そして全体的な理由は、WindowsではノートブックがWindows 1251のエンコーディングを使用し、OS XではデフォルトでMACCYRILLICが使用されるためです。 さらに、両方のプログラムはUTF-8エンコーディングで問題なく動作します。
あるエンコーディングから別のエンコーディングに変換するのは不便で、端末を開いてiconvコマンドを大事にしています...
考え直して、私は小さなスクリプトを作成しました。それは、使用されるエンコーディングを決定し、すべてのtxtファイルをUTF-8に変換します。
私がすべてに使用するもの:
Python 2.7
Mac OS X 10.7.5
Pycharm IDE
最初は、追加のモジュールなしで、自分でエンコード定義を作成しました。 しかし、 ad3wのアドバイスにより、 エンコードを決定するために既製のchardetモジュールを使用して書き直すことにしました。
誰が気に、前
恐ろしいコード
定義は、エンコーディングの単純な列挙と、余分な文字が含まれないものの選択です。 そして、文字セットを定義します。 もちろん、この方法はDOSグラフィックを含むファイルには適していませんが、txtを使用する通常の目的には十分です。
#!/usr/bin/python # -*- coding: utf-8 -*- __author__ = 'virtustilus' import os import sys # automatic=False # appdata={'enc':'','curfile':''} # toconvert=[] # r=[] if len(sys.argv)>1: r=sys.argv[1:] automatic=True else: i=raw_input(u'INPUT PATH:') r+=[i] def print1(s): """ , """ if not automatic: print s # utfrustring=u'' utfrustring+=u'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz' utfrustring+=u'1234567890-=—+_}{][\\"|;:\'/?><.,`~§±!@#$%^&*()№ \r\n « » \u0009 \u2013 \u201c \u201d' def checkline(s,encoding=''): """ """ hist='' b=True for i in range(0,len(s)): c=s[i] try: if not c in utfrustring: #: UTF-8 , if encoding==u'UTF-8': hist+= c + u' ' + str(hex(ord(c))) + u' at ' + str(i) + u' in: ' + s + '\n' b=False break except: if encoding==u'UTF-8': hist+=u'error encoding \n' b=False break return (b,hist) def check_all_lines(lines, encoding=''): """ """ foundenc=appdata['enc'] if foundenc: return foundenc if encoding=='': foundenc=u'UNICODE' else: foundenc=encoding x=lines[:] for j in x: if encoding!='': try: j=unicode(j,encoding) except: foundenc='' break cl=checkline(j,encoding) if not cl[0]: if cl[1]!='': print1(u'Error in:'+appdata['curfile']) print1(cl[1]) foundenc='' break appdata['enc']=foundenc # , , if len(r)==1 and os.path.isdir(r[0]): a=r[0] r[:]=[] for i in os.walk(a): p=i[2] for j in p: if j.endswith('.txt'): r+=[i[0]+'/'+j] if len(r)>0: for i in r: i=unicode(i,u'UTF-8') # , UNICODE txt UNICODE: u'.txt' if i.endswith(u'.txt'): f=file(i,'r') lines=f.readlines() f.close() appdata['curfile']=i # check_all_lines(lines,'') check_all_lines(lines,u'MACCYRILLIC') check_all_lines(lines,u'CP866') check_all_lines(lines,u'CP1251') check_all_lines(lines,u'KOI8R') check_all_lines(lines,u'CP10007') check_all_lines(lines,u'UTF-8-MAC') check_all_lines(lines,u'UTF-8') check_all_lines(lines,u'UTF-8-MAC') check_all_lines(lines,u'UTF-16') check_all_lines(lines,u'UTF-16BE') check_all_lines(lines,u'UTF-7') check_all_lines(lines,u'CP1252') check_all_lines(lines,u'KOI8-U') check_all_lines(lines,u'KOI8-RU') check_all_lines(lines,u'ISO-8859-5') if not appdata['enc']: toconvert.append((i,u'NOT FOUND ENCODING')) if appdata['enc'] and appdata['enc']!=u'UTF-8': toconvert.append((i,appdata['enc'])) else: print1(u'\nFile '+i+u' is not text file. \n\n') if toconvert: c=0 for i in toconvert: if i[1]!=u'NOT FOUND ENCODING': c+=1 if c>0: print1(u'\n\n FOUND FILES TO CONVERT: ') for i in toconvert: print1(i[0] + u' in encoding ' + i[1]) bt=True if not automatic: w=raw_input(u'Convert '+str(c)+u' files? (N)') bt= (w=='Y' or w=='y' or w=='' or w=='' or w=='' or w=='') if bt: for i in toconvert: if i[1]!=u'NOT FOUND ENCODING': f=file(i[0],'r') x=f.readlines() f.close() x=[ unicode(k,i[1]) for k in x ] x=[ k.encode(u'UTF-8') for k in x] f=file(i[0],'w') f.writelines(x) f.close() print1(u'FILE '+i[0]+u' CONVERTED SUCCESSFULLY :) ') else: print1(u'Bye!') else: print1(u'NO FILES TO CONVERT') for i in toconvert: print1(i[0] + u' in encoding ' + i[1]) else: print1(u' ALL ENCODING IS OK (UTF-8)!!! :)') else: print1(u'NO ONE TXT FILE')
chardet 1.1モジュールをダウンロードし、
開梱してインストール:
python setup.py install
ファイルをトランスコードするための独自のスクリプトを作成します。
前の版
#!/usr/bin/python # -*- coding: utf-8 -*- __author__ = 'virtustilus' import os import sys import chardet files=sys.argv[1:] # , if len(files)==0: files=[raw_input(u'INPUT PATH:')] # files_to_convert=[] for i in files: if os.path.exists(i): if os.path.isdir(i): for w in os.walk(i): for wfile in w[2]: if wfile.lower().endswith('.txt'): files_to_convert+=[w[0]+'/'+wfile] elif os.path.isfile(i): # , files_to_convert+=[i] if len(files_to_convert)>0: for i in files_to_convert: f=file(i,'r') text=''.join(f.readlines()) f.close() enc=chardet.detect(text).get('encoding') # (dropbox), if enc!='UTF-8': # try: text=text.decode(enc).encode('UTF-8') f=file(i,'w') f.write(text) f.close() except: pass
#!/usr/bin/python # -*- coding: utf-8 -*- __author__ = 'virtustilus' import os import sys import chardet def may_be_1251(text_not_changed, encoding): """ Win1251, chardet , MacCyrillic chardet , MacCyrillic: 1. ” Advanced- 2. ”€, ( .. ) 3. — mfc100u.dll € """ simbols = u'' simbols += u'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz' simbols += u'1234567890-=—+_}{][\\"|;:\'/?><.,`~§±!@#$%^&*()№ \r\n' if encoding.lower() == 'maccyrillic': err_mac = err_win = 0 try: t_win = text_not_changed.decode('cp1251') except: err_win += 1000000 try: t_mac = text_not_changed.decode('MacCyrillic') except: err_mac += 1000000 for i in t_win: if i not in simbols and i != u'\n': err_win += 1 for i in t_mac: if i not in simbols: err_mac += 1 if err_mac > err_win: encoding = 'cp1251' return encoding paths = sys.argv[1:] # , if len(paths) == 0: paths = [raw_input(u'INPUT PATH:')] # ( , .. " ") dirs = [i for i in paths if os.path.exists(i) and os.path.isdir(i)] files = [i for i in paths if os.path.exists(i) and os.path.isfile(i)] # for i_dir in dirs: for wpath, wdirs, wfiles in os.walk(i_dir): files += [wpath + '/' + i for i in wfiles if i.lower().endswith('.txt')] for i in files: with open(i, 'r') as f: text = ''.join(f.readlines()) enc = may_be_1251(text, chardet.detect(text).get('encoding')) # (dropbox), if enc and enc.lower() != 'utf-8': # try: text = text.decode(enc) # OS X 10.8 \r text = text.replace(u'\r', '').encode('utf-8') # : , . , os.unlink(i) with open(i, 'w') as f: f.write(text) except: pass
次に、OS Xのフォルダーからこのスクリプトを直接実行できるようにする必要があります。
Automatorを開き、サービスを作成します。
上部でアイテムを選択して、「サービスはFinder.appのファイルとフォルダーを受信します」を取得します。
次に、アクション「get selected objects Finder」を設定します。
次に、設定「パス入力:引数として」の「シェルスクリプトを実行」とその内容:
for f in "$@" do python /___/convert_encoding.py "$f" 2>/dev/null done
chardetモジュールエラーが出力されたときにオートマトンが実行を停止しないように、2> / dev / nullを追加しました。
最後の項目は「Growl通知を表示する」です(変換が行われたことを書き込めます)。
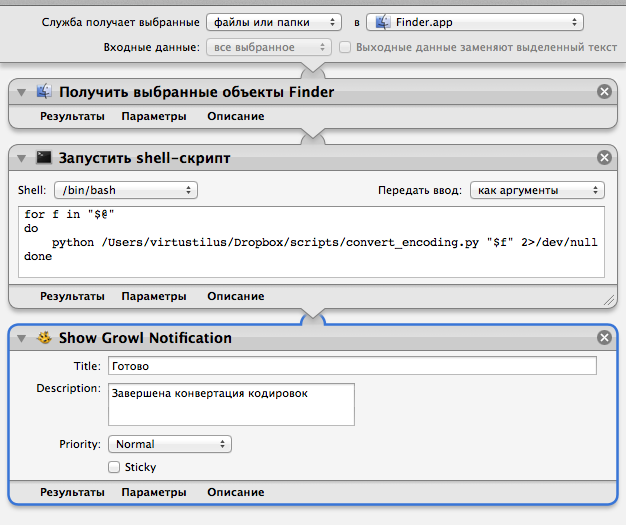
名前をラテン文字で保存し(ロシア語では、何らかの理由で、名前を変更するまでメニュー項目が表示されませんでした)、確認します。
Finderの[サービス]サブメニューのファイルとフォルダーメニューに新しいメニュー項目が表示されます。
PSこれは、コメントとその使用経験に基づいたスクリプトの第5版です。
PS私は問題を見つけました:pythonが書き込み先のファイルのエンコーディングを認識した場合、それはそこで動作します。 これは必要ないので、保存する前にファイルを削除します。