
( オリジナル )
認識品質は同じレベルです。
2. Tesseract 。
0003.png.tes.txt
( オリジナル )
突然、認識の質が低下しました。 Tesseractは、水平線をポイントとシンボルの集まりとして認識しました。 さらに、テキスト自体に余分な文字(チルダ、一重引用符)が表示されました。
3. ファインリーダー 。
0003.png.fin.rtf
( オリジナル )
認識品質は同じレベルです。
0004.png
1. くさび形 。
0004.png.cun.rtf
( オリジナル )
品質が低下しています。 余分な文字が表示され、ハイフンとダッシュはまだ認識されず、単語「Unit」の文字「U」が失われます。
2. Tesseract 。
0004.png.tes.txt
( オリジナル )
「ユニット6」はなく、ページ番号もありません。いくつかの引用符が追加されています。
3. ファインリーダー 。
0004.png.fin.rtf
( オリジナル )
ページ番号が表示され、それに伴いドットのセットになった水平線が表示されました。 品質は向上していません。
サンプルNo. 2の結論 :3つのシステムすべてについて、200 dpiの画質が最適でした。 1インチあたりのドットの密度が増加すると、認識の低下が発生したか、単に改善が見られませんでした。
Finereaderを作業の質で最初に、Tesseractを2番目に(RTFをサポートしていないことを覚えておく必要があります)、Cuneiformを3番目に(最小のラグで)配置しました。
200dpi。
0002.png
1. くさび形 。
cuneiform -l eng -f rtf --singlecolumn -o 'OUTPUT' 'INPUT'
結果:
0002.png.cun.rtf
( オリジナル )
{kind=link}
間違った単語:2(テキスト内の534単語)
無効な文字:6
書式エラー:脚注を一重引用符として認識し、角括弧、ハイフン、ダッシュに対応できませんでした。 単語の転写を認識できませんでした。
結論:言葉の99%。 いいね
CuneiformV12が認識するバージョン:
0002.cun.win.rtf
( オリジナル )
結果は、ネイティブバージョンの結果に近いです。
2. Tesseract 。
tesseract 'INPUT' 'OUTPUT' -l eng -psm 6
結果:
0002.png.tes.txt
( オリジナル )
{kind=link}
間違った単語:1(テキスト内の534単語)
無効な文字:4
書式エラー:いくつかの余分な文字が見つかりましたが、脚注に対処できませんでした。
結論:言葉の99%。 くさび形よりも良い。
3. ファインリーダー 。
sudo abbyyocr9 -rl English -if 'INPUT' -f RTF -of 'OUTPUT'
結果:
0002.png.fin.rtf
( オリジナル )
{kind=link}
間違った単語:0(テキスト内の534単語)
無効な文字:2
書式エラー:1つの脚注とページ番号を認識しませんでした。
結論:イタリック体で認識される単語の100%。 最良の結果。
同じチュートリアル、300 dpi。
0003.png
1. くさび形 。
0003.png.cun.rtf
( オリジナル )
{kind=link}
認識品質は同じレベルです。
2. Tesseract 。
0003.png.tes.txt
( オリジナル )
{kind=link}
突然、認識の質が低下しました。 Tesseractは、水平線をポイントとシンボルの集まりとして認識しました。 さらに、テキスト自体に余分な文字(チルダ、一重引用符)が表示されました。
3. ファインリーダー 。
0003.png.fin.rtf
( オリジナル )
{kind=link}
認識品質は同じレベルです。
同じチュートリアル、600 dpi。
0004.png
1. くさび形 。
0004.png.cun.rtf
( オリジナル )
{kind=link}
品質が低下しています。 余分な文字が表示され、ハイフンとダッシュはまだ認識されず、単語「Unit」の文字「U」が失われます。
2. Tesseract 。
0004.png.tes.txt
( オリジナル )
{kind=link}
「ユニット6」はなく、ページ番号もありません。いくつかの引用符が追加されています。
3. ファインリーダー 。
0004.png.fin.rtf
( オリジナル )
{kind=link}
ページ番号が表示され、それに伴いドットのセットになった水平線が表示されました。 品質は向上していません。
サンプルNo. 2の結論 :3つのシステムすべてについて、200 dpiの画質が最適でした。 1インチあたりのドットの密度が増加すると、認識の低下が発生したか、単に改善が見られませんでした。
Finereaderを作業の質で最初に、Tesseractを2番目に(RTFをサポートしていないことを覚えておく必要があります)、Cuneiformを3番目に(最小のラグで)配置しました。
サンプルNo. 3(写真付きの英語の教科書)。
試験サンプルNo.3
この画像の主な特徴は、輝度の不均一な分布とぼやけの可能性です(フラッシュを使用せずに遅いシャッタースピードで撮影した場合の「揺れ」)
手動による画像補正を行わないことにすぐに同意します(1つの例を除く):削除と削除の両方。
0005.JPG
1. くさび形 。
0005.JPG.cun.rtf
( オリジナル )
テキストの約40%が認識され、残りはさまざまなキャラクターの混乱に変わりました。
この画像のWineの下のCuneiformV12は 、ほんの数語を認識しました。 例を挙げません。
2. Tesseract 。
0005.JPG.tes.txt
( オリジナル )
結果は楔形文字よりもはるかに優れています。 テキストの約80%が正しく認識されます。
3. ファインリーダー 。
0005.jpg.fin.rtf
( オリジナル )
間違った単語:3(テキスト内の534単語)
無効な文字:0
書式エラー:1つの脚注とページ番号を認識しませんでした。
結論:99%の精度。 素晴らしい。
0006.JPG
1. くさび形 。
0006.JPG.cun.rtf
( オリジナル )
テキストの約20%が認識されているため、結果は完全に不適切です。
2. Tesseract 。
0006.JPG.tes.txt
( オリジナル )
テキストの約30%を認識しました。
3. ファインリーダー 。
0006.JPG.fin.rtf
( オリジナル )
テキストの約95%を認識しました。
0007.JPG
1. くさび形 。
0007.JPG.cun.rtf
( オリジナル )
いくつかの単語を認識しました。
2. Tesseract 。
0007.JPG.tes.txt
( オリジナル )
数十の単語を認識しました。
3. ファインリーダー 。
0007.JPG.fin.rtf
( オリジナル )
さらに、Finereaderは上位クラスを示しています。テキストの約85%が認識されています。
0008.JPG
1. くさび形 。
0008.JPG.cun.rtf
( オリジナル )
数十の単語を認識しました。
2. Tesseract 。
0008.JPG.tes.txt
( オリジナル )
テキストの約60%を認識しました。
3. ファインリーダー 。
0008.JPG.fin.rtf
( オリジナル )
テキストの約95%を認識しました。
サンプル番号3の結論 :ここで、Finereader Engineが約400 MBのサイズである理由が明らかになります。OCRを備えた画像処理アルゴリズムを備えているため、写真を認識するときに一貫して良い結果が得られます。 楔形文字とTesseractを使用することで、適切な予備処理を行わずに写真を認識しないことをお勧めします。
手動による画像補正を行わないことにすぐに同意します(1つの例を除く):削除と削除の両方。
フラッシュ付き5MP。
0005.JPG
1. くさび形 。
0005.JPG.cun.rtf
( オリジナル )
{kind=link}
テキストの約40%が認識され、残りはさまざまなキャラクターの混乱に変わりました。
この画像のWineの下のCuneiformV12は 、ほんの数語を認識しました。 例を挙げません。
2. Tesseract 。
0005.JPG.tes.txt
( オリジナル )
{kind=link}
結果は楔形文字よりもはるかに優れています。 テキストの約80%が正しく認識されます。
3. ファインリーダー 。
0005.jpg.fin.rtf
( オリジナル )
{kind=link}
間違った単語:3(テキスト内の534単語)
無効な文字:0
書式エラー:1つの脚注とページ番号を認識しませんでした。
結論:99%の精度。 素晴らしい。
フラッシュなしの5MP。
0006.JPG
1. くさび形 。
0006.JPG.cun.rtf
( オリジナル )
{kind=link}
テキストの約20%が認識されているため、結果は完全に不適切です。
2. Tesseract 。
0006.JPG.tes.txt
( オリジナル )
{kind=link}
テキストの約30%を認識しました。
3. ファインリーダー 。
0006.JPG.fin.rtf
( オリジナル )
{kind=link}
テキストの約95%を認識しました。
画像の前処理について
予備的な画像処理により認識品質が向上する簡単な例を示します( imagemagickを使用して、前の画像で正規化してコントラストを高めます)。
結果:
0006_2.JPG
1. くさび形 。
0006_2.JPG.cun.rtf
( オリジナル )
2. Tesseract 。
0006_2.JPG.tes.txt
( オリジナル )
あなたはそれを自分で比較することができます:今、結果は間違いなく優れています。
convert 'INPUT' -normalize 'OUTPUT'
結果:
0006_2.JPG
1. くさび形 。
0006_2.JPG.cun.rtf
( オリジナル )
{kind=link}
2. Tesseract 。
0006_2.JPG.tes.txt
( オリジナル )
{kind=link}
あなたはそれを自分で比較することができます:今、結果は間違いなく優れています。
フラッシュ付き2MP。
0007.JPG
1. くさび形 。
0007.JPG.cun.rtf
( オリジナル )
{kind=link}
いくつかの単語を認識しました。
2. Tesseract 。
0007.JPG.tes.txt
( オリジナル )
{kind=link}
数十の単語を認識しました。
3. ファインリーダー 。
0007.JPG.fin.rtf
( オリジナル )
{kind=link}
さらに、Finereaderは上位クラスを示しています。テキストの約85%が認識されています。
フラッシュなしの2MP。
0008.JPG
1. くさび形 。
0008.JPG.cun.rtf
( オリジナル )
{kind=link}
数十の単語を認識しました。
2. Tesseract 。
0008.JPG.tes.txt
( オリジナル )
{kind=link}
テキストの約60%を認識しました。
3. ファインリーダー 。
0008.JPG.fin.rtf
( オリジナル )
{kind=link}
テキストの約95%を認識しました。
サンプル番号3の結論 :ここで、Finereader Engineが約400 MBのサイズである理由が明らかになります。OCRを備えた画像処理アルゴリズムを備えているため、写真を認識するときに一貫して良い結果が得られます。 楔形文字とTesseractを使用することで、適切な予備処理を行わずに写真を認識しないことをお勧めします。
サンプルNo. 4(スキャンした画像の表と図の認識)。
試験サンプルNo.4
画像:
0009.png
1. くさび形 。
0009.png.cun.rtf
( オリジナル )
結論:失敗しました。
同時に、Wineの下のCuneiformV12は良い結果をもたらしました(画像の半分を失いましたが、テーブルを管理しました)。
0009.cun.wine.rtf
( オリジナル )
2. Tesseract
残念ながら、彼は書式付きテキストを提供できません。
3. ファインリーダー 。
0009.png.fin.rtf
( オリジナル )
このドキュメントをWriterで開いたとき、私は非常に驚いていました。 テーブルがありませんでした (奇妙なことに、RTFのような古い形式とシンプルな形式の実装の違い?..)。 ただし、WordおよびGoogle DocsはこのRTFを正しく開きました。
Finereaderは、図面とテーブルの両方で素晴らしい仕事をしました。
サンプル番号4の結論 :最初はFinereader、2番目はCuneiformV12(ネイティブCuneiformはタスクに対応していませんでした)。
0009.png
1. くさび形 。
cuneiform -l ruseng -f rtf -o 'OUTPUT' 'INPUT'
0009.png.cun.rtf
( オリジナル )
{kind=link}
結論:失敗しました。
同時に、Wineの下のCuneiformV12は良い結果をもたらしました(画像の半分を失いましたが、テーブルを管理しました)。
0009.cun.wine.rtf
( オリジナル )
2. Tesseract
残念ながら、彼は書式付きテキストを提供できません。
3. ファインリーダー 。
0009.png.fin.rtf
( オリジナル )
{kind=link}
このドキュメントをWriterで開いたとき、私は非常に驚いていました。 テーブルがありませんでした (奇妙なことに、RTFのような古い形式とシンプルな形式の実装の違い?..)。 ただし、WordおよびGoogle DocsはこのRTFを正しく開きました。
Finereaderは、図面とテーブルの両方で素晴らしい仕事をしました。
サンプル番号4の結論 :最初はFinereader、2番目はCuneiformV12(ネイティブCuneiformはタスクに対応していませんでした)。
サンプルNo. 5(スキャンされた教科書「金属構造」)。
試験サンプルNo.5
0010.png
1. くさび形 。
結果:
0010.png.cun.rtf
( オリジナル )
不適切な単語:17(テキスト310の単語)
無効な文字:12
書式エラー:ダッシュ、段落記号、およびパーセンテージを認識しませんでした。 認識の問題「Y」。 誤って認識された斜体。
結論:言葉の95%。 よく見えません
CuneiformV12が認識するバージョン:
0010.cun.win.rtf
( オリジナル )
品質は明らかにネイティブバージョンよりも高くなっています。
2. Tesseract 。
結果:
0010.png.tes.txt
( オリジナル )
間違った単語:8(テキストの310単語)
無効な文字:15
フォーマットエラー:「:」の認識に関する問題。
結論:言葉の97%。 くさび形よりも良い。
3. ファインリーダー 。
結果:
0010.png.fin.rtf
( オリジナル )
間違った単語:0(テキスト内の310単語)
間違った文字:5
書式エラー:文字の大文字化に関する問題。
結論:100%の言葉。 最良の結果。
0012.png
1. くさび形 。
0012.png.cun.rtf
( オリジナル )
前の結果とは異なり、より多くの「Y」およびローマ数字が表示されました。 一部の単語の認識は改善されましたが、同時に、新しいエラーと余分な文字が現れました。
結論:エラーは少なくありません。
2. Tesseract 。
0012.png.tes.txt
( オリジナル )
結論:状況はCuneiformと同じです:エラーが少なくありません。
3. ファインリーダー 。
0012.png.fin.rtf
( オリジナル )
結論:何も変わっていません。
0011.png
英語サンプルの場合のように、楔形文字とTesseractの両方が認識品質の低下を示しました。 例を挙げません(自分で確認できます)。
サンプルNo. 5の結論 :200 dpiを超える品質の画像を使用しても、結果が改善されないことが確認されました。
Finereaderが1位、Tesseractが2位、Cuneiformが3位になります(そして、Wineの方がうまく機能します)。
200dpi。
0010.png
1. くさび形 。
cuneiform -l ruseng -f rtf --singlecolumn -o 'OUTPUT' 'INPUT'
結果:
0010.png.cun.rtf
( オリジナル )
{kind=link}
不適切な単語:17(テキスト310の単語)
無効な文字:12
書式エラー:ダッシュ、段落記号、およびパーセンテージを認識しませんでした。 認識の問題「Y」。 誤って認識された斜体。
結論:言葉の95%。 よく見えません
CuneiformV12が認識するバージョン:
0010.cun.win.rtf
( オリジナル )
品質は明らかにネイティブバージョンよりも高くなっています。
2. Tesseract 。
tesseract 'INPUT' 'OUTPUT' -l rus -psm 6
結果:
0010.png.tes.txt
( オリジナル )
{kind=link}
間違った単語:8(テキストの310単語)
無効な文字:15
フォーマットエラー:「:」の認識に関する問題。
結論:言葉の97%。 くさび形よりも良い。
3. ファインリーダー 。
sudo abbyyocr9 -rl Russian English -if 'INPUT' -f RTF -of 'OUTPUT'
結果:
0010.png.fin.rtf
( オリジナル )
{kind=link}
間違った単語:0(テキスト内の310単語)
間違った文字:5
書式エラー:文字の大文字化に関する問題。
結論:100%の言葉。 最良の結果。
300dpi。
0012.png
1. くさび形 。
0012.png.cun.rtf
( オリジナル )
{kind=link}
前の結果とは異なり、より多くの「Y」およびローマ数字が表示されました。 一部の単語の認識は改善されましたが、同時に、新しいエラーと余分な文字が現れました。
結論:エラーは少なくありません。
2. Tesseract 。
0012.png.tes.txt
( オリジナル )
{kind=link}
結論:状況はCuneiformと同じです:エラーが少なくありません。
3. ファインリーダー 。
0012.png.fin.rtf
( オリジナル )
{kind=link}
結論:何も変わっていません。
600dpi。
0011.png
英語サンプルの場合のように、楔形文字とTesseractの両方が認識品質の低下を示しました。 例を挙げません(自分で確認できます)。
サンプルNo. 5の結論 :200 dpiを超える品質の画像を使用しても、結果が改善されないことが確認されました。
Finereaderが1位、Tesseractが2位、Cuneiformが3位になります(そして、Wineの方がうまく機能します)。
サンプルNo. 6(O'Henryの短編小説のスキャンされたページ)。
試験サンプルNo.6
0013.png
1. くさび形 。
0013.png.cun.rtf
( オリジナル )
間違った単語:28(テキスト316単語)
誤った文字:多く。
書式エラー:誤った斜体。
結論:単語の91%、多くの間違い、そのようなサンプルでは受け入れられない
CuneiformV12が認識するバージョン:
0013.cun.win.rtf
( オリジナル )
間違った単語:15(テキスト316単語)
誤った文字:複数。
フォーマットエラー:なし。
結論:単語の95%、結果はネイティブバージョンよりも優れています。
2. Tesseract 。
0013.png.tes.txt
( オリジナル )
不適切な単語:30(テキスト316単語)
誤った文字:多く。
書式エラー:余分な文字。
結論:言葉の90%が悪い。
3. ファインリーダー 。
0013.png.fin.rtf
( オリジナル )
間違った単語:3(テキスト316単語)
間違った文字:いいえ。
フォーマットエラー:なし。
結論:言葉の99%。
サンプルNo. 6の結論 :CuneiformとTesseractは、サンプルのフォントの文字「and」、「n」、および「p」に同じタイプの認識エラーがあることに気付きました。
最初の場所はFinereader、2番目はWineのCuneiform(ネイティブのCuneiformの方がうまく機能していません)、3番目はTesseractです。
200dpi。
0013.png
1. くさび形 。
0013.png.cun.rtf
( オリジナル )
{kind=link}
間違った単語:28(テキスト316単語)
誤った文字:多く。
書式エラー:誤った斜体。
結論:単語の91%、多くの間違い、そのようなサンプルでは受け入れられない
CuneiformV12が認識するバージョン:
0013.cun.win.rtf
( オリジナル )
間違った単語:15(テキスト316単語)
誤った文字:複数。
フォーマットエラー:なし。
結論:単語の95%、結果はネイティブバージョンよりも優れています。
2. Tesseract 。
0013.png.tes.txt
( オリジナル )
{kind=link}
不適切な単語:30(テキスト316単語)
誤った文字:多く。
書式エラー:余分な文字。
結論:言葉の90%が悪い。
3. ファインリーダー 。
0013.png.fin.rtf
( オリジナル )
{kind=link}
間違った単語:3(テキスト316単語)
間違った文字:いいえ。
フォーマットエラー:なし。
結論:言葉の99%。
サンプルNo. 6の結論 :CuneiformとTesseractは、サンプルのフォントの文字「and」、「n」、および「p」に同じタイプの認識エラーがあることに気付きました。
最初の場所はFinereader、2番目はWineのCuneiform(ネイティブのCuneiformの方がうまく機能していません)、3番目はTesseractです。
サンプルNo. 7(書籍「真実の瞬間」のスキャンされたページ)。
試験サンプルNo.7
0014.png
1. くさび形 。
0014.png.cun.rtf
( オリジナル )
間違った単語:11(テキスト323ワード)
誤った文字:永続的にハイフンとダッシュを認識しません。
書式エラー:誤った斜体。
結論:言葉の91%が悪い。
CuneiformV12が認識するバージョン:
0014.cun.win.rtf
( オリジナル )
間違った単語:1(テキスト323ワード)
無効な文字:1。
フォーマットエラー:なし。
結論:単語の99%、すばらしい。
2. Tesseract 。
0014.png.tes.txt
( オリジナル )
間違った単語:30パーセント。
誤った文字:多く。
書式エラー:余分な文字。
結論:嫌です。
3. ファインリーダー 。
0014.png.fin.rtf
( オリジナル )
間違った単語:0(テキスト323単語)
間違った文字:いいえ。
フォーマットエラー:なし。
結論:100%の言葉。 パーフェクト。
サンプルNo. 7による結論 :1位はFinereader、2位はCuneiform for Wine(ネイティブCuneiformは非常に悪い結果を出しました)、3位はTesseract(結果を修正することすら役に立たない)です。
200dpi。
0014.png
1. くさび形 。
0014.png.cun.rtf
( オリジナル )
{kind=link}
間違った単語:11(テキスト323ワード)
誤った文字:永続的にハイフンとダッシュを認識しません。
書式エラー:誤った斜体。
結論:言葉の91%が悪い。
CuneiformV12が認識するバージョン:
0014.cun.win.rtf
( オリジナル )
間違った単語:1(テキスト323ワード)
無効な文字:1。
フォーマットエラー:なし。
結論:単語の99%、すばらしい。
2. Tesseract 。
0014.png.tes.txt
( オリジナル )
{kind=link}
間違った単語:30パーセント。
誤った文字:多く。
書式エラー:余分な文字。
結論:嫌です。
3. ファインリーダー 。
0014.png.fin.rtf
( オリジナル )
{kind=link}
間違った単語:0(テキスト323単語)
間違った文字:いいえ。
フォーマットエラー:なし。
結論:100%の言葉。 パーフェクト。
サンプルNo. 7による結論 :1位はFinereader、2位はCuneiform for Wine(ネイティブCuneiformは非常に悪い結果を出しました)、3位はTesseract(結果を修正することすら役に立たない)です。
サンプルNo. 8(異なるフォントのパングラム)。
試験サンプルNo.8
最後に、最後のテストでは、OCRのフォントへの依存性が明らかになります(オリジナルは中品質のインクジェットプリンターで印刷されます)。
この例では、わかりやすくするために、必要に応じて段落とフォント名を修正します。
0015.png
1. くさび形 。
ロシア語のテキスト:
0015_rus.png.cun.txt
( オリジナル )
エラー(残念なハイフンを除く)がなければ、ArialとTrebuchet MSのみが認識されます。
英語のテキスト:
0015_eng.png.cun.txt
( オリジナル )
Courier NewおよびISOCPEURのみのエラー。
CuneiformV12 :
ロシア語のテキスト:
0015_rus.wine.cun.txt
( オリジナル )
Sans-serif、Arial、Courier New、DejaVu Sans、DejaVu Serif、Palladio Uralic、Trebuchet MS、Verdanaはエラーなしで認識されました。
移植された楔形文字と比較した違いは明らかです。
英語のテキスト:
0015_eng.wine.cun.txt
( オリジナル )
突然、ネイティブバージョンの3倍のエラーが発生します。
2. Tesseract 。
ロシア語のテキスト:
0015_rus.png.tes.txt
( オリジナル )
エラー(ハイフンの問題は別として)は、Palladio Uralic、Verdana、およびISOCPEURでのみ発生します。
英語のテキスト:
0015_eng.png.tes.txt
( オリジナル )
エラーはありません。
モデル8の結論 :ロシア語では、CuneiformV12(Wineの下)とTesseractが最もよく機能しました。 Tesseractは英語をエラーなく処理しました。
この例では、わかりやすくするために、必要に応じて段落とフォント名を修正します。
200dpi。
0015.png
1. くさび形 。
ロシア語のテキスト:
0015_rus.png.cun.txt
( オリジナル )
{kind=link}
エラー(残念なハイフンを除く)がなければ、ArialとTrebuchet MSのみが認識されます。
英語のテキスト:
0015_eng.png.cun.txt
( オリジナル )
{kind=link}
Courier NewおよびISOCPEURのみのエラー。
CuneiformV12 :
ロシア語のテキスト:
0015_rus.wine.cun.txt
( オリジナル )
Sans-serif、Arial、Courier New、DejaVu Sans、DejaVu Serif、Palladio Uralic、Trebuchet MS、Verdanaはエラーなしで認識されました。
移植された楔形文字と比較した違いは明らかです。
英語のテキスト:
0015_eng.wine.cun.txt
( オリジナル )
突然、ネイティブバージョンの3倍のエラーが発生します。
2. Tesseract 。
ロシア語のテキスト:
0015_rus.png.tes.txt
( オリジナル )
{kind=link}
エラー(ハイフンの問題は別として)は、Palladio Uralic、Verdana、およびISOCPEURでのみ発生します。
英語のテキスト:
0015_eng.png.tes.txt
( オリジナル )
{kind=link}
エラーはありません。
モデル8の結論 :ロシア語では、CuneiformV12(Wineの下)とTesseractが最もよく機能しました。 Tesseractは英語をエラーなく処理しました。
Linux用のGUI。
* GUI-グラフィカルユーザーインターフェイス-グラフィカルインターフェイス(「ウィンドウとボタン」)。
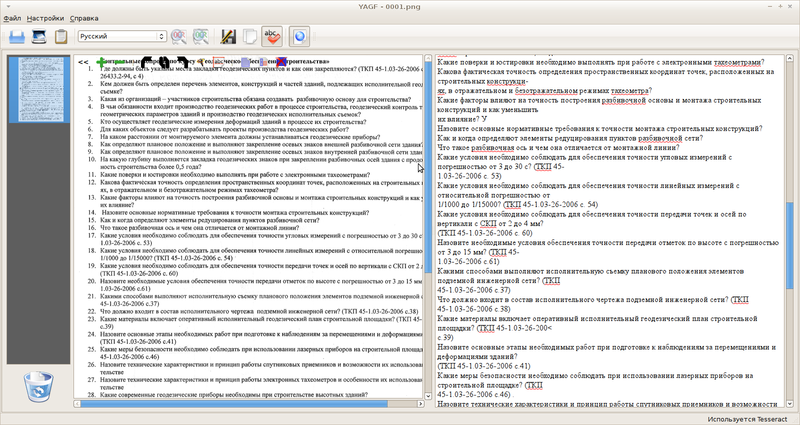
ヤグフ
公式ページ。
ビルドの依存関係: libaspell-devおよびlibqt4-devはバージョン4.5以上。 実行するには、 Qt 4.5とaspellが必要です(ソースに付属のドキュメントを参照)。
インストール(ソースディレクトリで開始):
mkdir builddir cd build dir cmake ../ make sudo checkinstall
Yagfは十分にローカライズされており、クリップボード、ファイル、スキャナーから画像を受け取り、pdfをインポートして、画像の位置合わせを行うことができます。
Yagf設定では、TesseractとCuneiformを切り替えることができます。 Yagfは、バッチ認識(インポートされたすべての画像)または特定のテキスト領域の認識を生成できます。
唯一の重大な欠点は、スキャンエンジンに追加のパラメーターを設定できないことです。 コマンドラインに似ています(以下で説明するOCRFeederにはこの欠点はありません)。
楔形文字
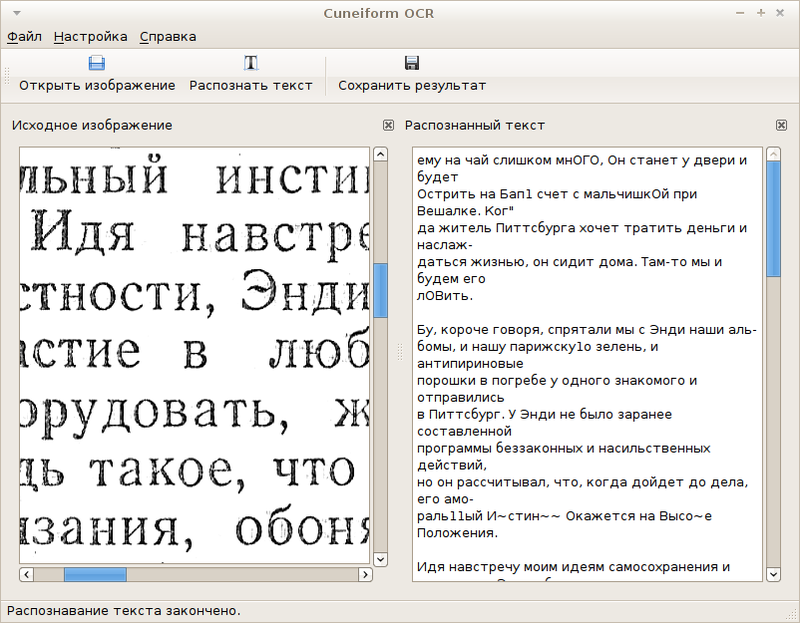
このプロジェクトは、 Altlinuxプロジェクトの一環として、2009年4月にアクティブライフを開始および終了しました。 Cuneiform-Qtは、Cuneiform用のシンプルなGUIを提供します。
このGUIから特別なものを期待していなかったため、 既製のパッケージバージョン0.1.1-1(ソースコード0.1.2の最新バージョン-開発ははるかに進んだ)のインストールに限定することにしました。
ところで、GUIは非常に興味深いことが判明しました。RTFに保存すると、認識されたテキストは1文字の幅の列に何百回も繰り返されるラテン文字のシーケンスに変わりました。 通常のテキストファイルへの保存は正常です。
結論:このGUIは役に立たない。
KBookOCR
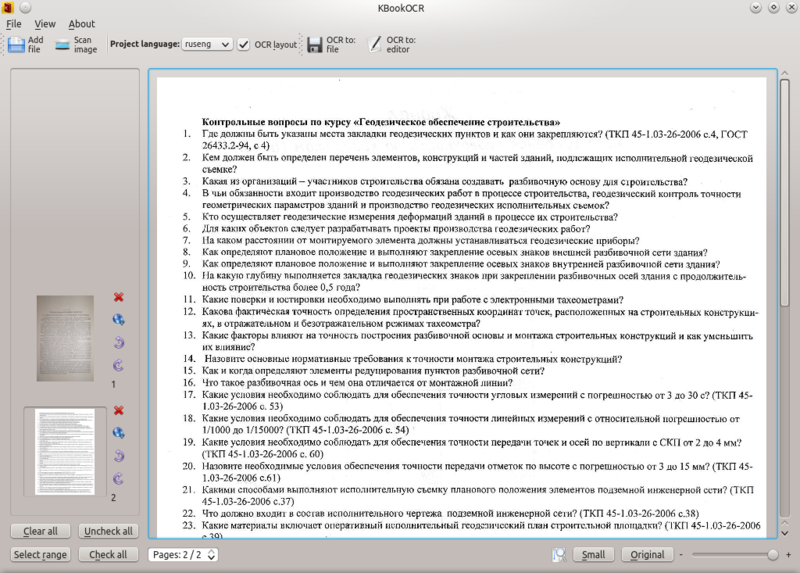
これはハブで発表された「Finereader killer」であり、Cuneiformのアドオンです。
著者の公式ブログ。
Deb-.
, KDE. 2.2 Tesseract, .
Kubuntu 12.04 Virtualbox.
2.1 , html . KBookOcr, Yagf, .
: KBookOcr Yagf KDE.
OCRFeeder

GUI Cuneiform, Tesseract OCR, . deb- , .
: Readme 0.3, – 0.7.1. , setup.py . ./confugure
:
sudo apt-get install python-pygoocanvas ocrad unpaper python-gtkspell python-enchant sane python-imaging-sane
, :
Your intltool is too old. You need intltool 0.35.0 or later.
intltool-debian : intltool 0.41.
収集するもの:
./confugure make sudo checkinstall
: /, / . : unpaper, ( , ); .
Ocropus
http://code.google.com/p/ocropus/ — GUI, CLI Tesseract.
, , python - :
SyntaxError: invalid syntax
, , , .
gImageReader

GUI Tesseract.
deb- .
gImageReader : , .
Tesseract-gui
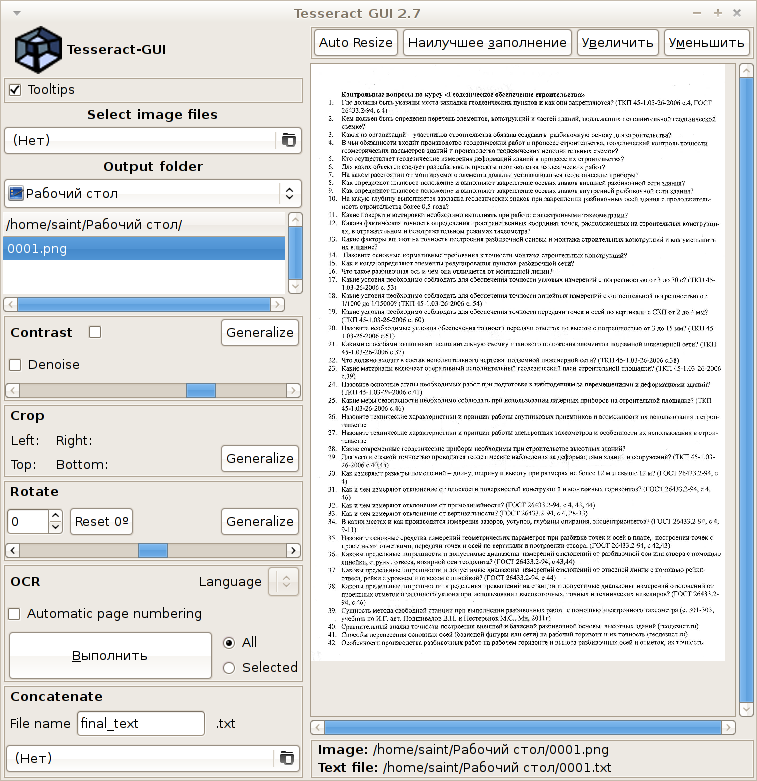
.
.
- .
GUI :
GUI ( ).
, GUI OCR Linux . , : Yagf OCRFeeder. , Yagf .
.
online-OCR
online-OCR .
Online OCR , , , : Cuneiform , Tesseract Finereader .
OCR , , .
1. Finereader Online .
finereader.abbyyonline.com/ru
Finereader Engine 9 (, , 10?) , .
10 .
2. New OCR .
www.newocr.com
, .
, Cuneiform Tesseract . , , .
№3, 5
Cuneiform :
0006.cun.newocr.txt
( )
Tesseract :
0006.tes.newocr.txt
( )
- .
№7
Cuneiform :
0014.cun.newocr.txt
( )
, 2 . .
Tesseract :
0014.tes.newocr.txt
( )
6 , — Tesseract . , .
OCR: () ( - ). OCR Finereader'.
おわりに
OCR, .
, FineReader Engine v9.0. , . , 149€ 12000 — ?
OCR: Cuneiform Tesseract — .
, — , , OCR «» .
CuneiformV12, Wine, , Linux.
, 200 dpi — .
GUI Cuneiform Tesseract , .
FineReader - New OCR , OCR , .
( New OCR ).
— OCR ABBYY — GUI.
: OCR , Finereader — -.
OCR — : .
PS — . .